📝 Paper Summary
Implicit Chain-of-Thought
Model Compression / Acceleration
Knowledge Distillation
CODI compresses verbose chain-of-thought reasoning into compact continuous vectors by distilling the hidden state 'shift' induced by explicit reasoning into a student model via joint training.
Core Problem
Explicit Chain-of-Thought (CoT) is computationally expensive due to verbose token generation, while prior implicit CoT methods (reasoning in latent space) suffer from performance degradation and forgetting issues.
Why it matters:
- Verbalizing full reasoning steps slows down inference significantly (communication vs. computation trade-off)
- Learning explicit tokens can cause models to overfit on superficial linguistic cues rather than the underlying logic
- Previous implicit methods like Coconut use curriculum learning, which leads to forgetting and consistently underperforms explicit CoT
Concrete Example:
When solving a math problem like '10/5 * 2', explicit CoT generates multiple tokens '<<10/5=2>> <<2*2=4>>'. CODI replaces these with a fixed number of continuous vectors (e.g., 6 vectors) that encode the same reasoning state, speeding up generation while maintaining accuracy.
Key Novelty
Continuous Chain-of-Thought via Self-Distillation (CODI)
- Jointly trains a model as both 'Teacher' (Explicit CoT) and 'Student' (Implicit CoT) to avoid curriculum learning forgetting
- Uses feature-level distillation to force the student's latent thoughts to produce the same hidden state 'shift' as the teacher's explicit reasoning steps
- Aligns the hidden activations of a specific distillation token (e.g., the colon before the answer) rather than the entire sequence
Architecture
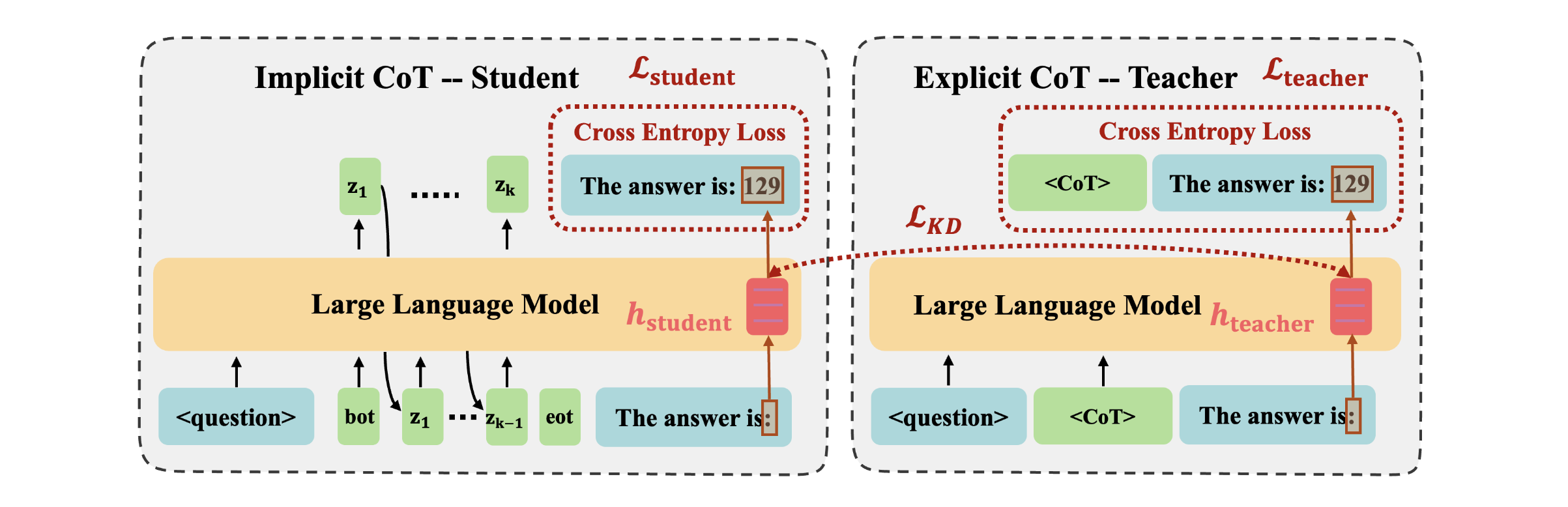
The CODI training framework showing parallel Teacher and Student tasks. The Teacher processes explicit CoT tokens, while the Student processes continuous thought vectors. A distillation loss aligns the Student's last hidden state with the Teacher's state before the answer.
