📝 Paper Summary
Data Selection for Instruction Tuning
Interpretability of LLMs
Sparse Autoencoders (SAEs)
This paper uses Sparse Autoencoders to extract atomic features from instruction data, enabling a quantifiable diversity measure that guides effective data selection for fine-tuning language models.
Core Problem
Instruction tuning datasets are saturated with quantity, making selection crucial, yet existing methods often ignore diversity or rely on flawed metrics like sentence embeddings which fail to capture atomic semantic features.
Why it matters:
- Training on massive, redundant datasets is computationally expensive and inefficient
- Existing diversity metrics (e.g., cosine similarity of embeddings) are often too coarse to capture fine-grained semantic distinctions
- Recent industry calls (e.g., Llama-3 reports) highlight the need for quantifiable diversity measures rather than just claims
Concrete Example:
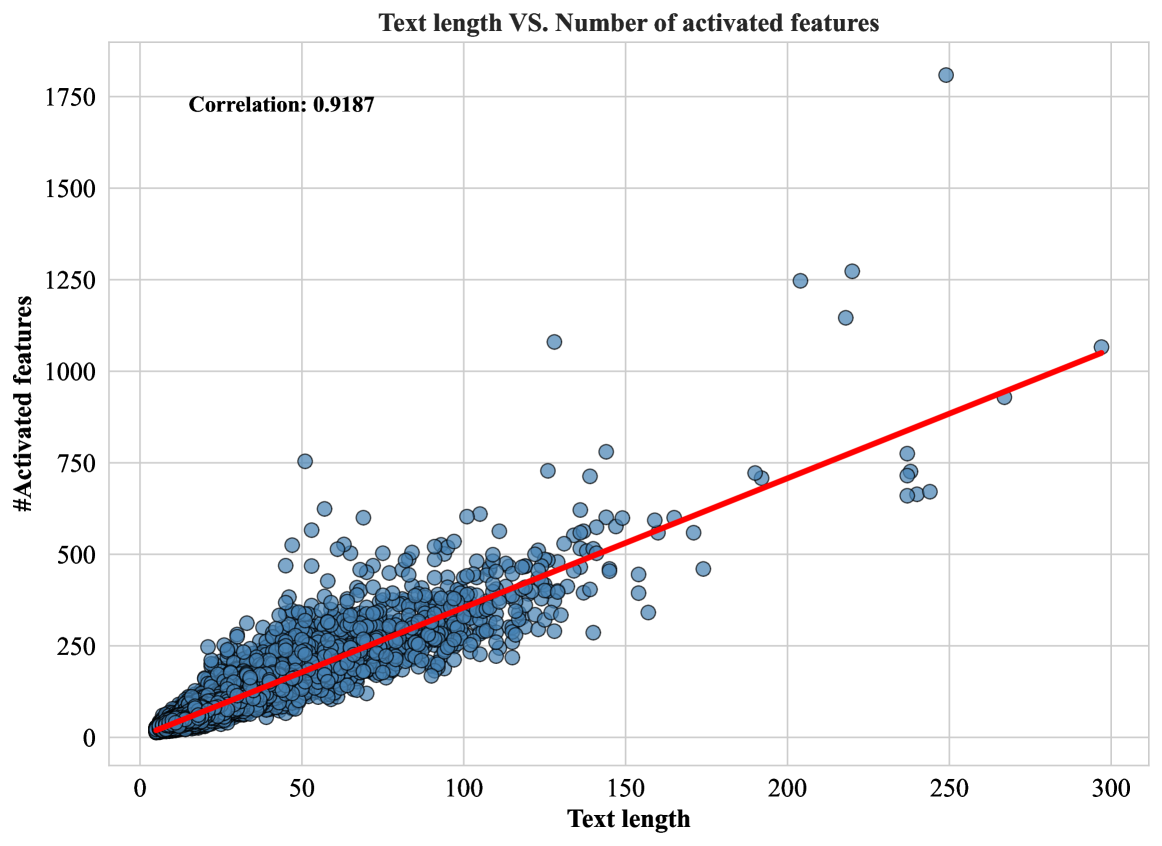
A data selection method might group distinct instructions together because their overall sentence embeddings are similar, missing unique semantic nuances. The paper shows that simply selecting the longest responses often works well because length correlates (r=0.92) with feature richness, but this is a crude proxy compared to direct feature measurement.
