📝 Paper Summary
Visual Chain-of-Thought (VCoT)
Multimodal Mathematical Reasoning
Diagram Generation and Editing
MathCanvas enables unified Large Multimodal Models to perform intrinsic visual reasoning by training them to generate and strategically interleave diagrammatic edits within their textual chain-of-thought.
Core Problem
Existing LMMs lack the ability to generate precise mathematical diagrams or strategically deciding when and how to use them, often producing flawed visuals that act as mere decoration rather than reasoning aids.
Why it matters:
- Geometry and function analysis intrinsically require visual aids for human-like problem solving; text-only reasoning is insufficient.
- Prior Visual CoT methods rely on rigid external tools (e.g., code interpreters) that lack flexibility, while intrinsic methods have failed to produce high-fidelity diagrams needed for complex deduction.
Concrete Example:
In a geometry problem requiring an auxiliary line, a baseline model (Nano-Banana) generates a visual that is a 'flawed decoration' failing to reveal the key insight. Another baseline (BAGEL-Zebra-CoT) draws a geometrically incorrect figure, rendering it useless for deduction.
Key Novelty
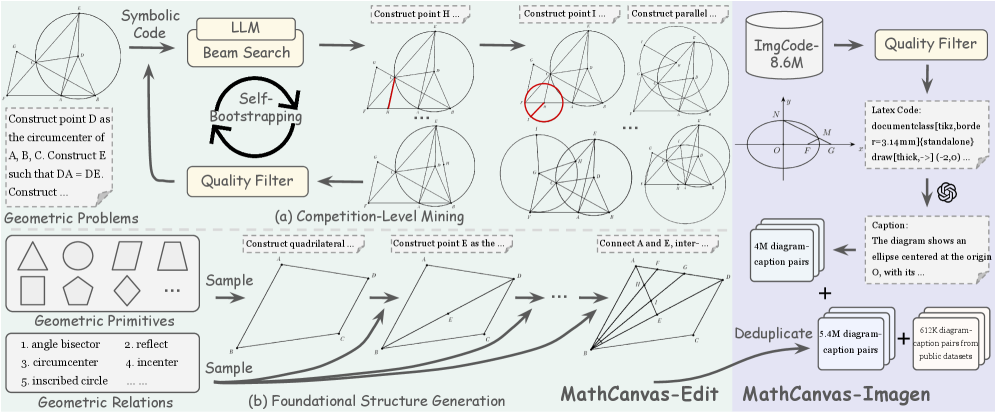
MathCanvas Framework (Visual Manipulation + Strategic Reasoning)
- Decouples training into two phases: first mastering the 'hand' (drawing/editing diagrams via MathCanvas-Edit/Imagen), then mastering the 'mind' (strategic interleaving via MathCanvas-Instruct).
- Treats visual aids as dynamic, editable reasoning steps rather than static final outputs, allowing the model to 'think' visually by iteratively refining diagrams.
Architecture
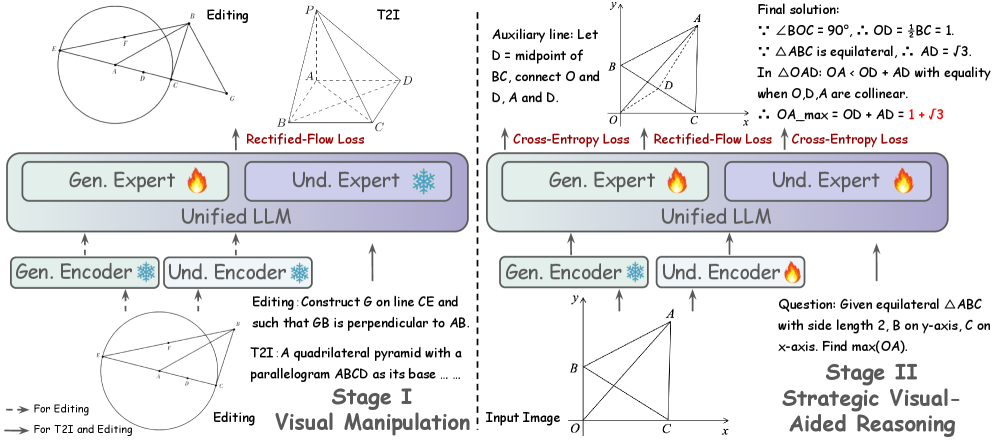
The two-stage training recipe for BAGEL-Canvas: Stage I for Visual Manipulation and Stage II for Strategic Visual-Aided Reasoning.
Evaluation Highlights
- Achieves an 86% relative improvement over strong LMM baselines on the proposed MathCanvas-Bench test set.
- Demonstrates generalization to other public math benchmarks (qualitative claim based on abstract).
Breakthrough Assessment
8/10
Proposes a comprehensive framework and massive datasets (15M+ pairs) that address a fundamental gap in multimodal reasoning—intrinsic diagram generation. The reported 86% relative improvement suggests a significant leap over existing tool-based or text-centric approaches.