📝 Paper Summary
Multimodal Chain-of-Thought (CoT)
Mathematical Reasoning
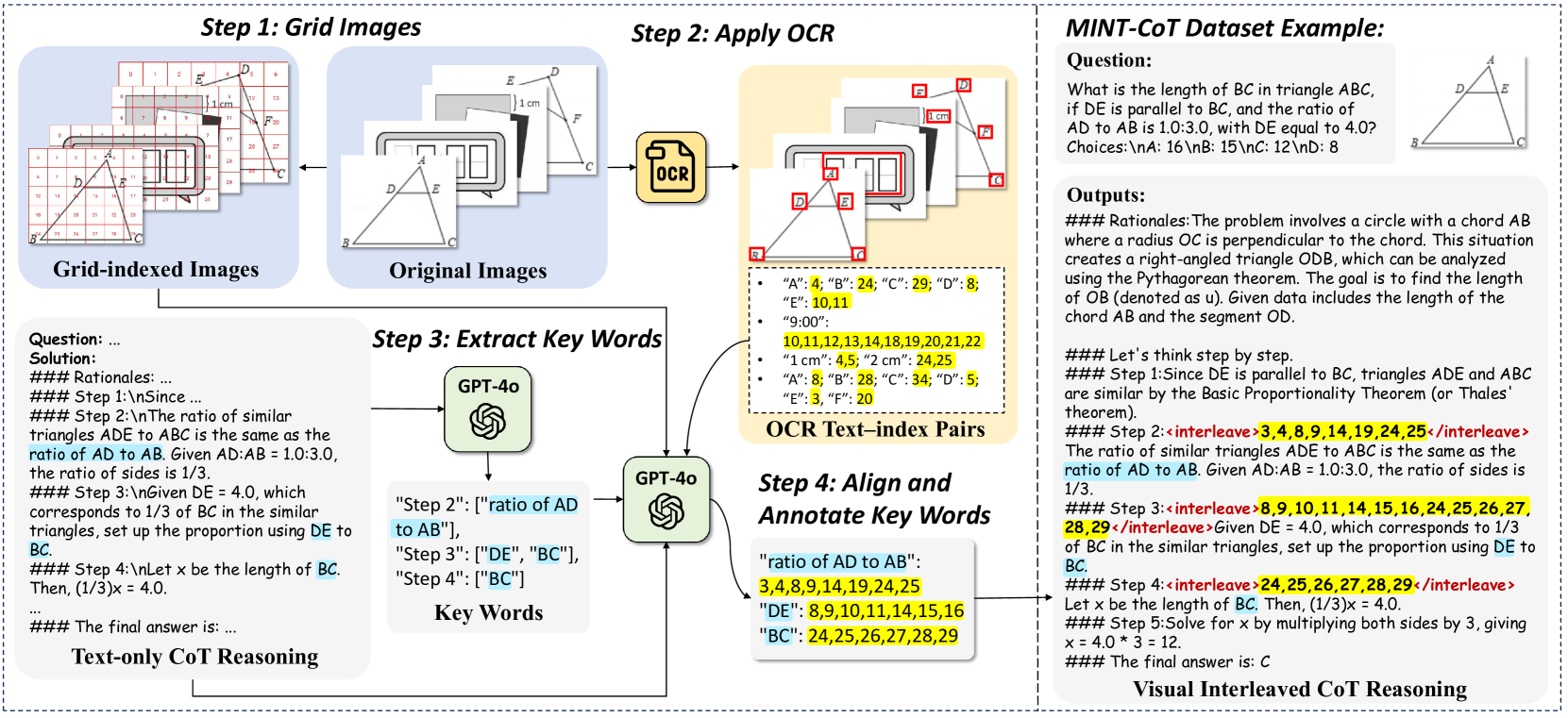
MINT-CoT improves mathematical reasoning in multimodal models by dynamically selecting and interleaving fine-grained visual tokens directly into textual reasoning steps using a specialized Interleave Token.
Core Problem
Existing multimodal math reasoning methods rely on coarse bounding boxes or insufficiently trained vision encoders, failing to capture the complex, interconnected fine-grained details necessary for solving math problems.
Why it matters:
- Box-based methods (like cropping) often include irrelevant background noise or miss connected geometric elements, confusing the model
- Standard vision encoders (CLIP, SigLIP) are trained on natural images and struggle with out-of-distribution mathematical diagrams
- Current approaches often depend on external tools or separate detection models, increasing computational cost and complexity
Concrete Example:
In a geometry problem where visual information is highly interconnected (e.g., intersecting lines), box-based methods crop a rectangular region that includes distracting elements. MINT-CoT, instead, selects only the specific visual tokens representing 'line segment AB' or 'angle DOC' relevant to the current reasoning step.
