📝 Paper Summary
Efficient LLM Inference
Chain-of-Thought (CoT) Optimization
Representation Engineering / Activation Steering
ASC compresses Chain-of-Thought reasoning by identifying a 'conciseness' direction in the model's activation space and steering generation toward it at inference time, using a theoretically grounded scaling factor.
Core Problem
Chain-of-Thought reasoning improves performance but often produces excessively verbose, repetitive, and computationally expensive rationales ('overthinking'), wasting context window and energy.
Why it matters:
- Longer CoTs significantly increase inference latency and energy consumption (quadratic scaling in transformers)
- Verbose reasoning often includes redundant self-verification and 'under-thinking' (switching paths without depth), which can degrade performance
- Retraining methods to shorten CoTs are expensive, while prompt engineering is unreliable for strict length control
Concrete Example:
For a math problem asking for a polynomial sum, a standard verbose CoT generates 603 tokens with conversational fillers ('Let's think step by step', 'Wait, let me double-check'). The proposed ASC method produces a sharp, 251-token math-centric derivation that is strictly focused on execution.
Key Novelty
Activation-Steered Compression (ASC)
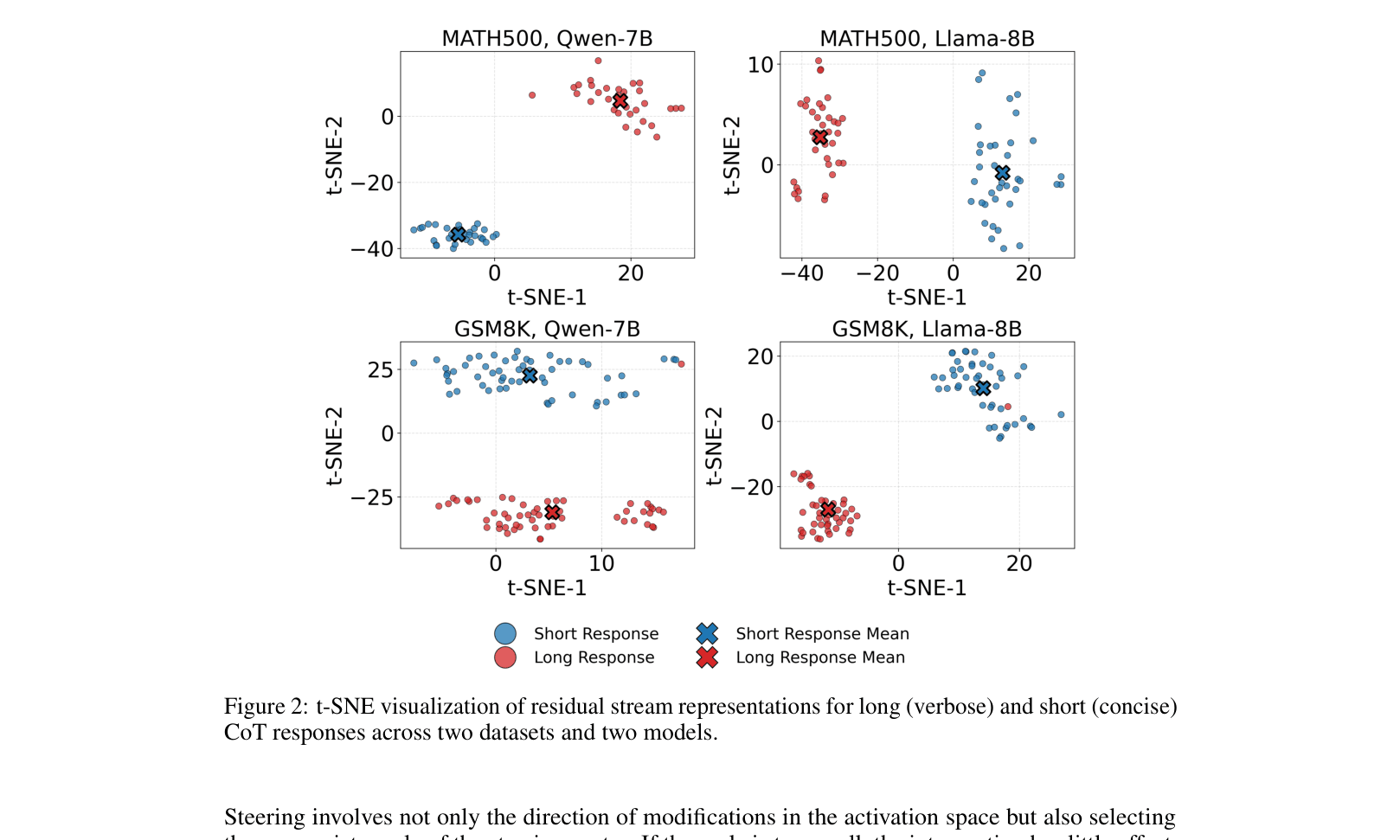
- Treats 'verbosity' vs. 'conciseness' as distinct regions in the model's residual stream activation space, separable via a linear steering vector
- Extracts this vector from a small set of 50 paired examples (verbose vs. concise) without any model training
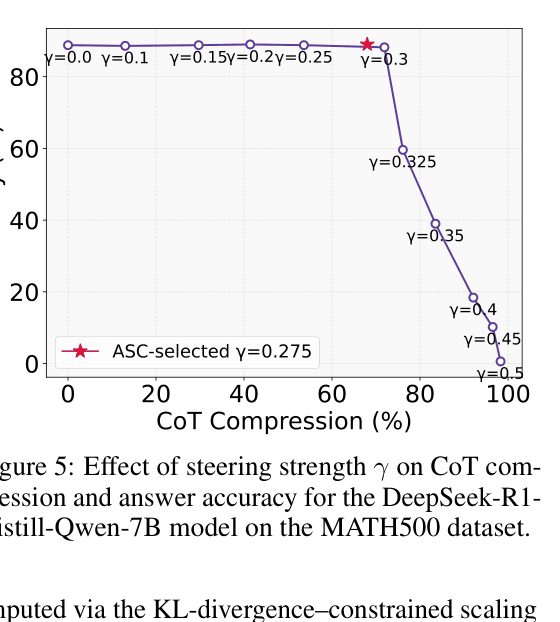
- Injects this vector during inference with a mathematically derived strength (γ) that strictly bounds the KL divergence of the output distribution to prevent degradation
Architecture
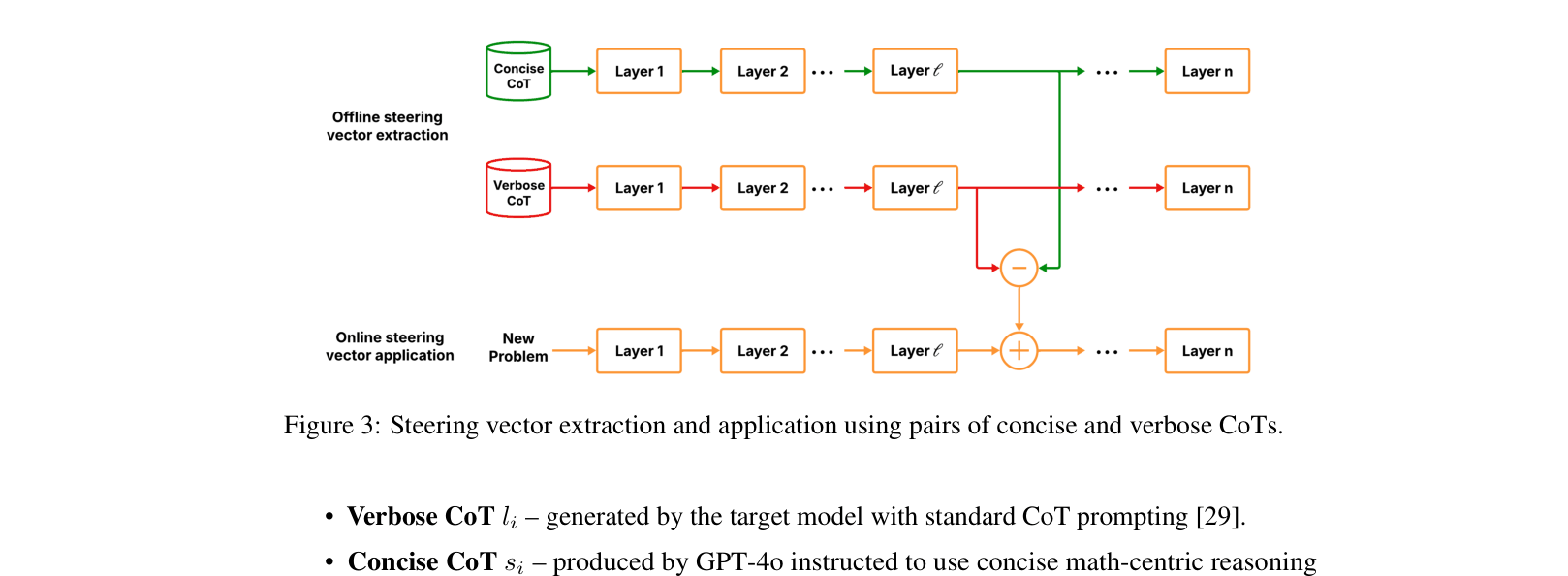
The process of extracting the steering vector from paired examples and applying it during inference
Evaluation Highlights
- Reduces CoT length by 67.43% on GSM8K with DeepSeek-R1-Distill-LLaMA-8B while slightly improving accuracy (+0.2%)
- Achieves 2.73x speedup in end-to-end reasoning wall-clock time on MATH500 using DeepSeek-R1-Distill-LLaMA-8B
- maintains 94.2% accuracy on MATH500 with QwQ-32B (vs 93.8% baseline) while using 50.7% fewer tokens
Breakthrough Assessment
8/10
Highly effective training-free compression with significant latency gains (>2x). The theoretical bound for steering strength addresses a major reliability issue in activation engineering.