📝 Paper Summary
Chain-of-Thought (CoT) Analysis
Cognitive Modeling in AI
LLM Evaluation
Drawing on cognitive psychology, this paper identifies that tasks where verbal deliberation impairs human performance—such as implicit statistical learning and face recognition—systematically cause Chain-of-Thought to degrade LLM performance.
Core Problem
Chain-of-Thought (CoT) is widely applied as a default performance booster, but it systematically reduces accuracy in certain settings, and researchers lack heuristics to predict when these failures will occur.
Why it matters:
- Inference-time reasoning is becoming standard in frontier models (e.g., OpenAI o1), creating a risk of deploying models that perform worse than their predecessors on specific tasks
- Exhaustively testing the vast space of potential tasks to find CoT failure modes is intractable without guiding heuristics
- Current benchmarks prioritize symbolic reasoning where CoT excels, masking its detrimental effects on tasks requiring implicit or non-verbal processing
Concrete Example:
In an artificial grammar learning task, the reasoning-heavy model o1-preview achieves only 58.64% accuracy because it tries to verbally derive rules, while GPT-4o achieves 94.95% accuracy zero-shot by relying on implicit pattern matching.
Key Novelty
The Human-Overthinking Heuristic
- Proposes a heuristic based on cognitive psychology: if verbal deliberation ('overthinking') hurts human performance on a task, CoT will likely hurt LLM performance on that same task
- Adapts six classic psychological experiments (e.g., verbal overshadowing, rule-following with exceptions) into large-scale benchmarks to valididate this parallel
Architecture
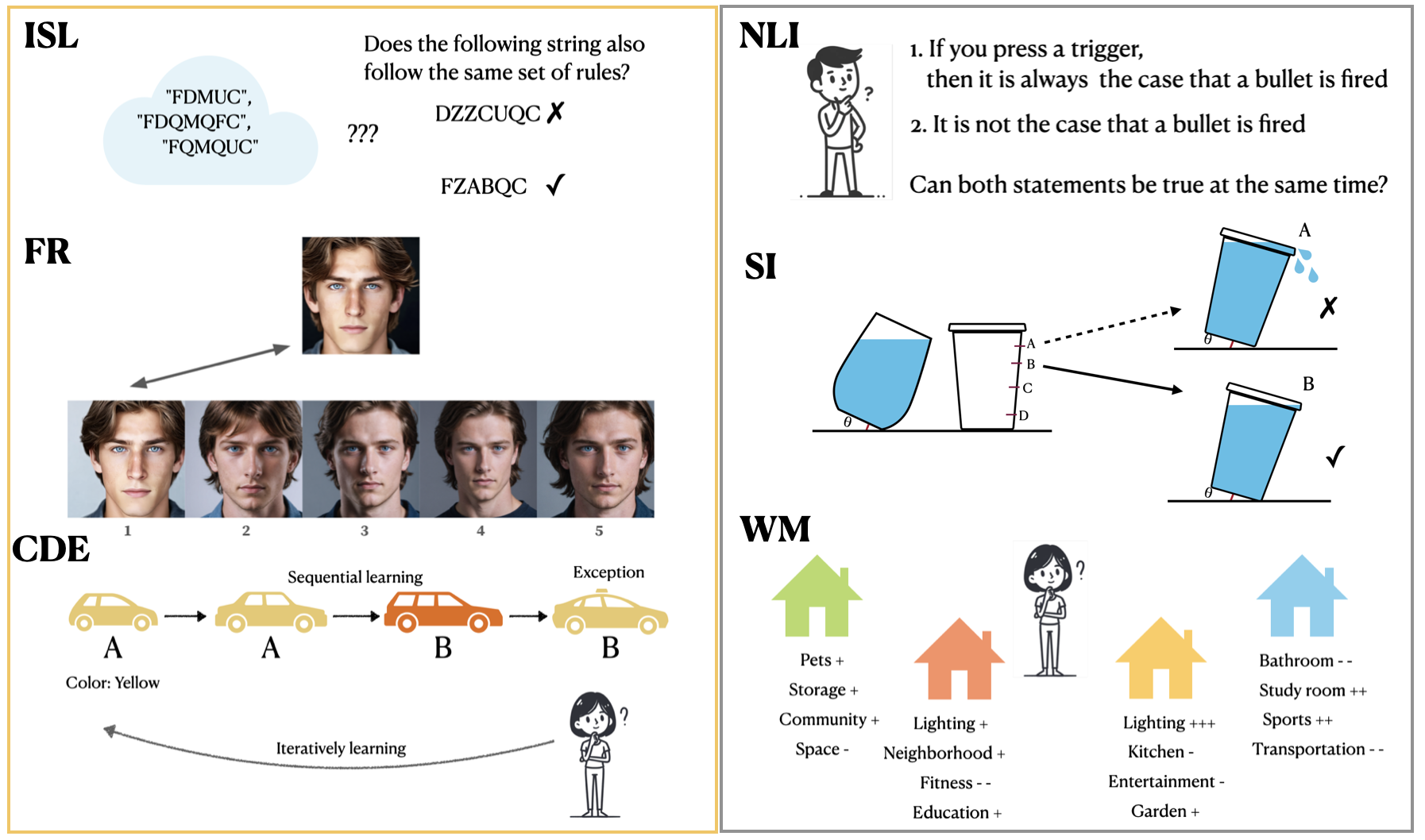
Conceptual diagram of the six task archetypes derived from psychology literature used to evaluate the impact of CoT
Evaluation Highlights
- -36.3% absolute accuracy drop for OpenAI o1-preview compared to GPT-4o zero-shot on the implicit statistical learning (artificial grammar) task
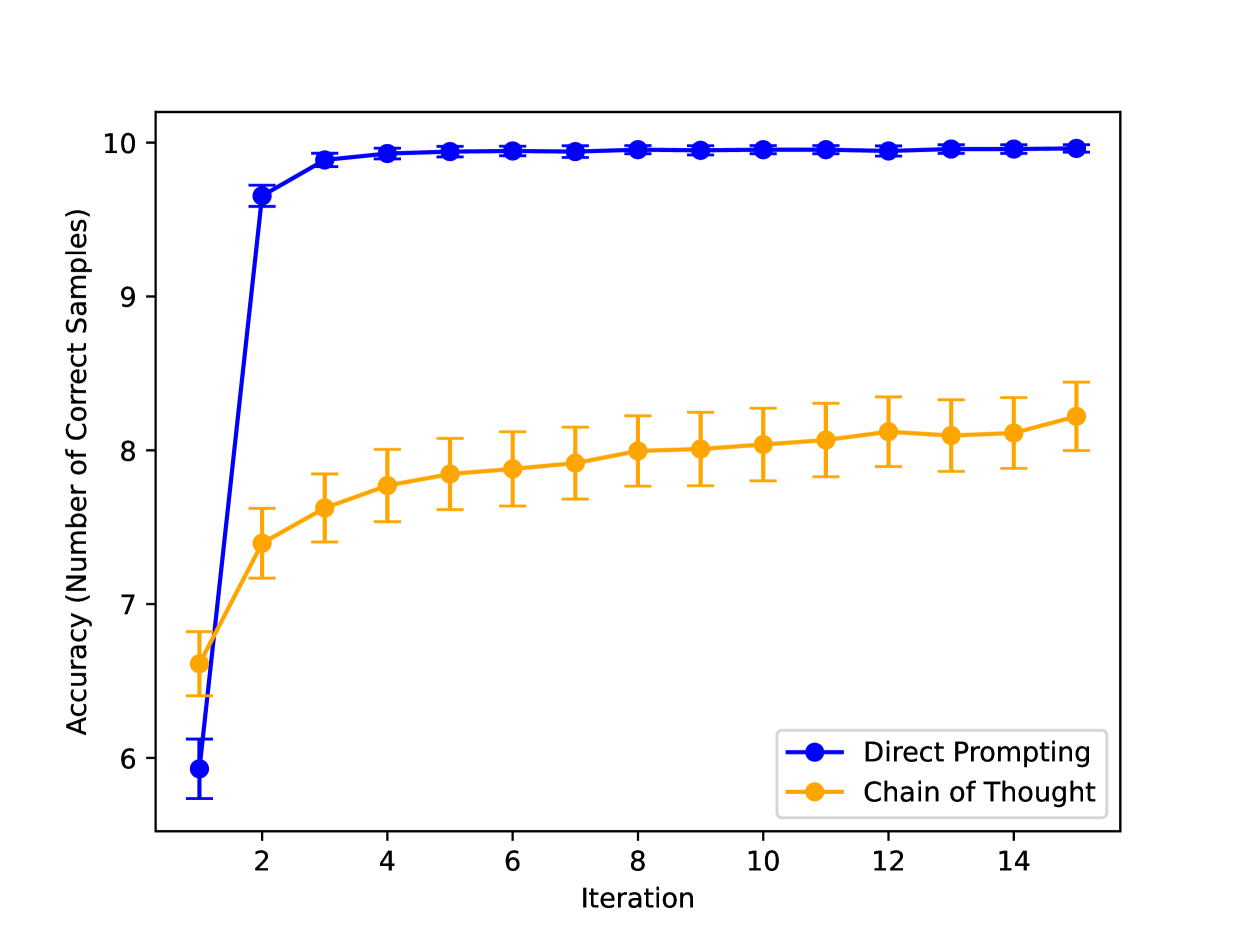
- CoT increases the number of training passes needed to learn rules with exceptions by up to 331% (from ~3 to ~13 passes) for GPT-4o compared to direct prompting
- CoT reduces face recognition accuracy across all six Vision-Language Models tested, often dropping performance to near random chance
Breakthrough Assessment
8/10
Provides a novel, scientifically grounded heuristic for predicting CoT failures, offering a crucial counter-narrative to the 'reasoning always helps' trend. The empirical results on o1-preview are particularly striking.