📊 Experiments & Results
Evaluation Setup
Zero-shot Chain-of-Thought reasoning with varying compression constraints
Benchmarks:
- MATH-500 (Complex Math Reasoning)
- GSM8K (Grade School Math)
- MMLU-Pro Math (Advanced Math Reasoning)
Metrics:
- Accuracy (fraction of correct answers)
- Average Token Length
- Compression Ratio (vs Default CoT)
- Statistical methodology: Threshold classification accuracy used to validate Token Complexity hypothesis
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of Default CoT vs. 'BeConcise' prompt shows consistent token reduction with minimal accuracy loss, but falls short of theoretical upper bounds. | ||||
| MATH-500 | Token Count | 635 | 505 | -130 |
| MATH-500 | Compression Upper Bound | 1.26 | 3.69 | +2.43 |
| GSM8K | Token Count | 200 | 136 | -64 |
| GSM8K | Compression Upper Bound | 1.47 | 11.16 | +9.69 |
| Average across datasets | Classification Accuracy | Not reported in the paper | 0.94 | Not reported in the paper |
Experiment Figures
Scatter plot of Average Token Length vs. Accuracy for 31 different prompts on MMLU-Pro Math
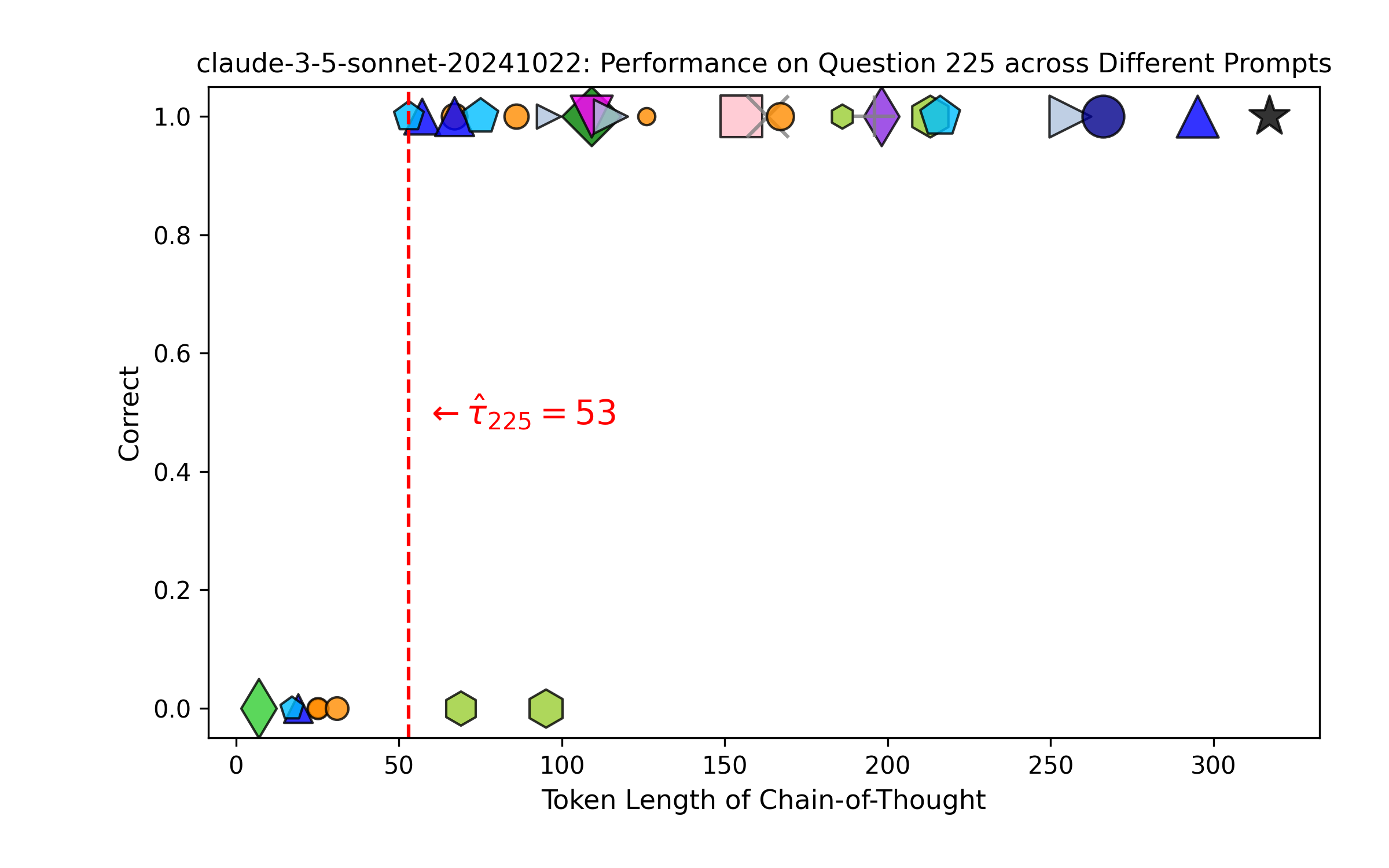
Left: Performance of 31 prompts on a single MATH-500 question sorted by length. Right: Actual vs. Predicted accuracy.
Main Takeaways
- The 'Universal Trade-off Curve' implies that prompt engineering for conciseness (e.g., specific wording, languages) matters less than the resulting length of the chain.
- Token complexity is a robust measure of problem difficulty: harder problems strictly require more tokens.
- Existing compression prompts are 'lossy' and operate far from the theoretical optimal boundary, especially on easier datasets like GSM8K where massive compression (up to 11x) is theoretically possible.