📝 Paper Summary
Video understanding
Multimodal Large Language Models (MLLMs)
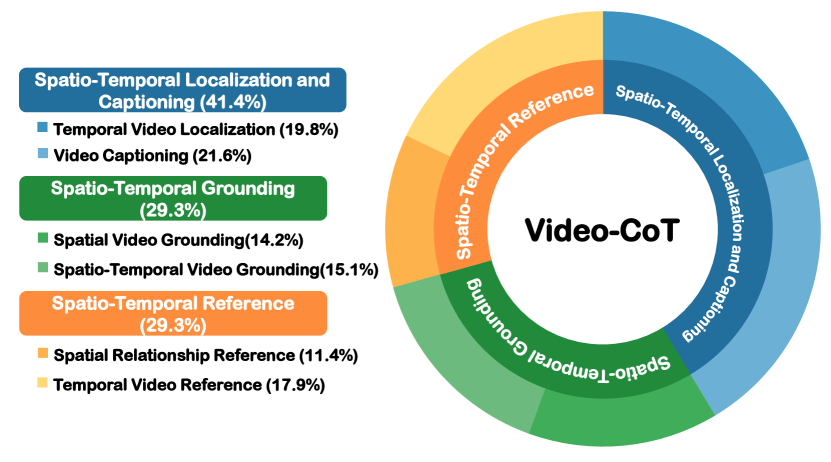
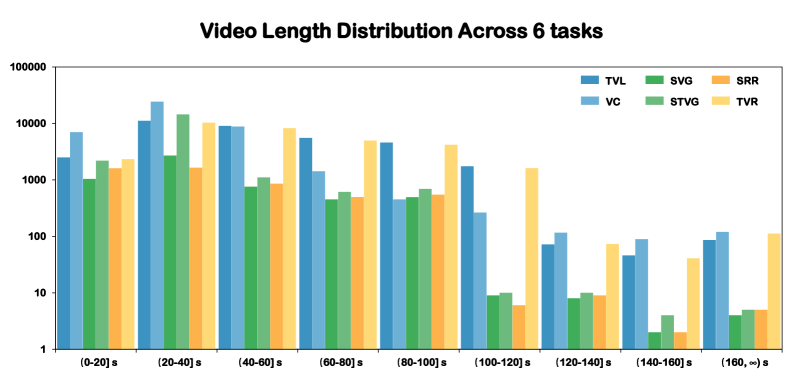
Video-CoT is a large-scale dataset of videos annotated with fine-grained spatiotemporal reasoning chains to train models that can better locate objects and events in both time and space.
Core Problem
Current Vision-Language Models (VLMs) struggle with fine-grained spatiotemporal reasoning because existing datasets focus on simple summarization or lack integrated spatial (where) and temporal (when) annotations.
Why it matters:
- Accurate video comprehension is essential for robotics and interactive systems, which need to know exactly when an event happens and where objects are located
- Existing datasets like Jester or FineGym isolate either spatial or temporal dimensions, preventing models from learning the complex interplay between object positions and event timing
- Current Chain-of-Thought (CoT) video data often overlooks precise start/end times and pixel coordinates, limiting its utility for grounded reasoning tasks
Concrete Example:
When asked 'When does the black SUV leave the adult in pink?', a standard model might just say 'a car drives away'. A model trained on Video-CoT can output the exact start/end timestamps and bounding boxes for the SUV and the adult throughout the event sequence.
Key Novelty
Video-CoT Dataset and CoT-SFT Strategy
- Constructs a dataset with 192,000 question-answer pairs and 23,000 Chain-of-Thought (CoT) samples that explicitly detail spatiotemporal reasoning steps (e.g., identifying objects -> tracking movement -> determining time)
- Proposes a Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) method that trains models to output intermediate reasoning steps (like 'First, locate the ball...') before the final answer, improving accuracy on complex queries
Architecture
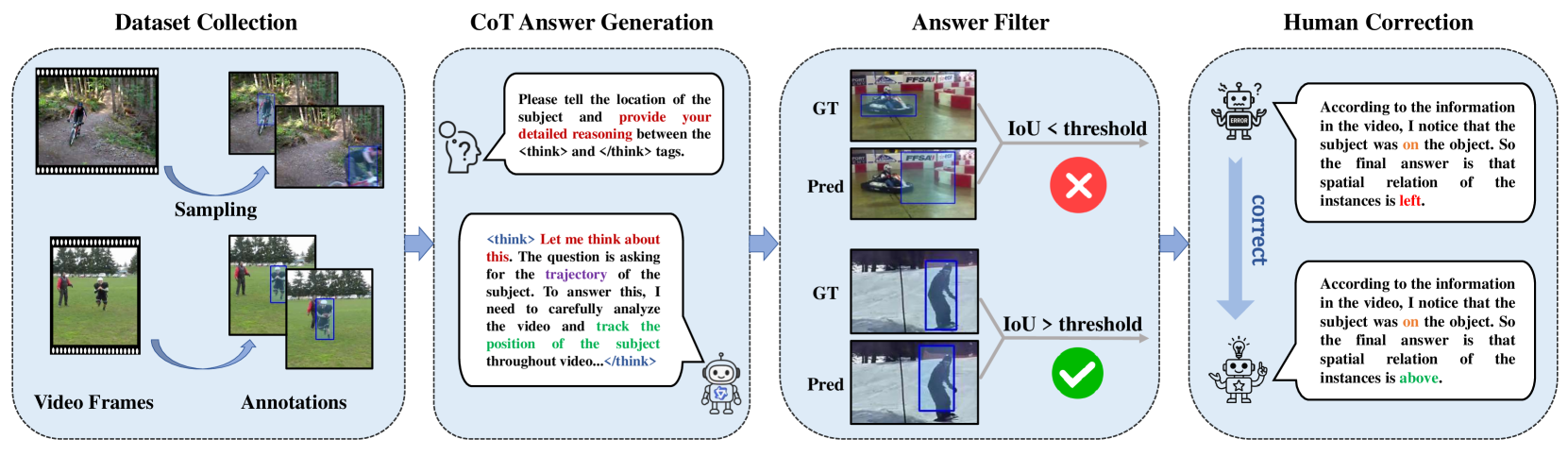
The pipeline for generating the Chain-of-Thought data. It shows how a large VLM (Qwen2.5-VL-72B) takes video and prompts to generate reasoning chains, which are then filtered for quality.
Evaluation Highlights
- +14.3 tIoU (temporal Intersection over Union) improvement on the Temporal Video Localization task using CoT-SFT compared to standard fine-tuning (Video-Ans-SFT)
- Video-CoT-SFT model (3B parameters) achieves 19.7 tIoU on localization, outperforming larger open-source 7B models like LLaVA-Video-7B (4.3 tIoU)
- Significant gains in temporal reasoning: +1.9 score increase on the Temporal Video Reference task using CoT-SFT compared to the baseline Qwen2.5-VL model
Breakthrough Assessment
8/10
Provides a much-needed resource for fine-grained video reasoning. The significant performance jump in temporal localization (from ~5 to ~19 tIoU) validates the importance of spatiotemporal CoT data.