📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Chain-of-Thought Reasoning
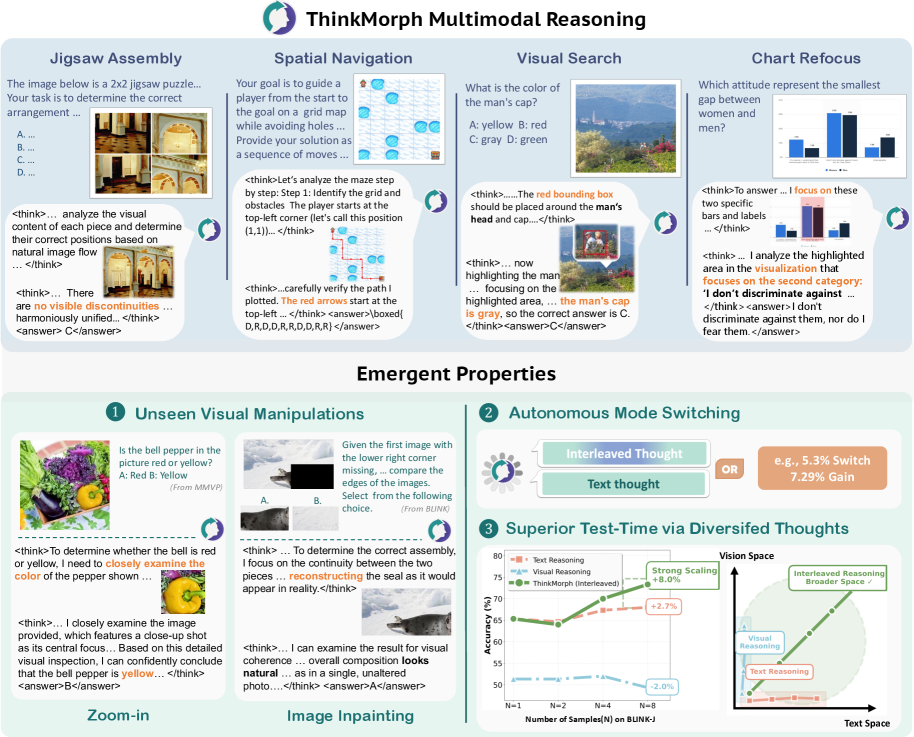
ThinkMorph improves multimodal reasoning by fine-tuning a unified model to generate interleaved text and image steps that are complementary rather than repetitive, enabling emergent behaviors like automatic zooming.
Core Problem
Current multimodal models struggle with complex visual reasoning because they treat text and images as isomorphic (redundantly describing each other) or rely on brittle external tools.
Why it matters:
- Vision-centric tasks like spatial navigation require manipulating visual elements, not just describing them
- Existing tool-augmented approaches are indirect and lack the seamless coordination of human 'think-and-sketch' strategies
- Unified models often fail to generalize because their training data does not enforce mutual advancement between modalities
Concrete Example:
In a spatial navigation task, a standard model might output text describing a path but fail to visualize the specific trajectory, leading to a hallucinated solution (0.83% success rate on VSP).
Key Novelty
Complementary Interleaved Reasoning
- Treats text and image thoughts as synergistic steps where each modality provides information the other cannot (e.g., text for logic, images for spatial precision)
- Fine-tunes a unified model on high-quality traces where visual tokens (boxes, paths, crops) actively advance the problem-solving state rather than just illustrating the text
Architecture
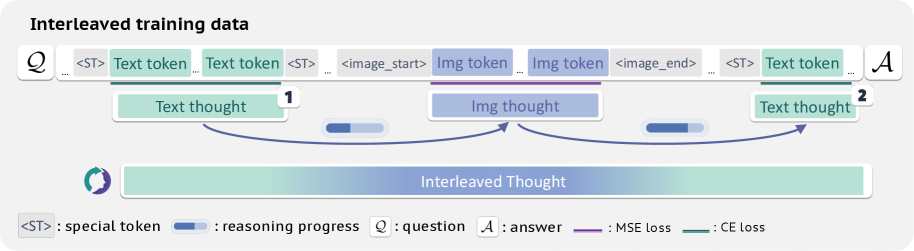
The dual-objective training framework and inference flow for ThinkMorph.
Evaluation Highlights
- +85.84% accuracy improvement on Spatial Navigation (VSP) compared to the base model (Bagel-7B)
- Surpasses InternVL3.5-38B on SAT spatial reasoning (52.67% vs. 49.33%) despite being a smaller 7B model
- Matches Gemini 2.5 Flash on MMVP perception benchmark with 80.33% accuracy
Breakthrough Assessment
8/10
Demonstrates significant gains and emergent behaviors (like autonomous mode switching) on hard vision-centric tasks using a unified architecture, though trained on a relatively small curated dataset.