📝 Paper Summary
Text-to-Image In-Context Learning (T2I-ICL)
Unified Multimodal LLMs (MLLMs)
Chain-of-Thought Reasoning
ImageGen-CoT improves Text-to-Image In-Context Learning by teaching MLLMs to generate explicit reasoning steps before image synthesis, supported by a novel dataset and hybrid test-time scaling.
Core Problem
Unified Multimodal LLMs struggle to infer implicit patterns from interleaved text-image examples in T2I-ICL tasks, often failing to grasp contextual relationships or preserve compositional consistency.
Why it matters:
- Current models fail to replicate human-like reasoning where concepts are learned from context (e.g., seeing 'leather book' -> 'leather apple' implies 'leather' style for new objects)
- Standard fine-tuning methods for subject customization are resource-intensive and lack rapid generalization capabilities
- Existing unified MLLMs produce disorganized thought processes when prompted zero-shot, leading to suboptimal image generation
Concrete Example:
Given context 'a leather-bound book' then 'a leather apple', when asked for 'a box', a standard model might generate a generic box. A human infers the 'leather' pattern to imagine 'a leather box'. Current MLLMs fail to make this implicit style transfer.
Key Novelty
ImageGen-CoT (Image Generation Chain-of-Thought)
- Introduce a dedicated reasoning step ('thought process') prior to image generation where the model explicitly articulates the style, subject, or relationship inferred from context
- Construct a high-quality dataset via an automated pipeline where an MLLM acts as Generator, Selector, Critic, and Refiner to create perfect reasoning-image pairs
- Deploy a 'Hybrid Scaling' strategy at inference time that first generates multiple reasoning chains (reasoning diversity) and then samples multiple images per chain (generation diversity)
Architecture
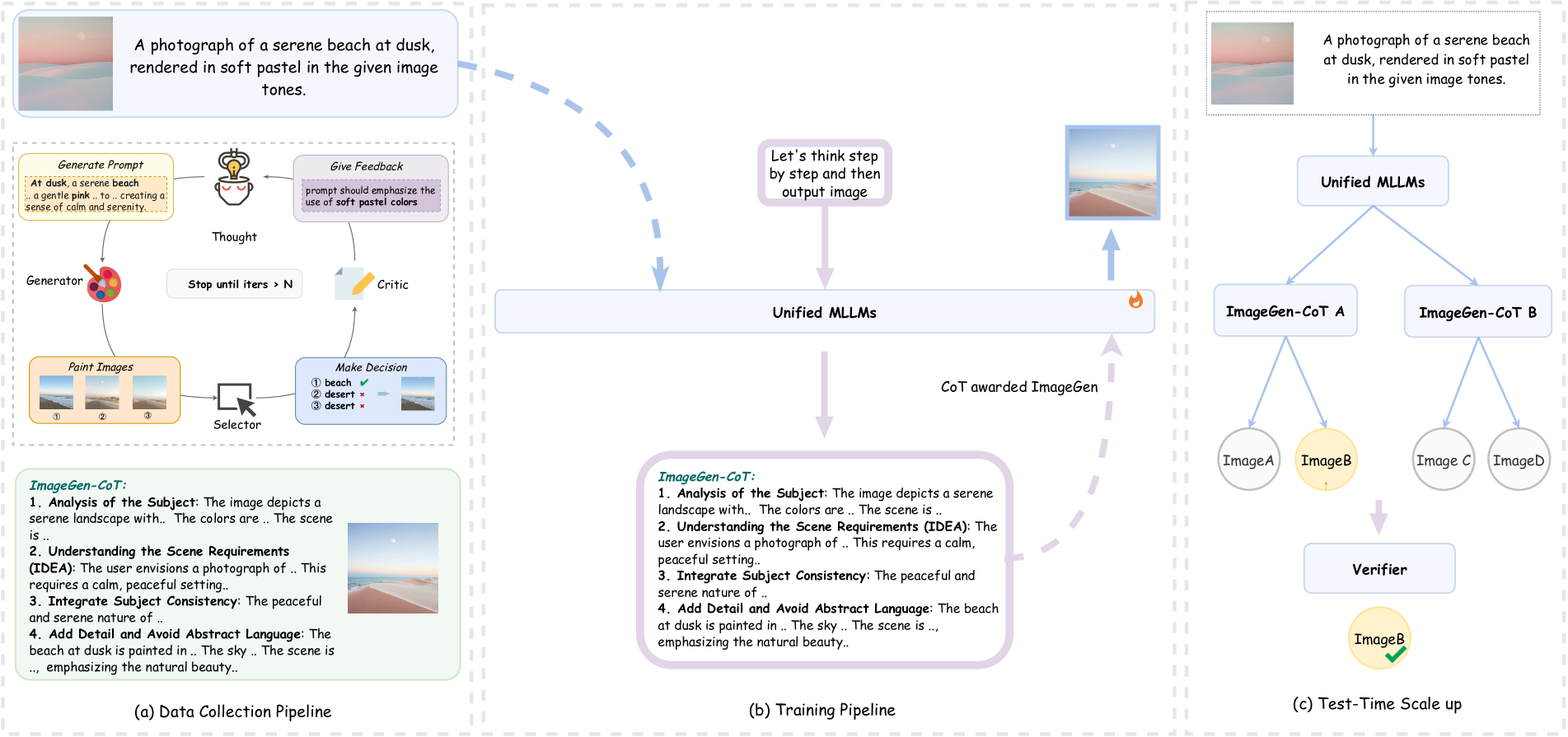
The automated data construction pipeline and the hybrid scaling strategy.
Evaluation Highlights
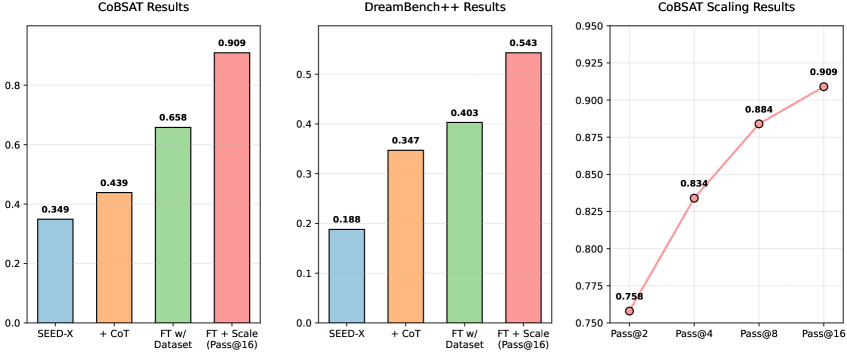
- SEED-X fine-tuned with ImageGen-CoT improves by 89% on CoBSAT and 114% on DreamBench++ benchmarks relative to base SEED-X
- Achieves a score of 0.909 on CoBSAT (up from 0.349 baseline) using the proposed hybrid scaling strategy
- Fine-tuning with the curated dataset outperforms simple prompting strategies, with SEED-X achieving 0.543 on DreamBench++ (vs 0.188 baseline)
Breakthrough Assessment
8/10
Significant performance jumps (80-114%) on established benchmarks. Successfully adapts NLP's Chain-of-Thought and test-time scaling paradigms to the multimodal generation domain.