📝 Paper Summary
Code Generation
Reasoning strategies (Chain-of-Thought)
UnCert-CoT dynamically switches between direct code generation and Chain-of-Thought reasoning based on token uncertainty at new lines, preventing errors caused by overthinking simple tasks.
Core Problem
Existing Chain-of-Thought (CoT) methods suffer from 'overthinking,' where models apply unnecessary complex reasoning to simple tasks, wasting compute and inducing errors.
Why it matters:
- Unnecessary reasoning steps can distort the logical process, leading to incorrect code even when the model 'knows' the direct answer
- Indiscriminate use of CoT is computationally inefficient, allocating excessive tokens to trivial problems
- Prediction difficulty varies significantly within a code snippet (e.g., high at the start of a new line), but standard methods apply uniform decoding strategies
Concrete Example:
In a dynamic programming problem (spending exactly $n$ dollars), a direct generation approach correctly implements an exhaustive search. However, when forced to use CoT, the model incorrectly reasons that a greedy strategy (subtracting largest prices first) is sufficient, leading to a failed solution (Figure 1 in paper).
Key Novelty
Uncertainty-Aware Chain-of-Thought (UnCert-CoT)
- Detects 'difficult' points during generation by measuring uncertainty (Entropy or Probability Differential) specifically at the start of new code lines
- Selectively activates Chain-of-Thought reasoning only when uncertainty exceeds a threshold, otherwise defaulting to direct greedy generation
- Uses a CoT-decoding mechanism for high-uncertainty lines that samples multiple reasoning paths and selects the one with the highest confidence
Architecture
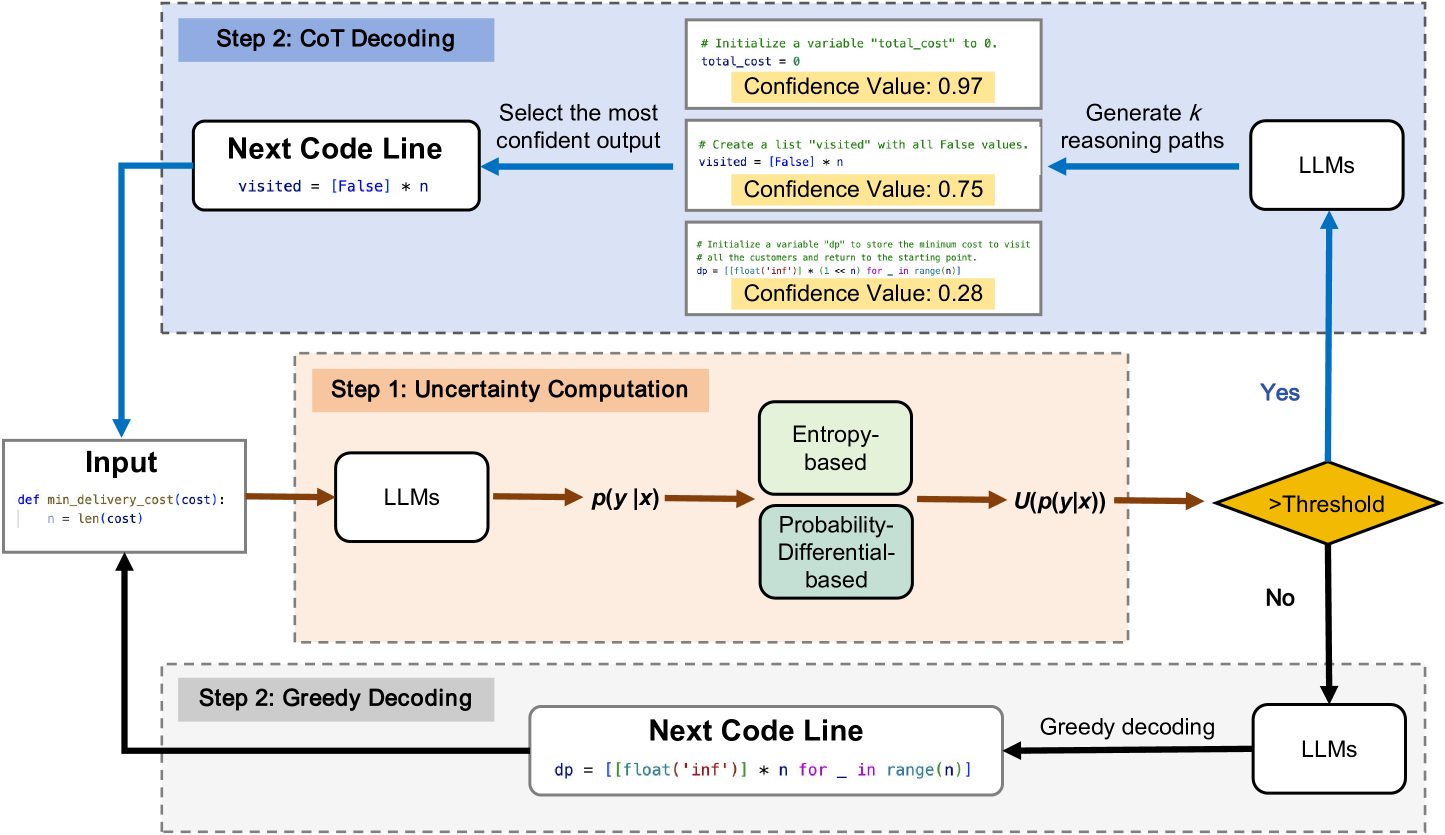
The overall pipeline of UnCert-CoT during inference
Evaluation Highlights
- Outperforms baseline approaches by 6.1% on the challenging MHPP (Mostly Hard Python Problems) benchmark
- Achieves a 3.5% improvement over baselines on the HumanEval benchmark
- Demonstrates consistent improvements across multiple model families, including DeepSeek-Coder, CodeLlama, and Qwen-Coder
Breakthrough Assessment
6/10
A smart, heuristic-based inference optimization that addresses a specific failure mode (overthinking). While effective, it is an inference-time toggle rather than a fundamental architectural change.