📝 Paper Summary
Process Supervision
Reasoning-as-Planning
Reinforcement Learning from Feedback
The framework synthesizes process rewards by running offline simulations from intermediate reasoning states to estimate their success rates, then uses these rewards to train a policy via Direct Preference Optimization.
Core Problem
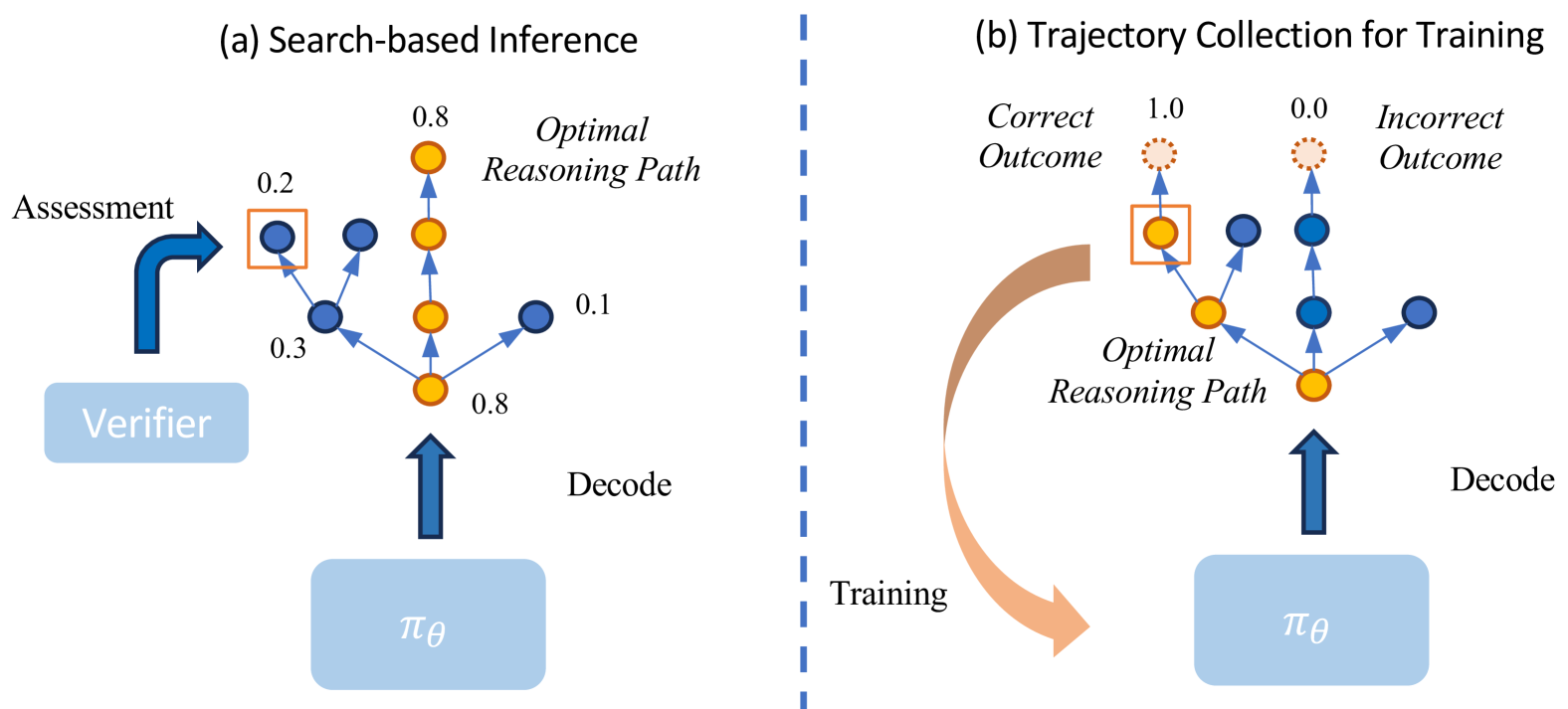
Large Language Models often hallucinate during complex reasoning, and existing solutions like online planning (MCTS) are too slow, while human process supervision is too expensive.
Why it matters:
- Online planning (Reasoning-as-Planning) introduces high latency due to frequent state assessments and large search spaces during inference
- Process supervision (step-by-step feedback) is effective but relies on costly human annotation, making it difficult to scale
- Outcome-only supervision fails to correct flawed reasoning traces that luckily arrive at the correct answer (false positives)
Concrete Example:
In logical reasoning, an LLM might reach a correct conclusion using invalid logic (hallucination). Outcome supervision would reward this, reinforcing the bad logic. Search-based methods like MCTS could catch this but require hundreds of rollouts at inference time, making the system impractically slow.
