📝 Paper Summary
Interpretability
Safety Guardrails
Efficient Inference
The paper demonstrates that internal representations of input tokens alone can preemptively predict eventual LM behaviors (like safety failures or formatting errors) before generation begins, enabling efficient early exits via conformal prediction.
Core Problem
Detecting LM misbehaviors (e.g., jailbreaks, formatting failures) typically requires generating the full output and checking it post-hoc, which is computationally expensive and unsafe.
Why it matters:
- Post-hoc detection wastes resources by generating toxic or incorrect tokens before discarding them
- Economic and environmental costs of inference grow with model scale and token count
- Safety risks arise if the model generates harmful content before a guardrail can intervene
Concrete Example:
When a user asks a malicious question (e.g., how to build a weapon), a standard LM generates a compliant response, and only after generation can a guardrail flag it. This wastes compute on the harmful output.
Key Novelty
Conformal Probing of Input Representations
- Trains linear classifiers (probes) on the internal activations of the *final input token* to predict properties of the *entire future output sequence* (e.g., will it fail to follow instructions?)
- Applies conformal prediction to these probes to guarantee that early warnings or exits only occur when the system is statistically confident, deferring to the base model otherwise
Architecture
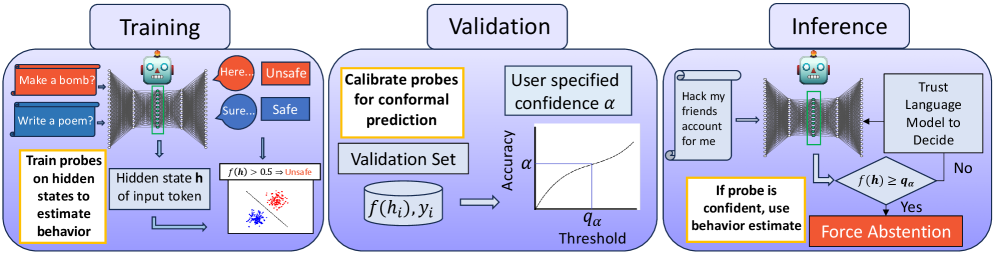
Conceptual diagram of the Conformal Probing Early Warning System.
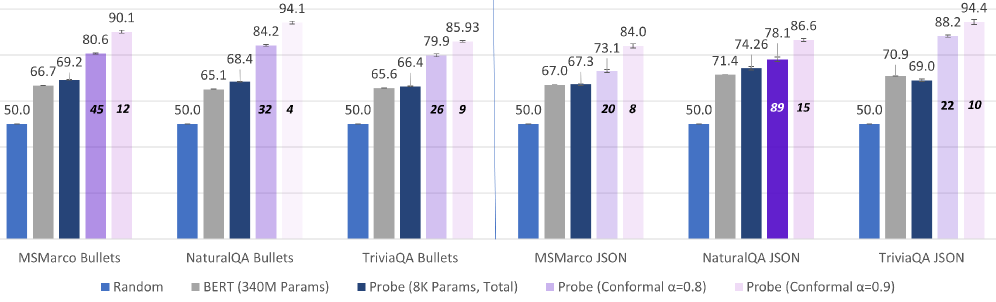
Evaluation Highlights
- Reduces successful jailbreak rate by 91% (from 30% to 2.7%) on WildJailbreak by preemptively detecting failures to abstain
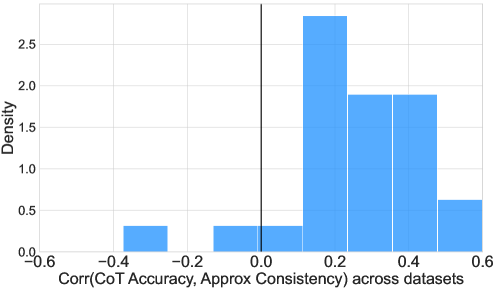
- Reduces inference costs for Chain-of-Thought classification by 65% on average across 27 datasets with negligible accuracy loss (<1.4%)
- Achieves >90% precision in detecting alignment failures (answering unanswerable questions) on SelfAware and KnownUnknown datasets
Breakthrough Assessment
8/10
Strong empirical evidence that input tokens encode future behavior, combined with a rigorous statistical framework (conformal prediction) to make it practical. Significant efficiency/safety gains.