📝 Paper Summary
Visual Reasoning
Tool Use
Structured Document Understanding
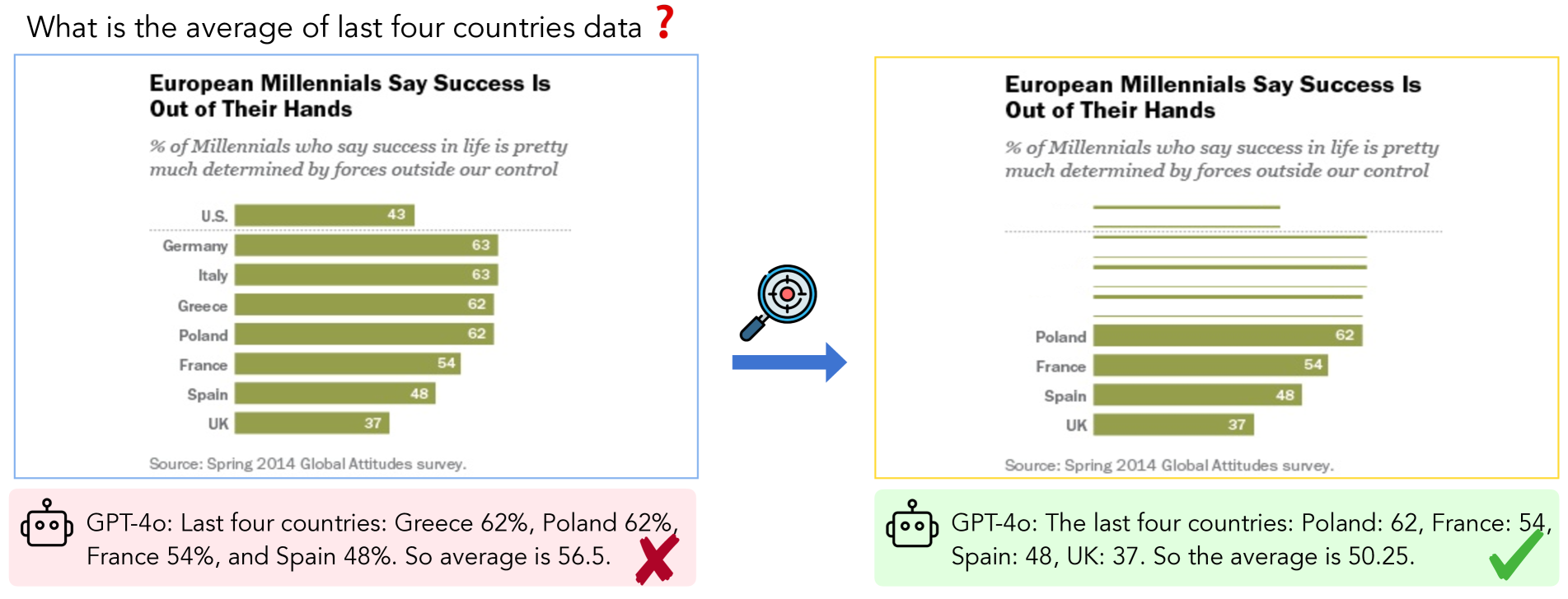
ReFocus enables multimodal LLMs to solve complex structured image tasks by generating code to visually edit the input image (masking, highlighting) as an intermediate reasoning step.
Core Problem
Multimodal LLMs struggle with structured images (tables/charts) because they lack selective attention mechanisms, often hallucinating or losing focus during multi-hop reasoning.
Why it matters:
- Current models rely on converting images to text or using internal CoT, which fails to revisit visual evidence during complex reasoning steps.
- Existing visual tool-use methods (like Visual Sketchpad) rely on external vision experts (e.g., SAM) that don't work on text-heavy structured data.
- Accurate interpretation of scientific charts and financial tables is critical for reliable automated data analysis.
Concrete Example:
In a table question asking for 'total wins by Belgian riders,' a standard GPT-4o might hallucinate numbers from adjacent rows. ReFocus generates code to draw red boxes around 'Belgium' rows and mask irrelevant columns, forcing the model to attend only to the correct data for summation.
