📝 Paper Summary
Implicit Chain-of-Thought
Efficient Reasoning
Latent Space Reasoning
SIM-CoT stabilizes implicit reasoning by using a temporary auxiliary decoder during training to force latent states to encode specific reasoning steps, preventing representational collapse while maintaining inference efficiency.
Core Problem
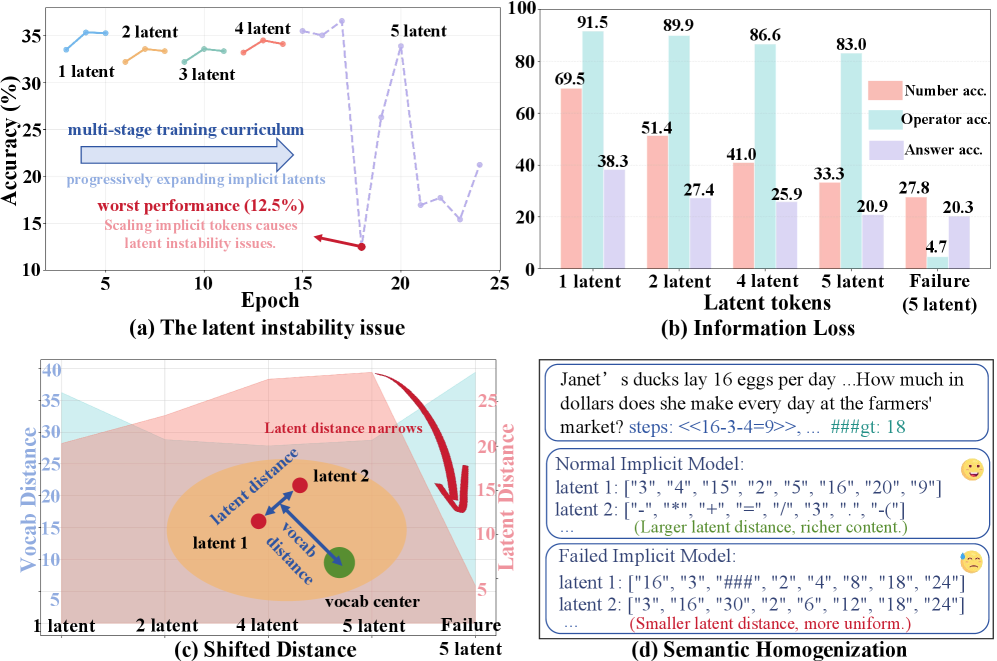
Implicit Chain-of-Thought methods (reasoning in latent space) suffer from instability when scaling the number of latent tokens; training often collapses as latents become homogeneous and lose semantic meaning.
Why it matters:
- Current implicit methods trade too much accuracy for efficiency, creating a performance gap preventing broad adoption
- Without stability, models cannot scale the computational budget (number of thinking steps) to solve harder problems, limiting their potential compared to explicit CoT
- Implicit reasoning is typically a 'black box', offering no interpretability for what the model is thinking
Concrete Example:
When scaling the method 'Coconut' from 3 to 5 latent tokens on GSM8k, accuracy drops drastically (from ~45% to 12.5%). Analysis shows the 5 latent tokens become nearly identical vectors representing only numbers, losing the operator information needed for calculation.
Key Novelty
Supervised Implicit Chain-of-Thought (SIM-CoT)
- Introduces an auxiliary decoder during training that takes an implicit latent vector and generates the corresponding explicit text reasoning step
- Provides step-level supervision to the latent space, forcing each latent vector to capture distinct, meaningful semantic information (grounding)
- Removes the auxiliary decoder during inference, retaining the token efficiency of implicit CoT with zero computational overhead
Architecture
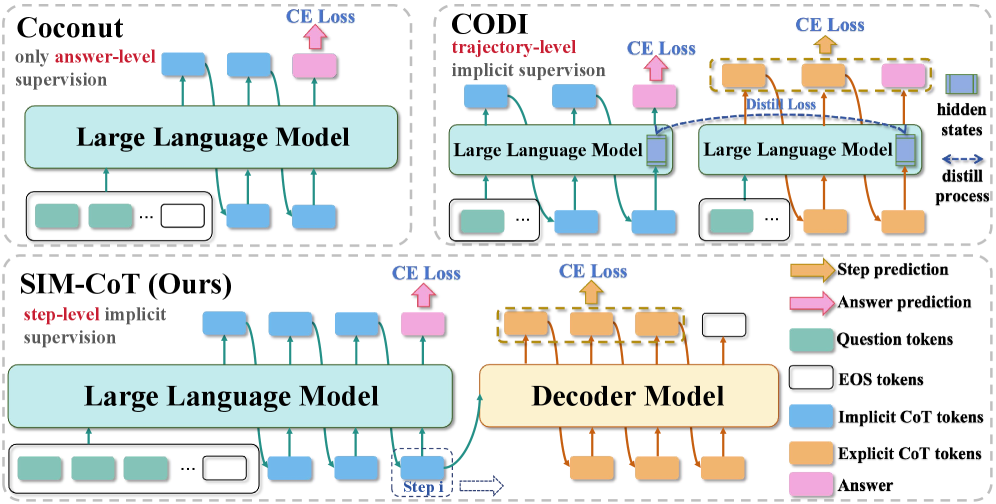
Comparison of training vs. inference workflows for Coconut, CODI, and SIM-CoT. Highlights SIM-CoT's use of an auxiliary decoder.
Evaluation Highlights
- +8.2% accuracy improvement over the implicit baseline Coconut on GSM8k-Aug using a GPT-2 backbone
- Surpasses explicit Chain-of-Thought (CoT-SFT) by 2.1% on GPT-2 while being 2.3x more token-efficient
- +3.0% improvement over the state-of-the-art implicit method CODI on LLaMA-3.1 8B
Breakthrough Assessment
8/10
Successfully addresses the critical stability collapse in implicit CoT, allowing it to finally surpass explicit CoT in accuracy while maintaining efficiency. Adds valuable interpretability to latent reasoning.