📝 Paper Summary
Interpretability
Explainability
Chain-of-Thought Reasoning
Chain-of-Thought (CoT) reasoning is often unfaithful (post-hoc), with larger models frequently ignoring their stated reasoning, though faithfulness increases on difficult tasks like math.
Core Problem
It is unclear if the step-by-step reasoning generated by Large Language Models (LLMs) actually causes their final answer or if it is merely a post-hoc justification for a decision already made.
Why it matters:
- If CoT is unfaithful, users cannot rely on the model's explanation to verify the correctness or safety of high-stakes decisions (e.g., in medicine)
- Understanding whether reasoning is causal is essential for interpretability; currently, we do not know if CoT improves performance via actual reasoning or just extra test-time compute
Concrete Example:
A model answers a question about TV ownership. In its reasoning, it calculates '5! = 120'. However, if we truncate the reasoning text early, the model might still output '120', or if we inject a mistake '5! = 100', the model might ignore the mistake and still output '120', proving the reasoning text didn't cause the answer.
Key Novelty
Defense-in-Depth Faithfulness Testing Suite
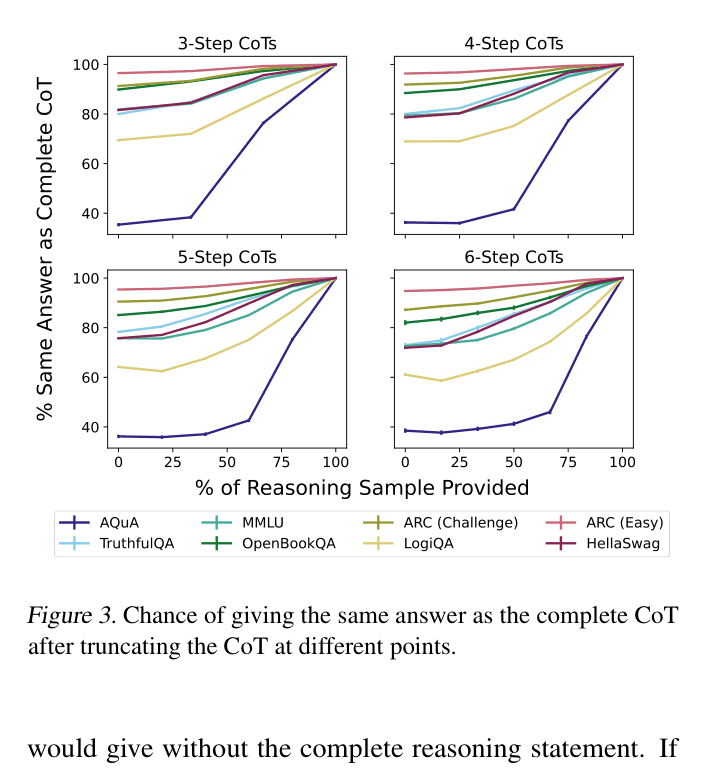
- Measure 'Early Answering': Truncate the reasoning chain at various steps to see if the model's final answer is already fixed before the reasoning is complete (indicating post-hoc rationalization)
- Measure 'Adding Mistakes': Inject errors into the reasoning chain; if the model's final answer doesn't change despite the error, the model is likely ignoring the reasoning content
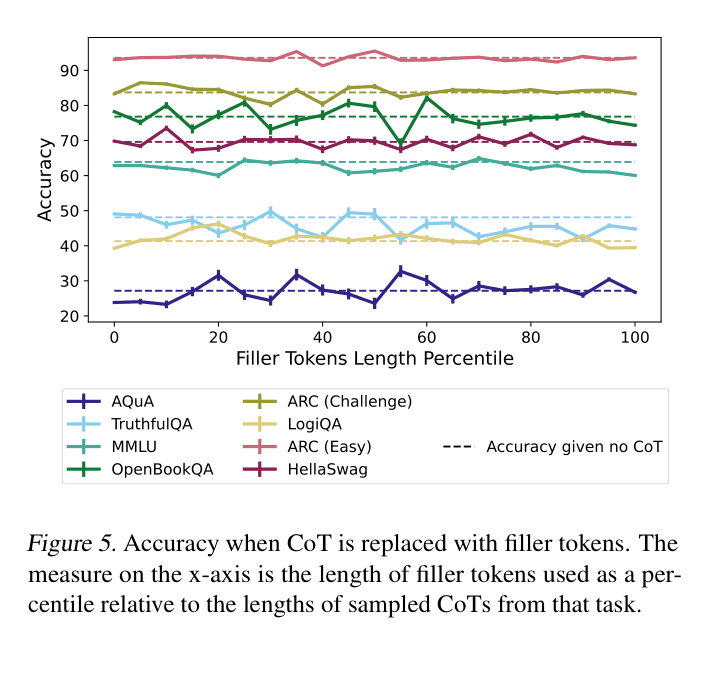
- Measure 'Filler Tokens': Replace reasoning with dots ('...') to test if performance gains come simply from extra computation time (context length) rather than semantic content
Architecture

An illustration of the four proposed tests for measuring faithfulness: Early Answering, Adding Mistakes, Paraphrasing, and Filler Tokens.
Evaluation Highlights
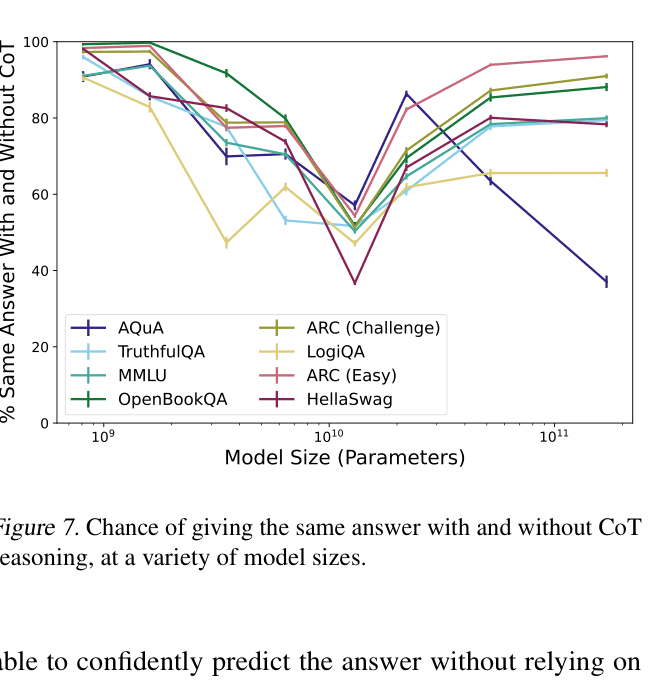
- On the ARC (Easy) task, models ignore their reasoning almost entirely: truncating the CoT changes the answer less than 10% of the time
- Inverse scaling observed: On 7 out of 8 tasks, a 13B model relies more on its reasoning (changes answer more when CoT is removed) than a 175B model does
- Replacing CoT with uninformative filler tokens ('...') yields 0% accuracy gain compared to standard CoT, ruling out test-time compute as the sole driver of performance
Breakthrough Assessment
7/10
Provides strong empirical evidence against the assumption that CoT is inherently faithful, introducing robust diagnostic tests. The finding of inverse scaling for faithfulness is particularly significant.