Key Novelty
Offline Simulation for Process Reward Synthesis + DPO
- Instead of expensive human labels, the system estimates the 'value' of an intermediate reasoning step by simulating multiple completions (Monte Carlo rollouts) and checking how many lead to the correct answer
- These estimated values train a Process Reward Model (PRM), which scores full trajectories
- The policy model is then optimized using Direct Preference Optimization (DPO) on pairs of trajectories ranked by these synthesized process rewards, avoiding unstable PPO training
Architecture
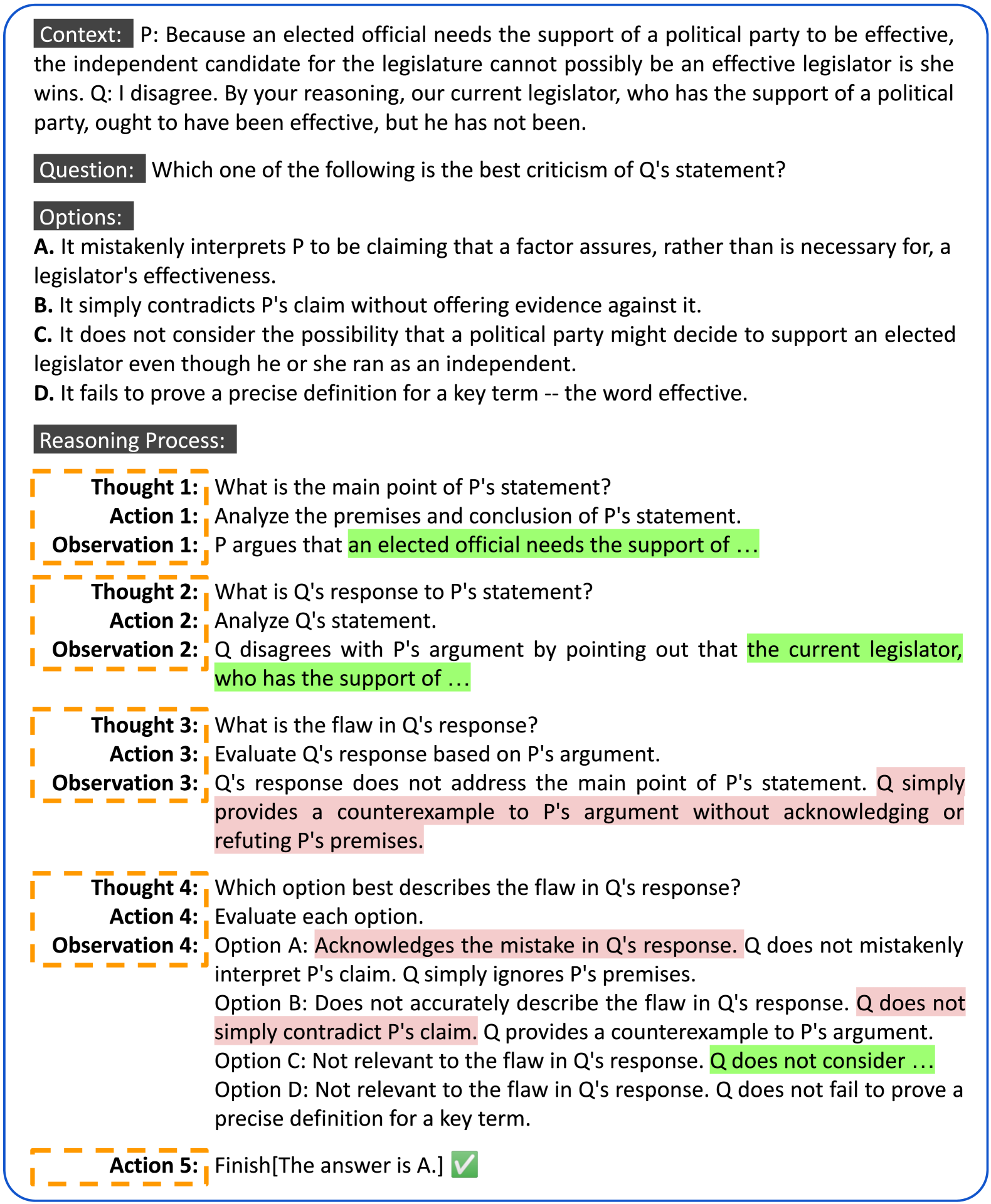
Illustration of the reasoning process as a Markov Decision Process (MDP) using the ReAct format
Evaluation Highlights
- Surpasses strong counterparts like GPT-3.5-Turbo on challenging logical reasoning benchmarks using a 7B parameter model
- Demonstrates significant improvements over robust baseline models on logical and mathematical reasoning tasks
- Reduces reliance on human annotations by synthesizing process rewards automatically via outcome-guided simulation
Breakthrough Assessment
7/10
Clever combination of offline simulation (to replace human process supervision) and DPO. Effectively moves the compute cost of 'planning' from inference time to training time.