📝 Paper Summary
3D Vision-Language Modeling
Embodied AI Agents
LL3DA is a 3D-LLM that accepts point clouds and visual interactions (clicks, boxes) directly to resolve spatial ambiguity and perform reasoning without expensive multi-view image projections.
Core Problem
Existing 3D-LLMs rely on computationally heavy multi-view image projections or fail to handle ambiguity in cluttered scenes when relying solely on text instructions.
Why it matters:
- Projecting 2D features to 3D space creates huge computational overhead and ignores essential geometric properties of the scene
- Plain text instructions often lead to ambiguities in complex, cluttered 3D environments where multiple similar objects exist
- Specialist models (built for one task like QA or Captioning) struggle to scale or generalize compared to LLM-based approaches
Concrete Example:
In a cluttered room with multiple chairs, the text instruction 'describe the chair' is ambiguous. LL3DA allows a user to click on a specific chair (visual prompt) to precisely identify the target for the model to describe.
Key Novelty
Large Language 3D Assistant (LL3DA)
- Integrates visual prompts (clicks, bounding boxes) alongside text instructions to create 'interaction-aware' 3D scene embeddings
- Uses a Multi-Modal Transformer (similar to Q-Former) to bridge the gap between permutation-invariant point clouds and the ordered, causal embedding space of LLMs
- Directly processes point clouds rather than relying on multi-view 2D image feature projection, preserving geometry and reducing compute
Architecture
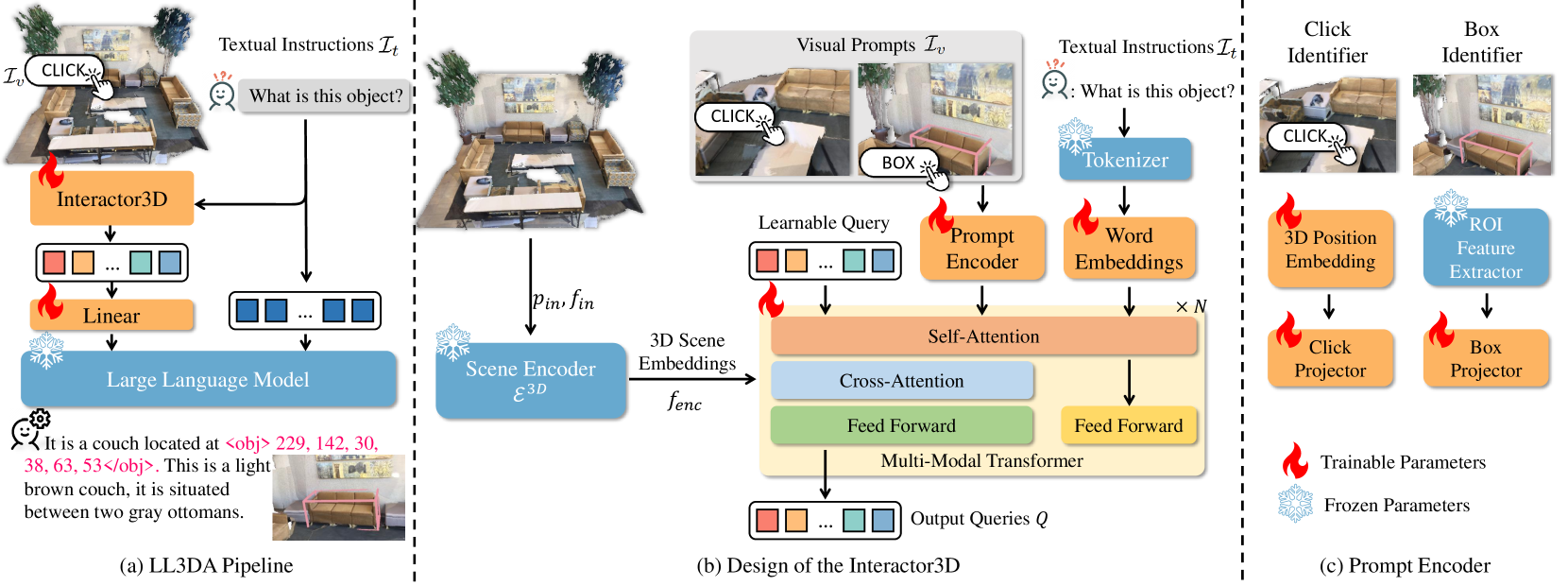
The overall architecture of LL3DA, detailing the Interactor3D module and its connection to the LLM.
Evaluation Highlights
- Achieves state-of-the-art results on ScanRefer and Nr3D datasets for 3D Dense Captioning (quantitative values cut off in provided text)
- Surpasses various 3D vision-language models on the ScanQA dataset for 3D Question Answering
- Demonstrates capability to handle both 'describe' and 'describe and localize' tasks by leveraging visual prompts to remove ambiguity
Breakthrough Assessment
7/10
Strong conceptual contribution by integrating direct visual prompts (clicks) into 3D-LLMs to solve ambiguity. Moves away from heavy 2D-to-3D projection pipelines.