📝 Paper Summary
3D Scene Understanding
Physics-aware Generation
Motion Planning
SceneDiffuser unifies 3D generation, optimization, and planning into a single framework where physics constraints and task goals act as differentiable guidance during a diffusion-based denoising process.
Core Problem
Existing 3D scene understanding models treat generation, optimization, and planning as disparate tasks, leading to mode collapse in generation and inconsistent or physically implausible results when applying post-hoc optimization.
Why it matters:
- Generative models like cVAEs often ignore 3D scene conditions (posterior collapse), resulting in objects penetrating walls or floating
- Separating planning from generation prevents agents from utilizing learned data priors for long-horizon tasks, causing failures in novel scenes
- Post-processing outputs with physics optimizers is slow and often breaks the semantic consistency of the original generation
Concrete Example:
A cVAE might generate a human pose that intersects with a sofa. Applying a separate physics optimizer might snap the human to the surface but result in an unnatural, twisted posture because the optimizer doesn't understand human kinematics.
Key Novelty
Unified Diffusion-based Sampling for 3D Tasks
- Models 3D trajectories as a diffusion process, replacing ad-hoc planners and optimizers with a single iterative sampling loop
- Injects physics (collision/contact) and goals (target location) as differentiable guidance gradients at each denoising step, rather than as hard constraints or post-processing
- Uses the forward diffusion process as data augmentation to cover diverse modes, mitigating the posterior collapse common in cVAE baselines
Architecture
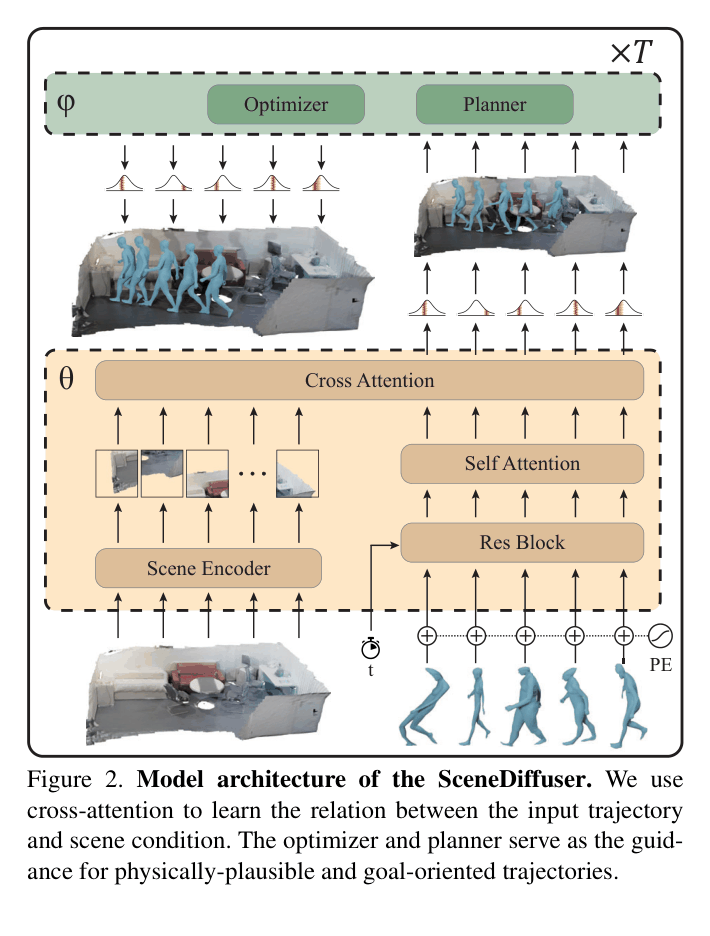
The SceneDiffuser architecture showing how scene conditions and trajectories interact via attention mechanisms.
Evaluation Highlights
- Achieves 49.35% physically plausible rate in human pose generation, surpassing cVAE baselines (14.64%) by +34.7 percentage points
- Attains 71.27% success rate in dexterous grasp generation where cVAE with test-time optimization fails completely (0.00%) due to strict physics checks
- Outperforms Behavior Cloning (0% success) and heuristic planners (13.5%) in 3D navigation path planning with a 73.75% success rate on unseen scenes
Breakthrough Assessment
8/10
Significantly unifies three distinct 3D tasks into one elegant framework with massive empirical gains, particularly in physical plausibility and planning success.

