📝 Paper Summary
Software Vulnerability Analysis
LLM Prompt Engineering
VSP is a prompting strategy that guides LLMs to reason about vulnerabilities by explicitly mapping 'vulnerability semantics'—critical statements and their data/control flow context—into chain-of-thought steps.
Core Problem
Deep learning approaches for vulnerability analysis suffer from data scarcity and poor generalization, while standard LLM prompting fails because models get distracted by irrelevant code or lack structured reasoning.
Why it matters:
- Software vulnerabilities cause critical financial losses and data breaches, with over 22,000 reported in 2023 alone
- Existing DL tools perform poorly on real-world code (low recall/precision) due to lack of high-quality labeled datasets
- Purely static analysis suffers from high false alarms, while dynamic analysis is limited by input coverage
Concrete Example:
In a Use-After-Free scenario, a standard model might miss the vulnerability if it simply scans code line-by-line. VSP forces the model to first locate the pointer usage (line 8), then trace back the specific data flow (line 2) and control flow (line 6) that cause the error, ignoring irrelevant lines.
Key Novelty
Vulnerability-Semantics-guided Prompting (VSP)
- Redefines Chain-of-Thought for code by using 'vulnerability semantics'—the specific subset of code (vulnerable statements + relevant control/data dependencies) that accounts for the flaw
- Constructs few-shot exemplars where the 'reasoning' step explicitly isolates these semantic elements before outputting a verdict, preventing the LLM from processing the entire code block uniformly
Architecture
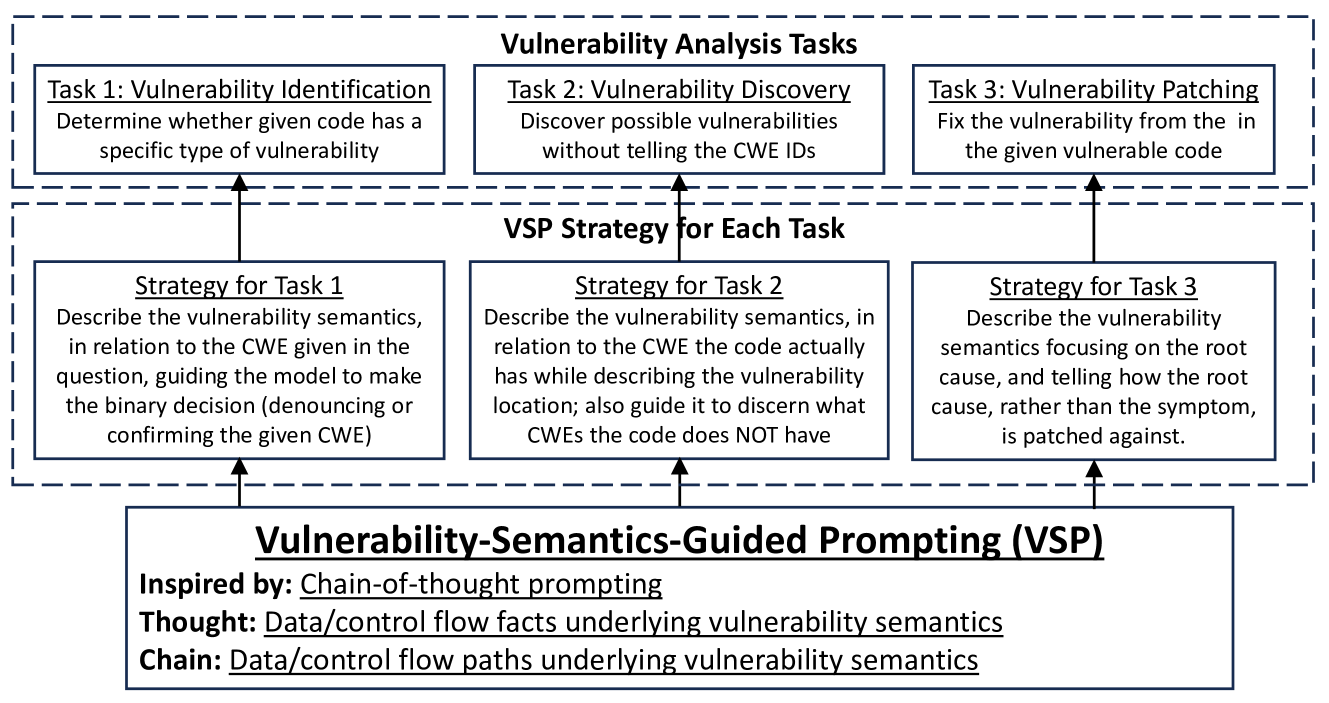
The unified workflow of VSP showing how vulnerability semantics guide the prompting for three different tasks
Evaluation Highlights
- +553.3% improvement in F1 accuracy for vulnerability identification on the real-world CVE dataset compared to the best baseline
- Found 22 true zero-day vulnerabilities in real-world software with 40.00% accuracy, compared to only 9 found by standard prompting
- Achieved 97.65% F1 on synthetic patching tasks and 20.00% on real-world patching, outperforming all non-CoT baselines
Breakthrough Assessment
8/10
Demonstrates a massive jump in performance on real-world datasets by specializing generic CoT for code semantics. The identification of 22 zero-days validates practical utility.
