📝 Paper Summary
Vision-Language-Action (VLA) Models
World Models for Robotics
Video Prediction / Future Frame Forecasting
FlowVLA improves robot policy learning by forcing the world model to explicitly predict optical flow as an intermediate 'visual thought' before generating future video frames.
Core Problem
Standard VLA world models predict the next frame directly from the current frame, leading to a 'pixel-copying trap' where the model replicates static backgrounds without understanding physical dynamics.
Why it matters:
- Direct next-frame prediction results in blurry, physically implausible long-horizon forecasts because the model lacks explicit motion understanding.
- There is a domain gap between passive video observation and active policy learning; without understanding dynamics, the model transfers poorly to downstream action tasks.
- Inefficient knowledge transfer leads to slow convergence and high sample requirements during policy fine-tuning.
Concrete Example:
In a robot manipulation video, a standard model minimizing reconstruction error might simply copy the static table pixels from the previous frame to the next, ignoring the moving robot arm. This results in a 'ghosting' effect or vanishing arm in the prediction, making the world model useless for planning actual robot actions.
Key Novelty
Visual Chain of Thought (Visual CoT) via Unified Flow Tokenization
- Decomposes prediction into a reasoning chain: first predict *how* pixels move (optical flow), then predict the *next appearance* based on that motion.
- Encodes 2D optical flow vectors into standard RGB images using color-coding, allowing the exact same VQ-GAN tokenizer and Transformer to process both motion and visual frames without new architecture.
Architecture
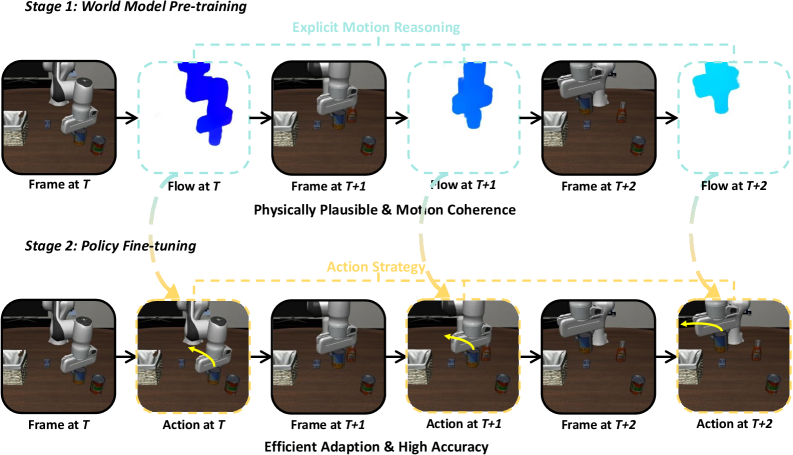
Conceptual comparison between Traditional Next-Frame Prediction and the proposed Visual Chain of Thought.
Evaluation Highlights
- The paper claims state-of-the-art performance on challenging robot manipulation benchmarks (CALVIN).
- The method demonstrates substantially improved sample efficiency compared to baselines (UniVLA, WorldVLA) during policy fine-tuning.
- Generates physically plausible and coherent visual forecasts by explicitly modeling dynamics via optical flow.
Breakthrough Assessment
8/10
Elegantly unifies motion and appearance in a single vocabulary to force physical reasoning. The 'Visual CoT' concept addresses a fundamental flaw in current video generation world models (lack of dynamics).