📝 Paper Summary
Process Reward Models (PRMs)
Chain-of-Thought (CoT) Reasoning
Reinforcement Learning (RLHF/RLAIF)
ReasonFlux-PRM improves reasoning performance by training a reward model to explicitly score unstructured intermediate thinking trajectories using alignment, coherence, and template-based supervision, unlike standard PRMs trained only on final responses.
Core Problem
Existing Process Reward Models are trained on structured final responses and fail to effectively evaluate the messy, unstructured 'thinking trajectories' generated by frontier models like Deepseek-R1.
Why it matters:
- Standard PRMs degrade performance when used to select training data from thinking-model outputs because they cannot distinguish high-quality intermediate reasoning from noise.
- Frontier models increasingly use 'trajectory-response' formats (long thinking trace + concise answer), creating a supervision gap for existing reward models.
Concrete Example:
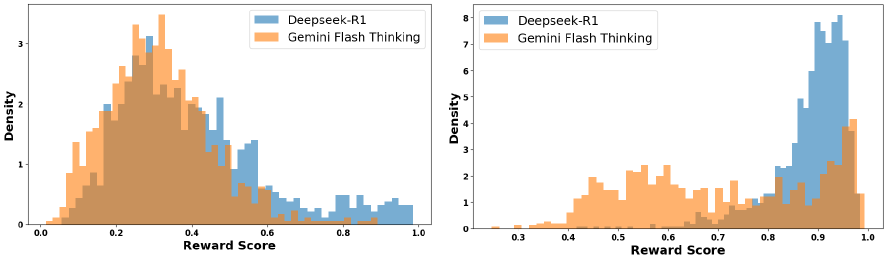
When filtering Deepseek-R1 outputs, a standard PRM (Qwen2.5-Math-PRM-72B) fails to differentiate between high-quality thinking traces and lower-quality ones, often assigning similar scores to distinct oracle outputs, which leads to suboptimal data selection for downstream training.
Key Novelty
Trajectory-Aware Process Reward Model (ReasonFlux-PRM)
- Treats 'thinking' steps and 'final answer' steps differently, using specific reward signals for the unstructured thinking phase.
- Constructs synthetic training targets using three signals: alignment (similarity to final answer), quality (LLM judge evaluation), and coherence (consistency with previous steps).
- Validates reasoning strategies using a 'template-guided' trajectory reward, where a verifier extracts the high-level logic template and tests if it generalizes to new solutions.
Architecture
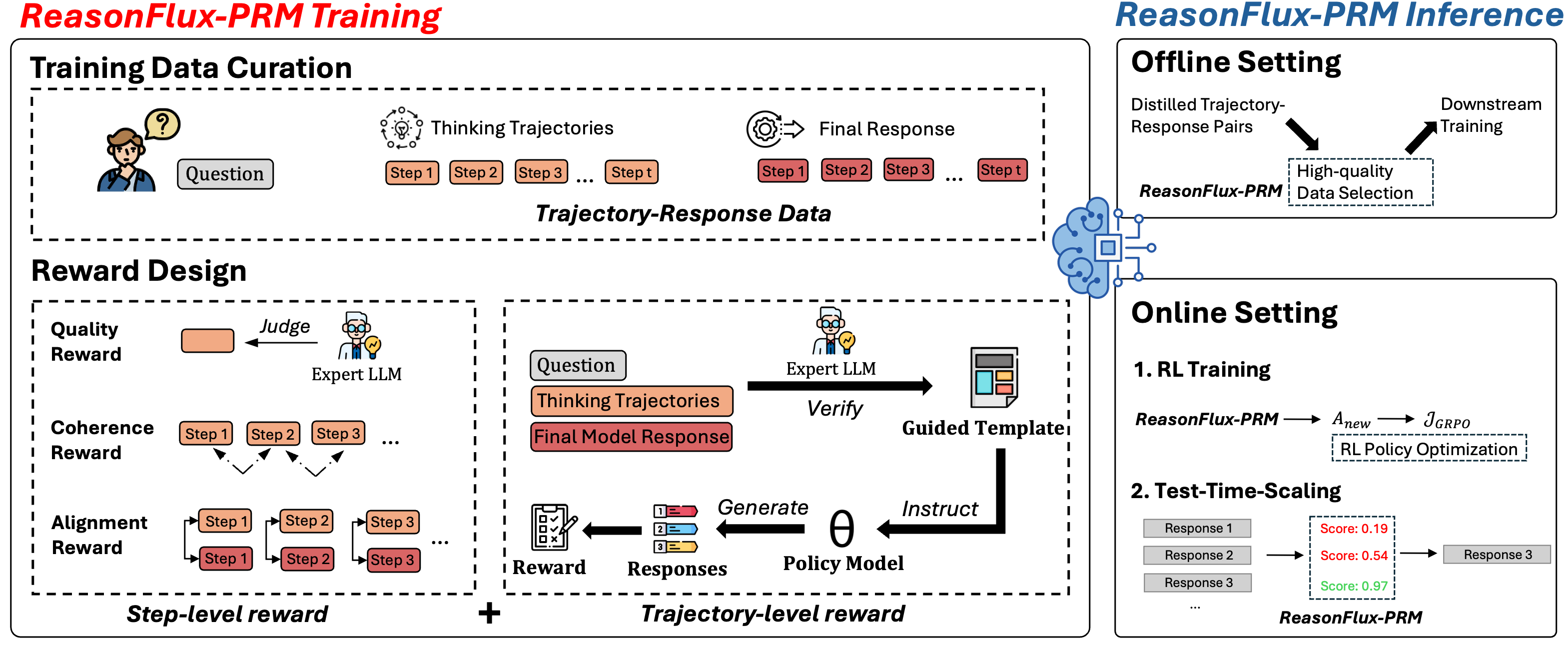
Overview of ReasonFlux-PRM framework illustrating the reward construction and training process.
Evaluation Highlights
- +12.1% average accuracy improvement on AIME, MATH500, and GPQA-Diamond benchmarks during supervised fine-tuning when using ReasonFlux-PRM-7B for data selection.
- ReasonFlux-PRM-7B outperforms the 10x larger Qwen2.5-Math-PRM-72B in filtering high-quality training data.
- +4.5% average accuracy gain in Reinforcement Learning (GRPO) and +6.3% in Test-Time Scaling (Best-of-N) using ReasonFlux rewards.
Breakthrough Assessment
8/10
Addresses a critical and emerging gap in supervising 'thinking' models (like o1/R1). Strong empirical gains over much larger baselines demonstrate the effectiveness of the trajectory-aware supervision approach.