📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Inference Acceleration
LLM Compression
C3oT trains LLMs on both long and compressed Chain-of-Thought (CoT) sequences using conditional tokens, enabling the model to generate concise reasoning during inference without losing accuracy.
Core Problem
Standard Chain-of-Thought (CoT) significantly increases decoding costs and latency because the reasoning steps are often much longer than the final answer.
Why it matters:
- High inference costs hinder LLM deployment in latency-sensitive applications like search and recommendation.
- Simply shortening CoT steps typically degrades reasoning performance, creating a trade-off between speed and accuracy.
- Existing acceleration methods (like Implicit-CoT) often sacrifice too much performance compared to explicit reasoning.
Concrete Example:
In a math problem asking for total clips sold, a standard CoT might output 'Natalia sold 48+24 = <<48+24=72>>72 clips altogether...' (long). C3oT aims to output just 'She sold 72 clips in April and May.' (short) while retaining the accuracy derived from the longer reasoning path.
Key Novelty
Conditioned Compressed Chain-of-Thought (C3oT)
- Uses a 'Compressor' (GPT-4) to distill long, detailed CoT into a concise version retaining only key information.
- Trains the student LLM on both long and short CoT simultaneously, distinguishing them with specific prompt tokens (Conditioned Training).
- During inference, triggers the 'short CoT' mode via the specific prompt token, allowing the model to access reasoning capabilities learned from long CoT while outputting few tokens.
Architecture
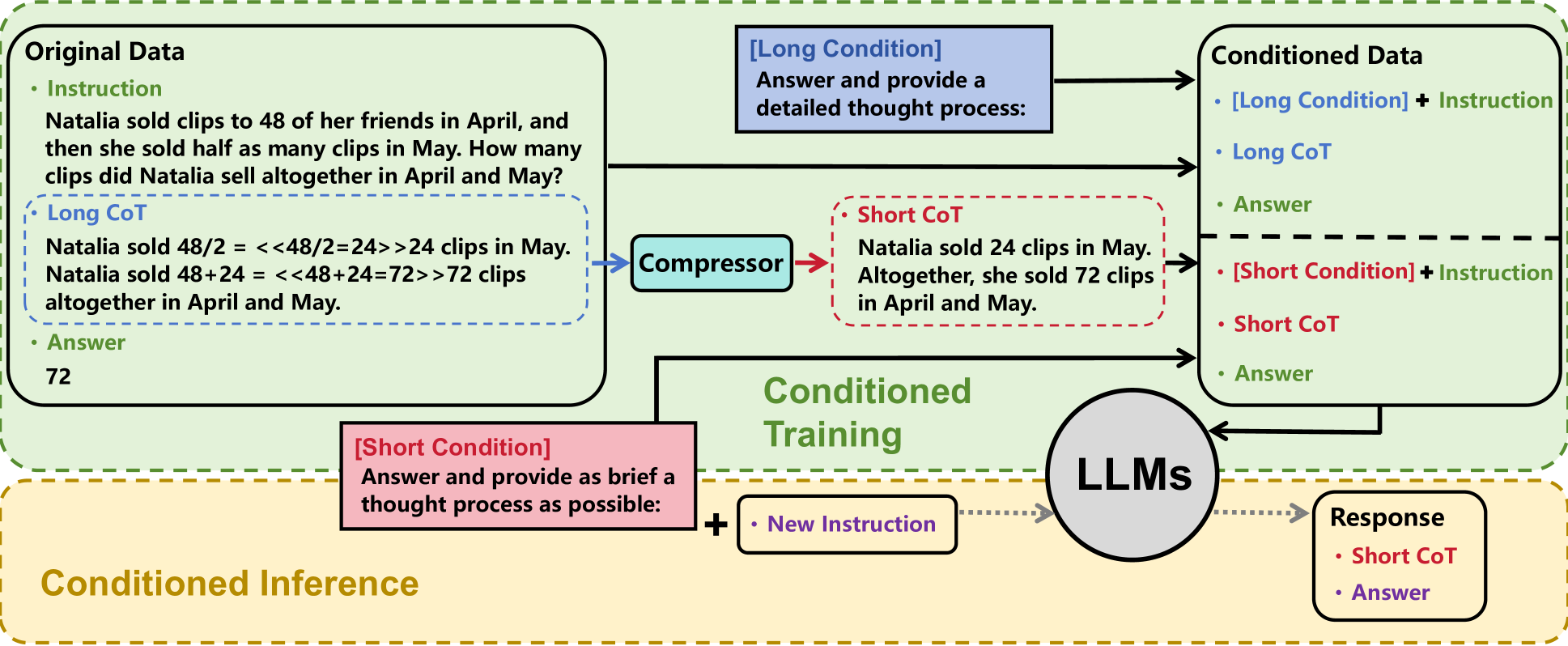
Overview of the C3oT framework including the Compressor, Conditioned Training, and Conditioned Inference phases.
Evaluation Highlights
- Compresses generated CoT length by up to 57.6% on GSM8K while maintaining accuracy comparable to models trained on full-length CoT.
- Outperforms Implicit-CoT by substantial margins (e.g., +8.6% accuracy on GSM8K) while using slightly more tokens.
- Achieves performance on par with standard long-CoT models across arithmetic (GSM8K, MathQA) and commonsense (ECQA, StrategyQA) datasets.
Breakthrough Assessment
7/10
Effectively solves the trade-off between CoT length and accuracy, a significant practical hurdle. While the core mechanics (knowledge distillation/conditioning) are known, the specific application to CoT compression is novel and effective.