📝 Paper Summary
Efficient LLM Inference
Prompt Compression
Chain-of-Thought Reasoning
TokenSkip improves LLM efficiency by pruning semantically redundant tokens from Chain-of-Thought data and fine-tuning models to generate these compressed reasoning paths directly based on a control parameter.
Core Problem
Long Chain-of-Thought (CoT) sequences significantly increase inference latency and compute costs due to the autoregressive nature of LLMs, but simply cutting steps hurts reasoning accuracy.
Why it matters:
- Longer CoT sequences (thousands of steps) are needed for complex reasoning (e.g., OpenAI o1), creating a linear increase in latency and quadratic cost in attention
- Existing prompt-based compression often fails to adhere to target lengths, while brute-force truncation destroys reasoning capabilities
- Step-skipping approaches can conflict with test-time scaling, impairing the model's ability to solve complex problems
Concrete Example:
In a math problem asking for an age calculation, a standard CoT includes filler phrases like 'Let's break it down step by step' and 'so Marcus is'. TokenSkip removes these connectors, keeping only the critical equations and numbers (e.g., 'Deanna is 26... Marcus 26-5=21...'), significantly shortening the output without losing the logic.
Key Novelty
Controllable CoT Compression via SFT on Pruned Trajectories
- Analyzes token importance in CoT to reveal that not all tokens contribute equally to reasoning (e.g., equations are more important than connectors)
- Constructs a training dataset by pruning low-importance tokens from valid CoT trajectories based on a target compression ratio
- Fine-tunes the LLM to generate these compressed CoTs directly when prompted with a specific control token (compression ratio), allowing adjustable efficiency-accuracy trade-offs
Architecture
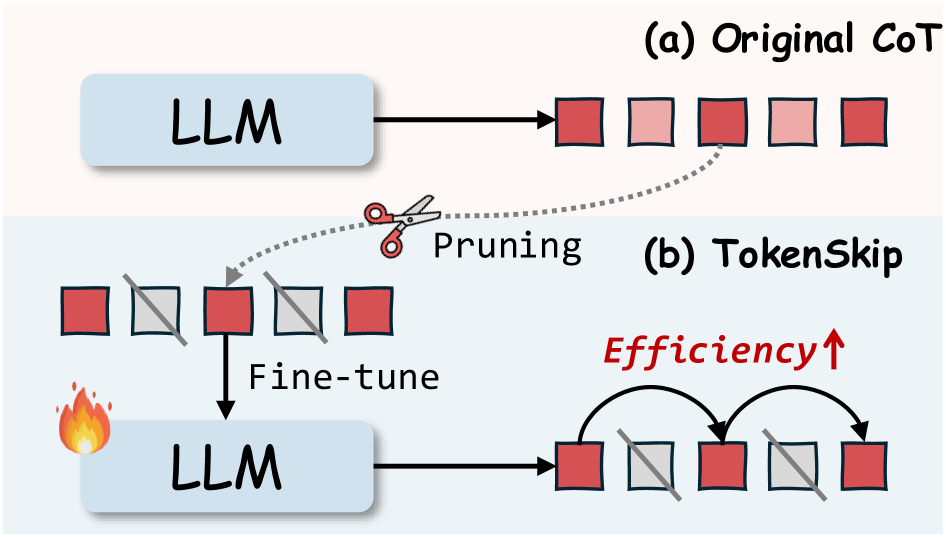
The overall workflow of TokenSkip, illustrating the data construction via token pruning and the subsequent fine-tuning and inference process.
Evaluation Highlights
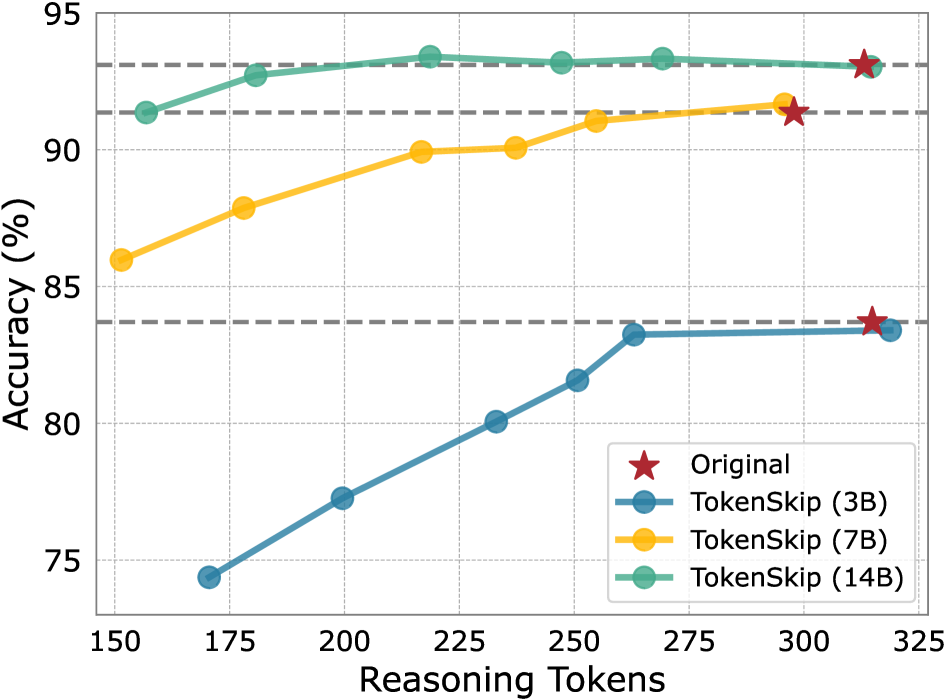
- Reduces reasoning tokens by 40% (from 313 to 181) on GSM8K using Qwen2.5-14B-Instruct with less than a 0.4% performance drop
- Achieves a 1.8x inference speedup on GSM8K with a 0.53 compression ratio while maintaining strong accuracy (only ~10% drop compared to 79% drop for truncation)
- Reduces tokens by 30% on MATH-500 using LLaMA-3.1-8B-Instruct with less than a 4% performance decline
Breakthrough Assessment
7/10
Offers a practical, low-cost solution (SFT with LoRA) to a significant problem (CoT latency). The preservation of accuracy at 40% compression is impressive, though the method relies on existing importance metrics like LLMLingua-2.