Key Novelty
Visual Editing as Chain-of-Thought
- Treats image editing not just as data augmentation, but as a dynamic reasoning step where the model actively simplifies its own input.
- Uses the LLM to write Python/OpenCV code to modify images (highlight, mask, crop) based on the current reasoning state, creating a 'visual thought'.
- Demonstrates that simple geometric edits (boxes, masks) generated by the model itself are more effective than external vision experts for structured text data.
Architecture
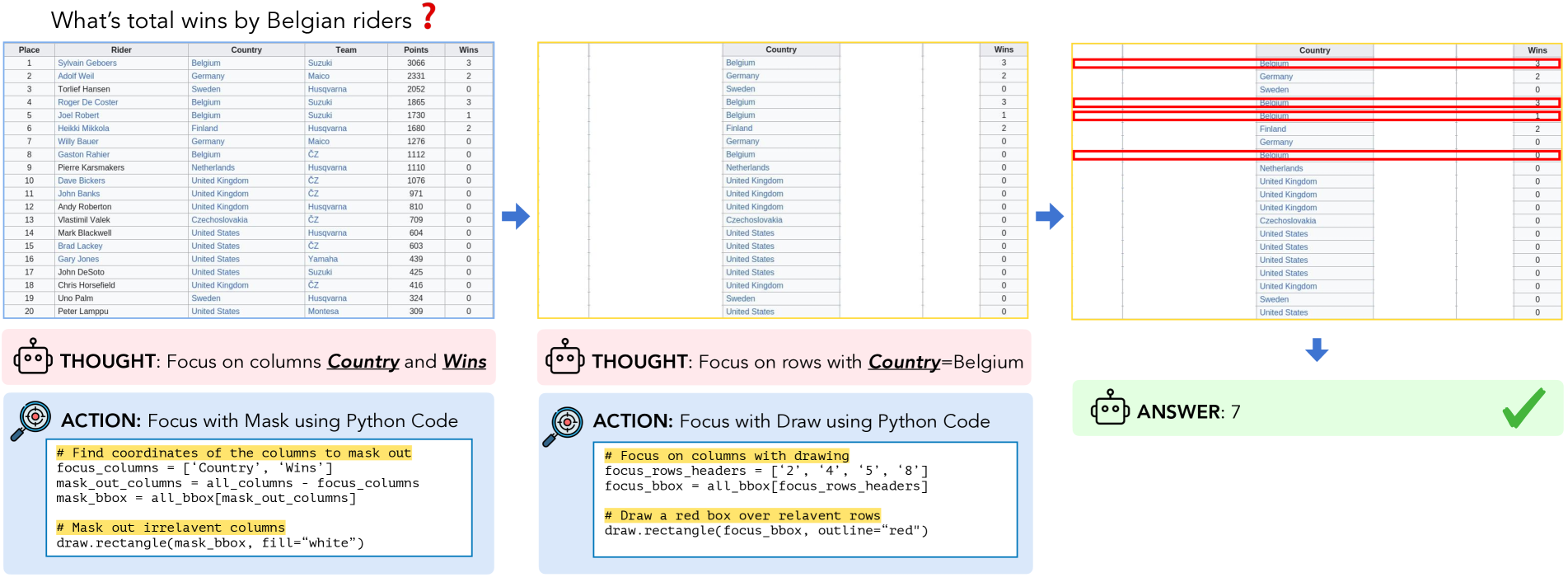
The iterative ReFocus pipeline on a tabular VQA task.
Evaluation Highlights
- +11.0% average accuracy gain on tabular tasks (VWTQ, TabFact) over GPT-4o baseline.
- +6.8% average accuracy gain on chart tasks (CharXiv, ChartQA) over GPT-4o baseline.
- +8.0% gain when finetuning Phi-3.5-vision on ReFocus-generated data compared to standard VQA supervision.
Breakthrough Assessment
8/10
Simple yet highly effective paradigm shift. Instead of better OCR or larger encoders, it allows the model to 'scribble' on the test paper, significantly boosting reasoning on structured data without external models.