📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Vision-Centric Reasoning
Visual Grounding
Argus improves multimodal reasoning by explicitly predicting relevant image regions (bounding boxes) as intermediate steps and re-processing those regions to focus the model's attention.
Core Problem
Current MLLMs struggle with vision-centric tasks requiring precise focus because they rely on implicit, global attention rather than explicit goal-directed visual search.
Why it matters:
- Standard unified architectures process whole images indiscriminately, missing small or specific details needed for spatial relationships or property identification
- Implicit attention mechanisms in LLMs lack the conscious top-down control seen in human cognitive visual intelligence (goal-directed attention)
- Existing methods that use bounding boxes often keep them as text coordinates without actively re-engaging the visual features of those regions for better perception
Concrete Example:
When asked about the spatial relationship between two specific objects in a crowded scene, a standard MLLM might process the entire image globally and halluncinate. Argus first predicts the bounding boxes of the relevant objects (grounding), then re-samples visual tokens from those specific boxes to generate the final answer.
Key Novelty
Grounded Visual Chain-of-Thought (Visual CoT)
- Intermediate Grounding Step: The model is trained to first output text-based bounding boxes ([xmin, ymin, xmax, ymax]) for regions relevant to the user's query before answering.
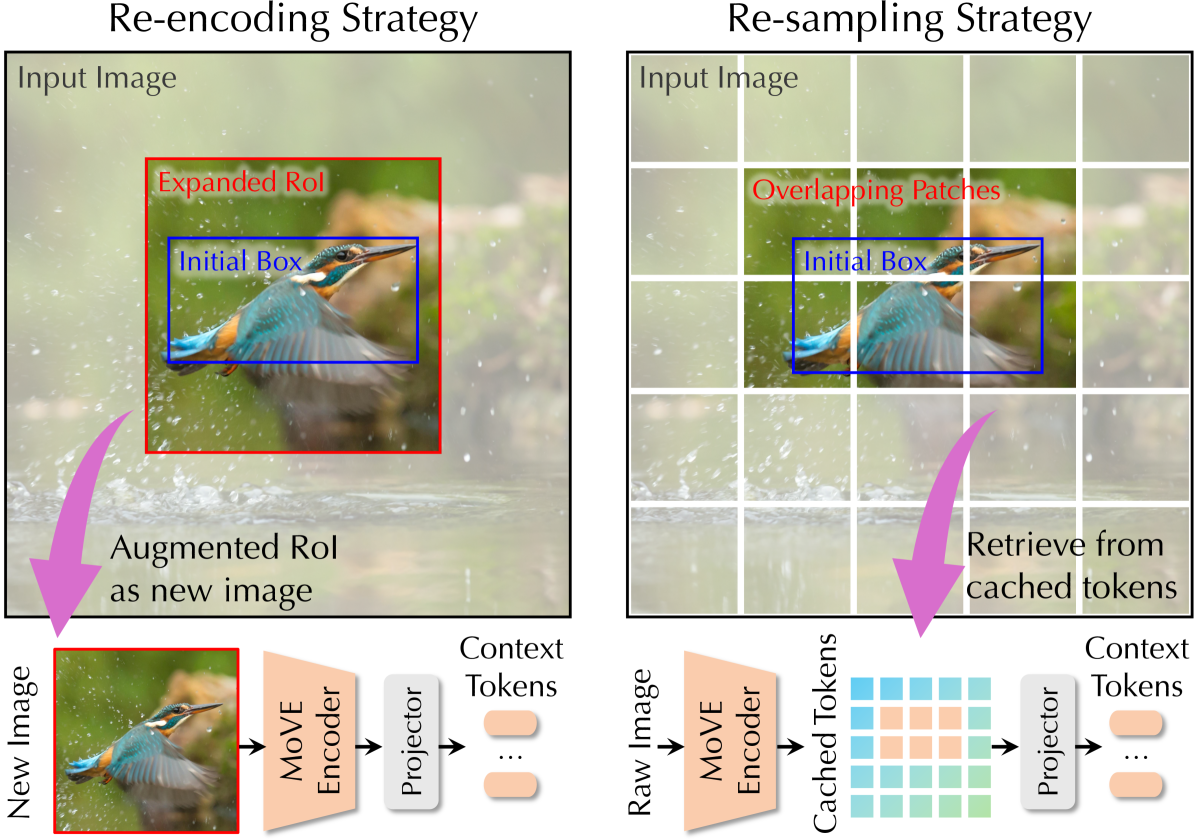
- Visual Re-engagement: These boxes are used to explicitly fetch specific visual features—either by cropping and re-encoding or by re-sampling cached tokens—forcing the model to 'look closer' at the relevant areas.
Architecture

The overall architecture of Argus, illustrating the two-pass inference process: initial encoding, RoI prediction (grounding), and visual re-engagement.
Evaluation Highlights
- Achieves state-of-the-art results on MMVP (Vision-centric Perception) with a score of 62.7, surpassing proprietary Gemini 1.5 Pro (61.3).
- Outperforms comparably sized open-source models (e.g., Eagle-X3-8B) on the V-Star benchmark (small object perception) by +4.1% (54.6 vs 50.5).
- Demonstrates strong dual capability: competitive on general reasoning while achieving high accuracy on referring grounding (85.24 on RefCOCO val), surpassing specialist models like Shikra.
Breakthrough Assessment
8/10
Strong conceptual advance by bridging grounding and reasoning via explicit visual re-engagement. Outperforms proprietary models on specific vision-centric benchmarks while maintaining generalist capabilities.