📊 Experiments & Results
Evaluation Setup
Few-shot In-Context Learning across 9 datasets covering symbolic, textual, and numerical modalities
Benchmarks:
- ARC-AGI (Symbolic matrix transformation)
- MiniARC (Symbolic matrix transformation)
- SCAN (Textual rule-based translation)
- COGS (Semantic parsing/Textual)
- List Functions (Numerical vector mapping)
- RAVEN (Visual reasoning (converted to symbolic))
Metrics:
- Accuracy (Exact Match)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of prompting strategies across all 9 benchmarks showing Direct Answering superiority. | ||||
| Average across 9 datasets | Relative Improvement | 0.0 | 20.42 | +20.42 |
| Average across 9 datasets | Relative Improvement | 0.0 | 36.34 | +36.34 |
| Symbolic Tasks (ARC, RAVEN, etc.) | Relative Improvement | 0.0 | 41.88 | +41.88 |
| Validation of the Hybrid Mechanism Hypothesis: analyzing whether success comes from correct reasoning (explicit) or despite wrong reasoning (implicit). | ||||
| List Function | Contribution Ratio | 1.0 | 7.5 | +6.5 |
| MiniSCAN | Contribution Ratio | 1.0 | 3.6 | +2.6 |
Experiment Figures
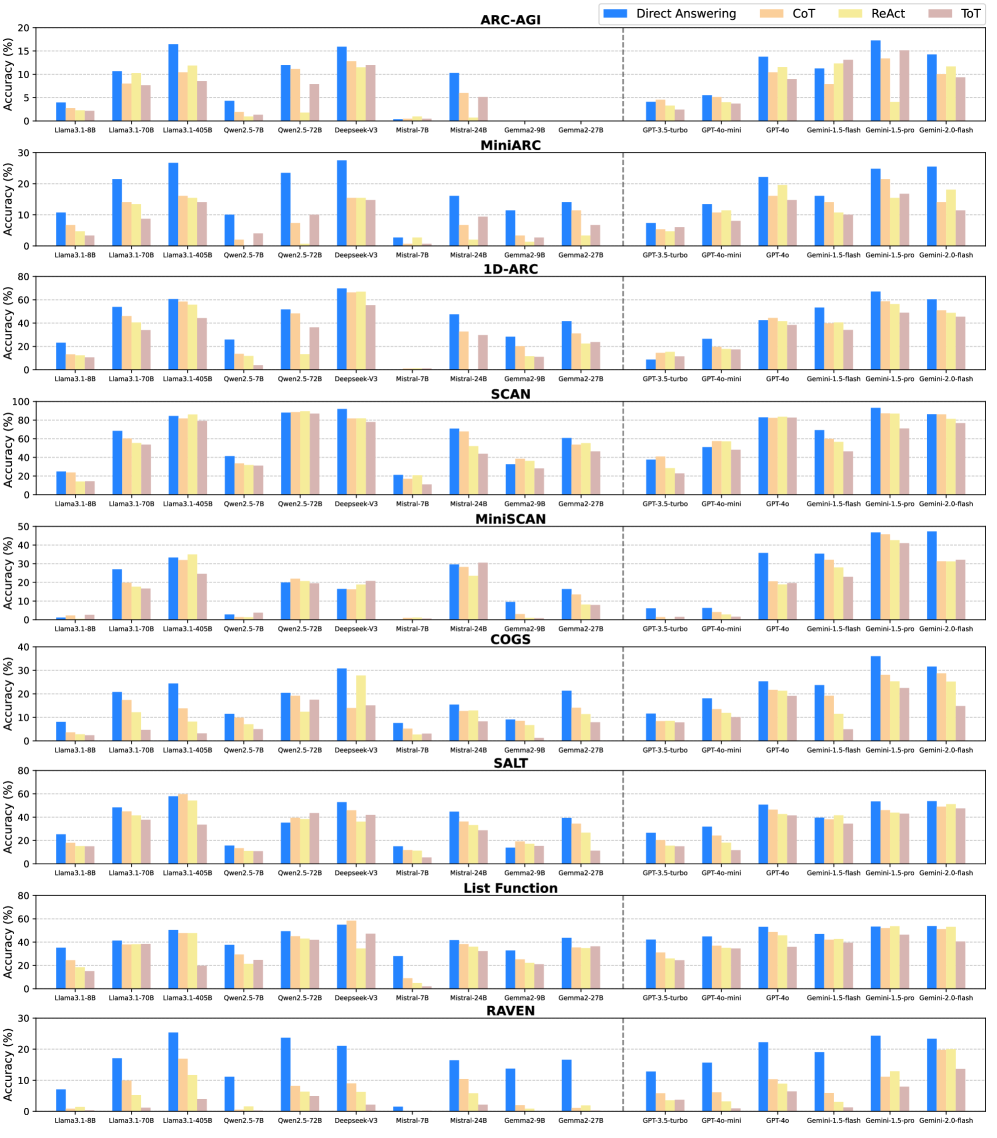
Main performance comparison across 9 benchmarks and 16 models
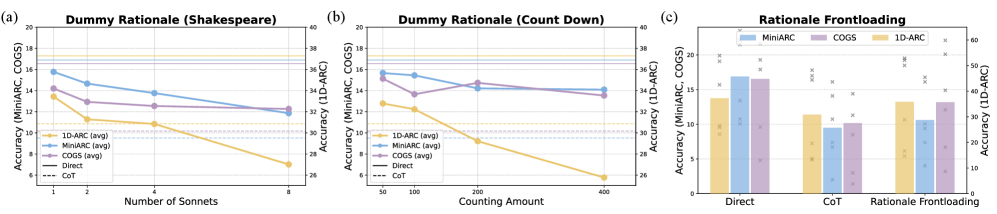
Impact of Contextual Distance using Dummy Rationales (Shakespeare/Countdown)
Main Takeaways
- The 'Curse of CoT': Explicit reasoning frameworks (CoT, ReAct, ToT) consistently underperform Direct Answering in pattern-based ICL, with the gap widening as the number of demonstration shots increases.
- Contextual Distance matters: Experiments with 'Dummy Rationales' (random Shakespeare text) show that simply adding length between demonstrations and the answer degrades performance, supporting the hypothesis that CoT disrupts implicit attention mechanisms.
- Pattern Inference Bottleneck: LLMs struggle significantly more with *inferring* the rule (explicitly stating it) than *executing* it on a test case, often hallucinating complex rules while still getting the right answer via implicit matching.
- Hybrid Mechanism: CoT success in this domain is largely driven by implicit reasoning 'salvaging' the output despite flawed explicit rationales, but the added length of the rationale makes this implicit salvage harder compared to Direct Answering.