📝 Paper Summary
Chain of Thought (CoT) Faithfulness
Mechanistic Interpretability
Machine Unlearning
The paper introduces a framework that measures whether a model's reasoning is faithful by 'unlearning' specific reasoning steps from the model's parameters and observing if the prediction changes.
Core Problem
Current methods for evaluating Chain of Thought (CoT) faithfulness typically rely on context perturbations (removing text), which measure self-consistency rather than whether the model's parameters actually rely on that reasoning.
Why it matters:
- Models can produce plausible CoT reasoning that is actually post-hoc and disconnected from the true internal computation causing the answer
- Contextual perturbations are insufficient because models might recover the 'missing' information from their internal parameters, confounding faithfulness measurements
- Understanding the true causal link between reasoning and prediction is essential for building reliable and transparent AI systems
Concrete Example:
If a model answers 'Team A' because it reasoned 'Player X plays for Team A', removing that reasoning text from the prompt (contextual perturbation) might not change the answer if the model already 'knows' the fact in its weights. However, if we 'unlearn' that specific fact from the weights and the answer *does* change, we know the reasoning was parametrically faithful.
Key Novelty
Parametric Faithfulness Framework (pff) instantiated via Faithfulness by Unlearning Reasoning (fur)
- Shifts from context-based interventions (editing the prompt) to parameter-based interventions (editing the weights) to measure faithfulness
- Uses machine unlearning (NPO) to surgically erase the information contained in a generated reasoning step from the model
- If erasing the reasoning step from the parameters causes the model's prediction to flip, the reasoning step is deemed 'parametrically faithful'
Architecture
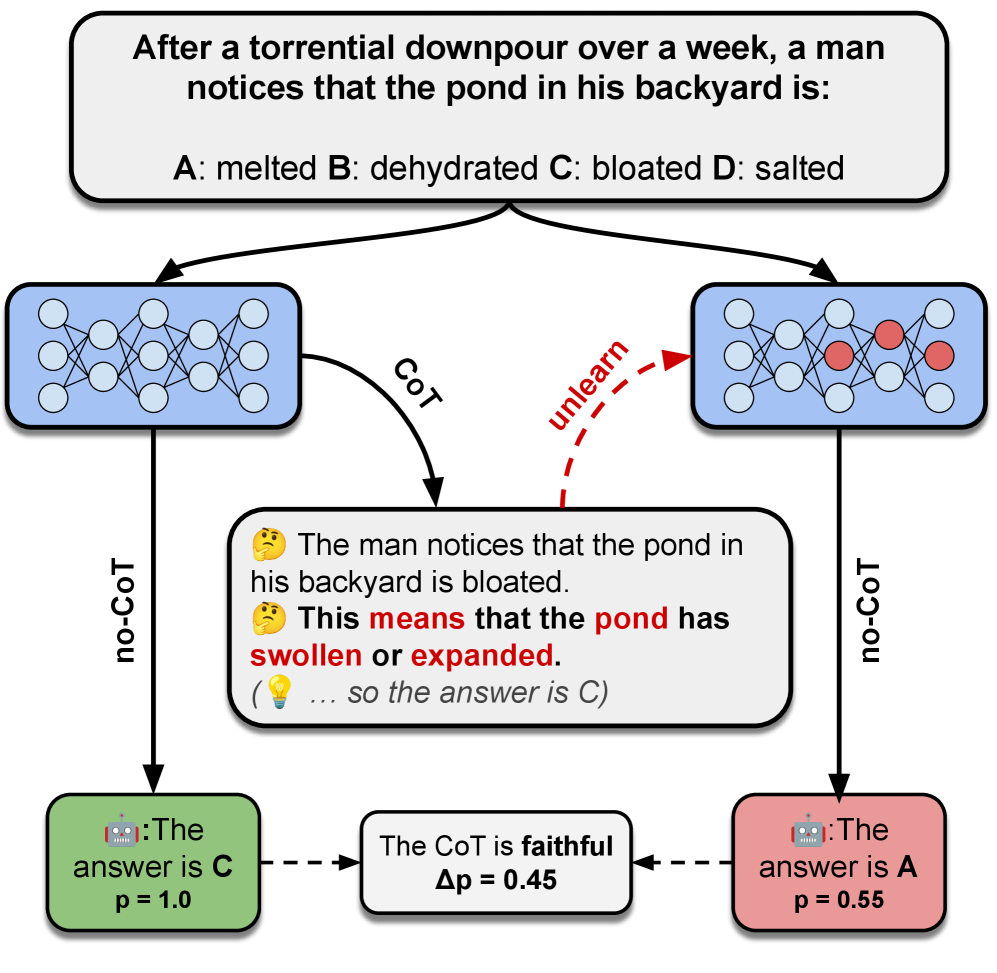
Conceptual diagram of the Parametric Faithfulness Framework (pff) and the specific 'fur' instance
Evaluation Highlights
- Demonstrates that unlearning specific reasoning steps frequently changes the model's prediction, confirming those steps were parametrically faithful
- Finding: Humans do not necessarily consider the steps identified as 'faithful' by this method to be 'plausible', indicating a gap between how models reason and how humans expect them to
- Finding: Unlearning a faithful step often leads the model to generate a new CoT supporting a completely different answer, hinting at a deep causal effect
Breakthrough Assessment
7/10
A novel methodological shift from input-level to parameter-level analysis for CoT faithfulness. While the 'unlearning' technique is standard, applying it to verify reasoning causality is a clever and stronger test than existing ablation methods.