📝 Paper Summary
Video-to-Audio (V2A) Generation
Multimodal Large Language Models (MLLMs)
Audio Editing
ThinkSound decomposes video-to-audio generation into a three-stage pipeline (Foley generation, object refinement, editing) guided by structured Chain-of-Thought reasoning from a multimodal LLM to a unified flow-matching audio model.
Core Problem
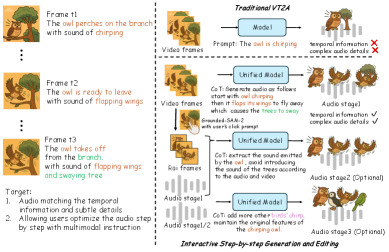
End-to-end video-to-audio systems act as black boxes, failing to capture complex compositional nuances like synchronizing multiple events or reasoning about acoustic environments.
Why it matters:
- Current models produce generic sounds that lack precise synchronization with subtle visual cues (e.g., specific object motions or environmental interactions)
- Users lack fine-grained control over the generation process, unlike professional sound designers who work in iterative stages
- Existing multimodal audio models often fragment tasks (generation, editing) into separate specialized models rather than using a unified reasoning-driven framework
Concrete Example:
Current systems struggle to distinguish determining when an owl is chirping versus flapping its wings based on visual dynamics, often merging them into generic bird noises or failing to sync the specific sound event with the visual action.
Key Novelty
Chain-of-Thought (CoT) Driven Interactive Audio Synthesis
- Decomposes the audio creation process into three explicit stages: foundational soundscape generation, click-based object refinement, and instruction-based editing
- Uses a multimodal LLM to generate structured reasoning text (CoT) that describes temporal and acoustic properties before synthesis, acting as a bridge between visual inputs and audio generation
- Unifies all generation and editing tasks into a single flow-matching model that can accept arbitrary combinations of video, text, and audio context
Architecture
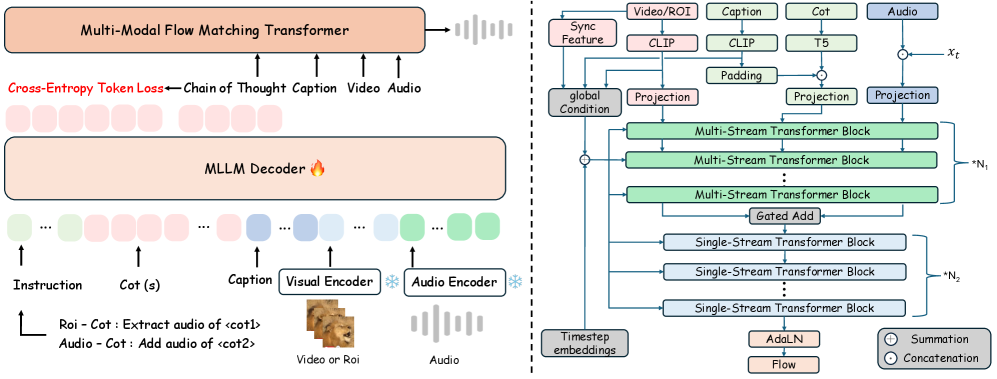
The overall framework of ThinkSound, illustrating the MLLM fine-tuning process and the unified audio foundation model architecture.
Evaluation Highlights
- Achieves state-of-the-art results on V2A benchmarks, surpassing Diff-Foley and MMAudio on objective metrics like Frechet Audio Distance (FAD)
- Excels in the out-of-distribution Movie Gen Audio benchmark, demonstrating robust generalization
- User studies show preference for ThinkSound's generated audio over baselines in terms of overall quality and audio-visual alignment
Breakthrough Assessment
8/10
Significant step forward in controllable V2A by successfully integrating CoT reasoning with a unified generative model. The three-stage interactive workflow closely mimics professional sound design.