📝 Paper Summary
Chain-of-Thought (CoT) Compression
Efficient LLM Inference
Reasoning Models
This paper proposes identifying redundant reasoning steps using low step entropy and training models to autonomously skip them via a two-stage process combining supervised fine-tuning and reinforcement learning.
Core Problem
Chain-of-Thought reasoning generates verbose, redundant steps that increase computational cost and latency without adding informational value to the final answer.
Why it matters:
- Verbose reasoning paths increase inference latency and computational costs, creating bottlenecks for scalable deployment of large reasoning models
- Current compression methods (token pruning, latent reasoning) often lack a principled way to identify entire semantic steps that are superfluous vs. crucial
- Overthinking can paradoxically diminish efficiency without proportional accuracy gains
Concrete Example:
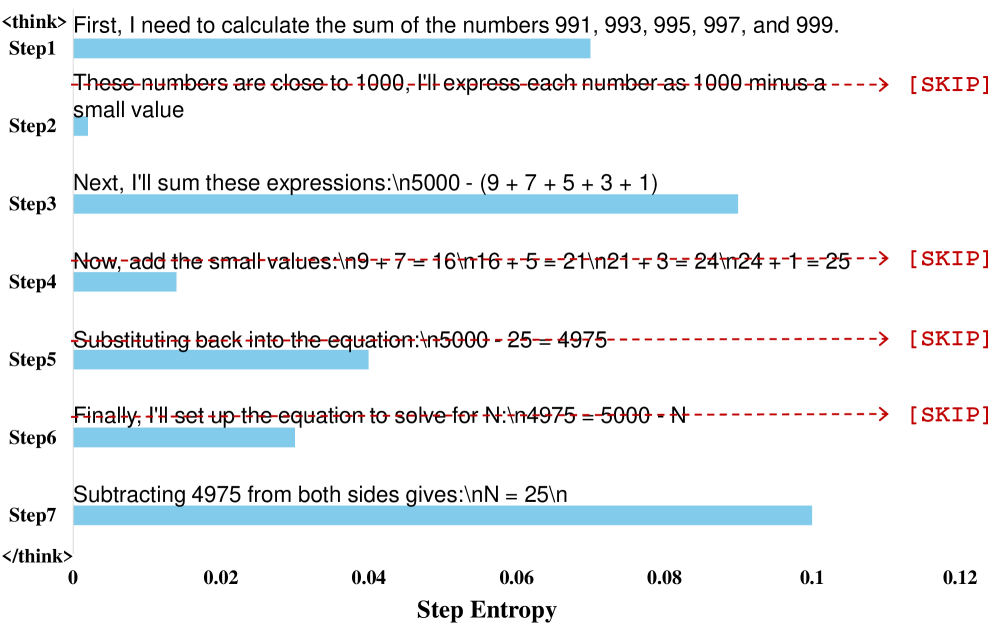
In a math problem, a model might generate deterministic, obvious intermediate algebraic manipulations that it is highly confident about (low entropy). Existing methods might keep these or prune random tokens, whereas this method identifies the entire low-entropy step as redundant and replaces it with a [SKIP] token.
Key Novelty
Step Entropy-based CoT Compression
- Introduces 'step entropy' to quantify the information content of a reasoning step; low entropy implies the step is predictable and redundant
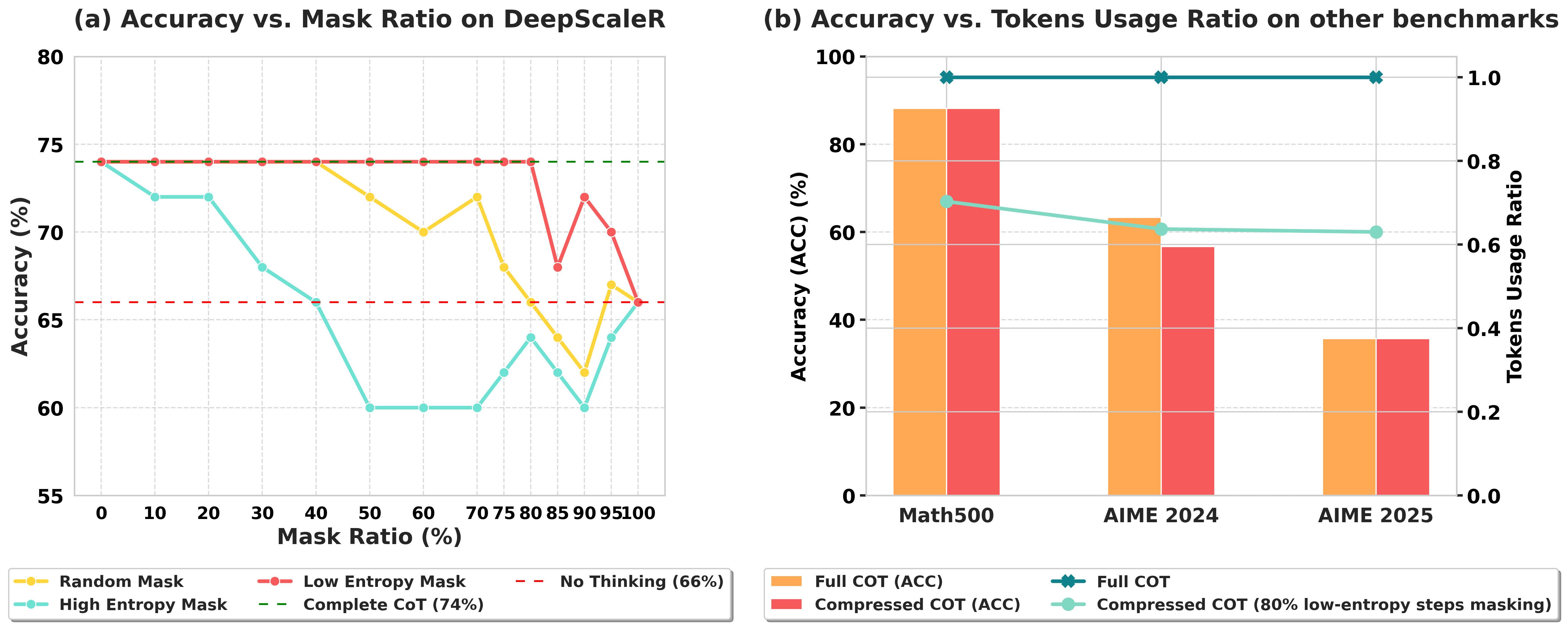
- Proposes a pruning strategy that removes up to 80% of low-entropy steps while maintaining accuracy, unlike random or high-entropy pruning
- Develops a two-stage training method (SFT + GRPO) where the model learns to autonomously output [SKIP] tokens for redundant steps
Architecture
The CoT compression pipeline. (a) Process of calculating step entropy and replacing low-entropy steps with [SKIP]. (b) Inference process where the model uses the compressed CoT context.
Evaluation Highlights
- Pruning 80% of low-entropy steps reduces tokens by 16-45% across benchmarks while maintaining accuracy on DeepSeek-R1-7B
- Trained models achieve 35-57% token reduction with autonomous compression while preserving or slightly improving accuracy
- Outperforms random pruning and high-entropy pruning, which cause immediate performance degradation even at low pruning rates
Breakthrough Assessment
8/10
Offers a theoretically grounded metric (step entropy) for redundancy and successfully trains models to autonomously skip steps, achieving significant efficiency gains without accuracy loss.