Key Novelty
Mathematical Interleaved Token (MINT) Selection
- Introduces a special 'Interleave Token' that acts as a bridge; when generated, it compares its state with all visual tokens to find the most relevant ones
- Instead of predicting bounding boxes, the model directly selects soft visual tokens based on similarity scores, allowing for arbitrary shapes (lines, curves) rather than just rectangles
- Uses a progressive training pipeline moving from text-only reasoning to supervised interleaved training, and finally reinforcement learning to refine token selection
Architecture
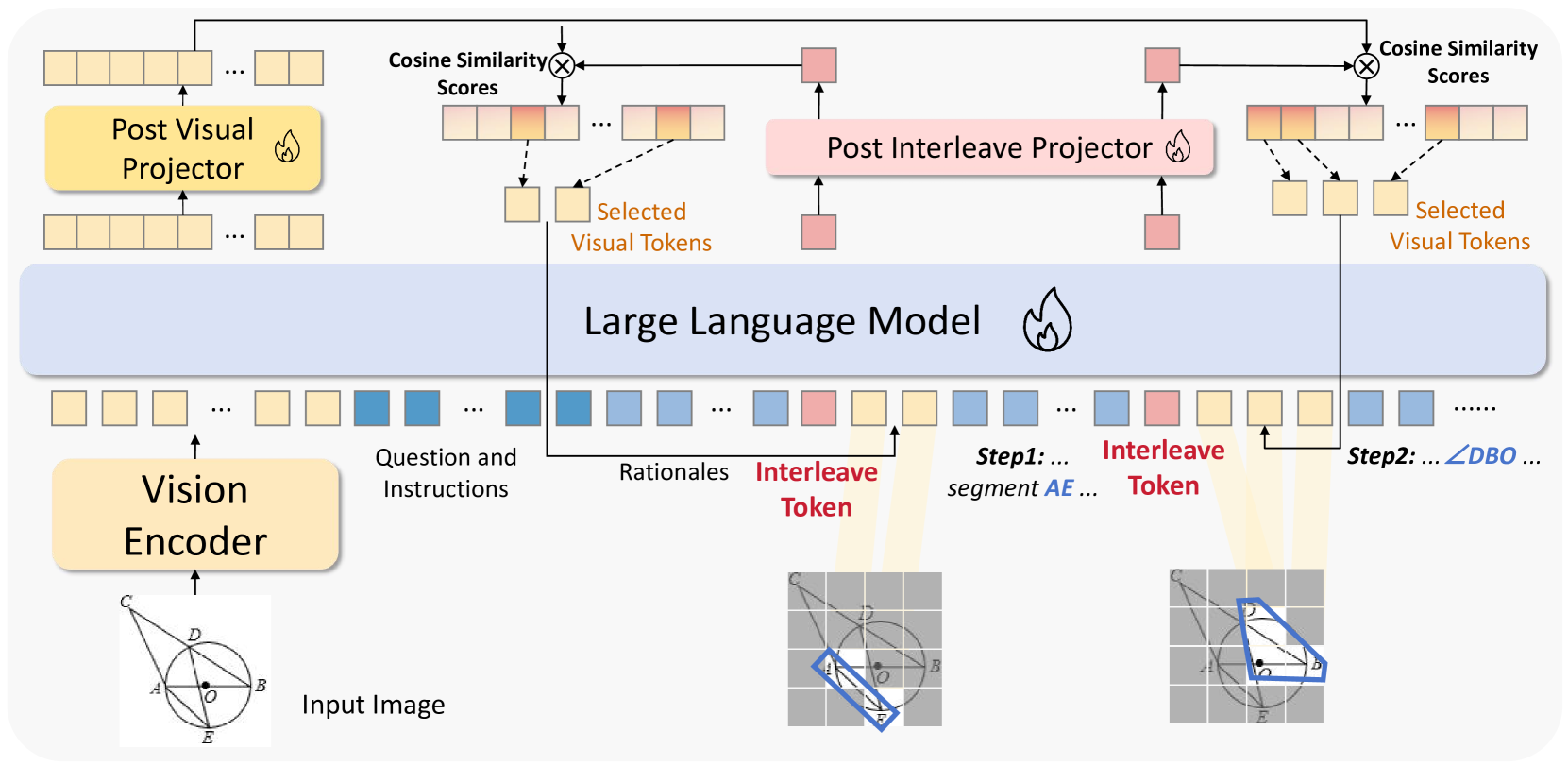
Overview of the MINT-CoT framework, illustrating how the Interleave Token selects visual tokens during the generation process.
Evaluation Highlights
- +34.08% improvement on MathVista compared to the baseline model (MINT-CoT-7B)
- +28.78% improvement on GeoQA compared to the baseline model
- +23.2% improvement on MMStar compared to the baseline model
Breakthrough Assessment
8/10
Significant performance jumps (>20-30%) on major benchmarks. The shift from bounding boxes to direct token selection for math reasoning is a methodologically sound and effective innovation.