Evaluation Highlights
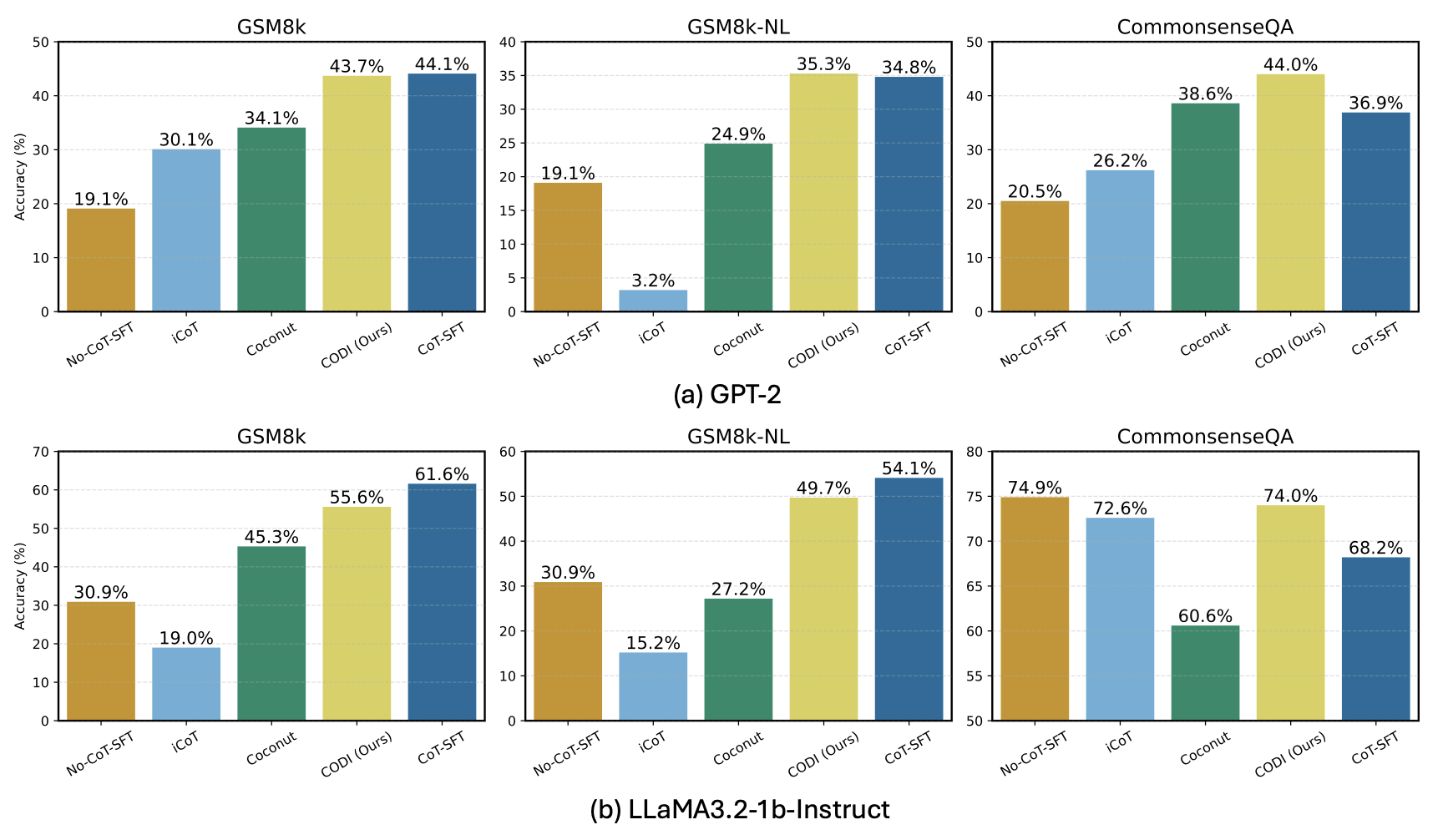
- Achieves 99% of explicit CoT-SFT accuracy on GSM8k with GPT-2, marking the first implicit CoT method to match explicit performance at this scale
- Outperforms the previous state-of-the-art implicit method (Coconut) by 28.2% accuracy on GSM8k
- Achieves a 3.1x compression rate on GSM8k and up to 8.2x on the more verbose GSM8k-Aug-NL dataset
Breakthrough Assessment
8/10
Significant advance in implicit reasoning; CODI is the first to effectively close the performance gap between explicit and implicit CoT on small models, offering a viable path for efficient latent reasoning.