Key Novelty
SAE-Driven Diversity Selection
- Train a Sparse Autoencoder (SAE) on the residual stream of a language model to decompose text into atomic, monosemantic features
- Use these extracted features to measure diversity directly, rather than relying on coarse proxies like sentence length or embedding similarity
- Select data points that maximize the coverage of these unique semantic features (via greedy or similarity-based scaling algorithms)
Architecture
Pseudocode for SAE-GreedSelect and SAE-SimScale
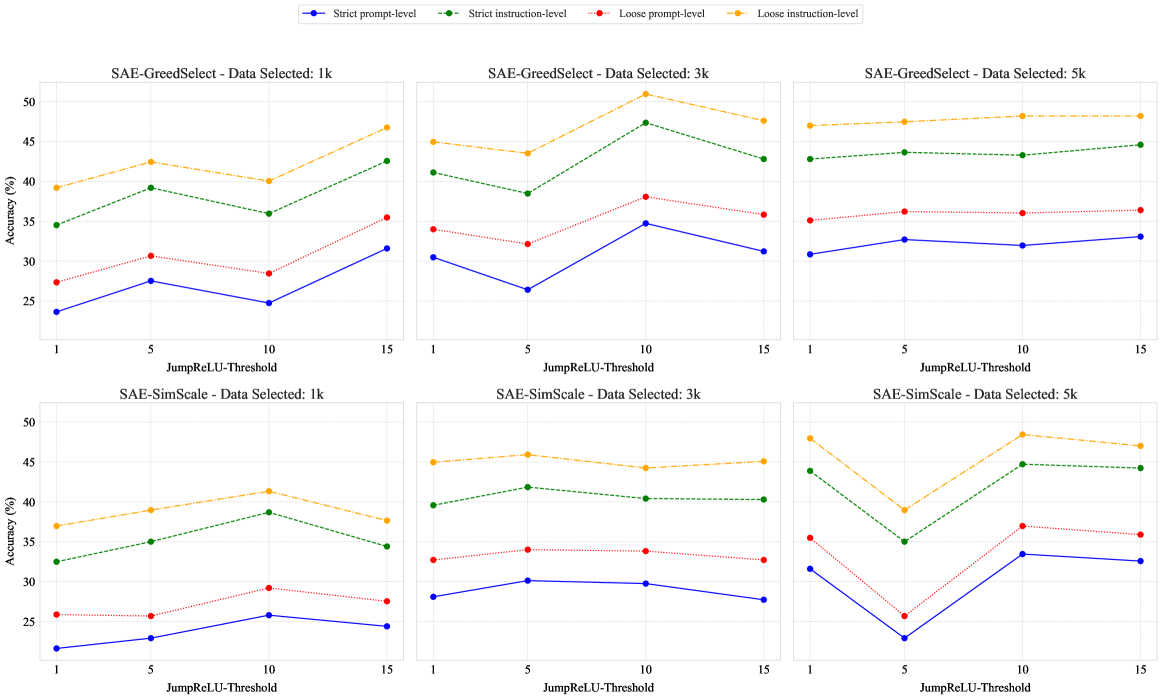
Evaluation Highlights
- +4.8 IFEval (Loose Instruction) score improvement using SAE-SimScale (50.96) compared to the #InsTag baseline (46.16) on WizardLM-70k data at 3k scale
- Matches the performance upper bound of using the full 70k dataset while using only 3k selected samples
- Outperforms commercial models like ChatGPT and Claude on AlpacaEval 2.0 when applied to Llama-2-13b-base with 5k selected data
Breakthrough Assessment
7/10
Novel application of SAEs (usually an interpretability tool) to data selection. Strong empirical results matching full-data performance with <5% of data. Significant for data-centric AI.