📝 Paper Summary
Vision-and-Language Navigation (VLN)
Embodied Agents
Zero-shot Navigation
MapGPT enables zero-shot vision-and-language navigation by constructing an online topological map converted into text prompts, allowing GPT-4 to perform global adaptive path planning.
Core Problem
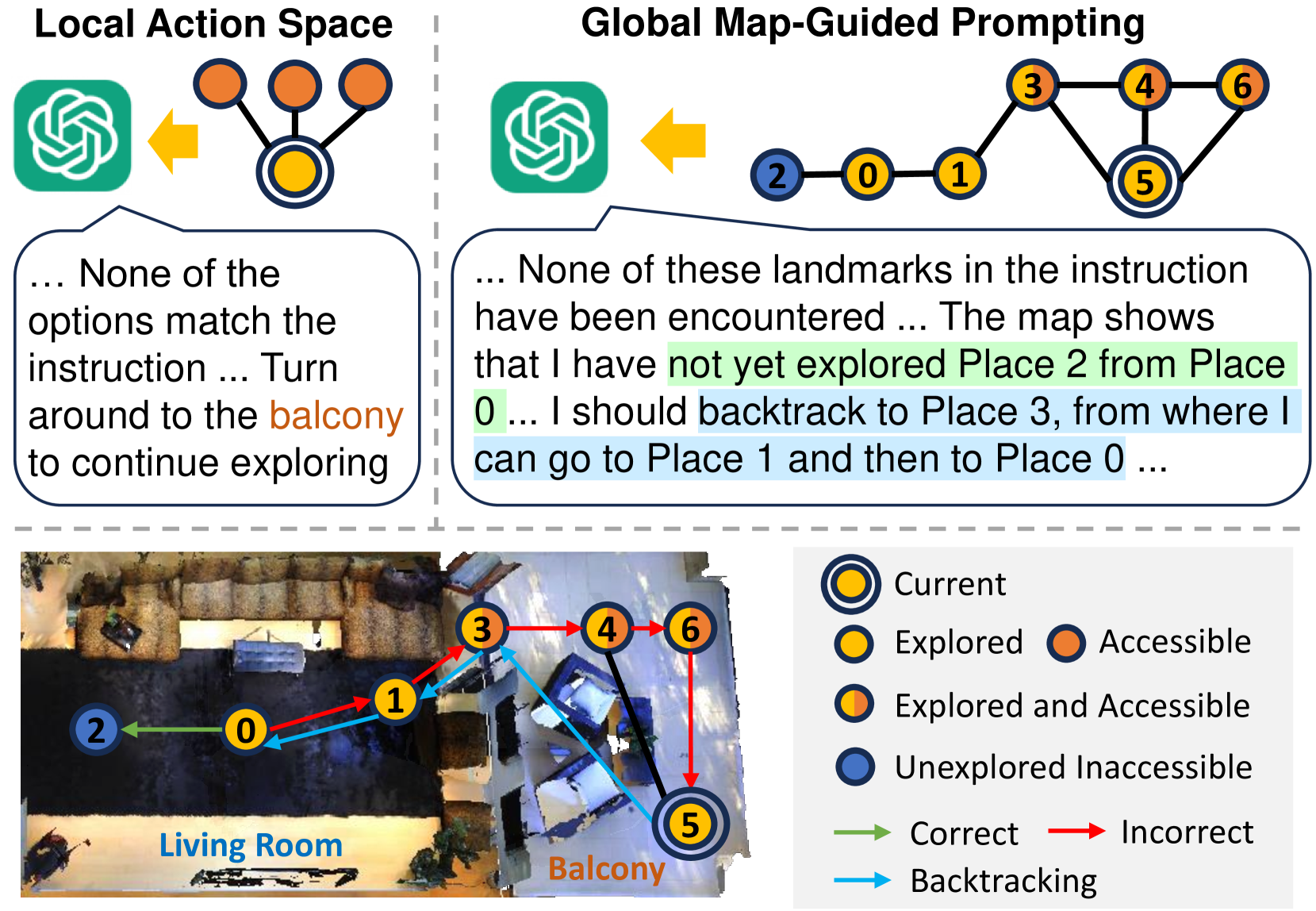
Existing zero-shot VLN agents rely solely on local observations and lack a global memory or map, causing them to wander aimlessly when they make mistakes or need to backtrack.
Why it matters:
- Without a global view, agents cannot correct erroneous exploration or perform strategic backtracking, leading to navigation failure
- Current methods rely on complex multi-expert systems to summarize history, which is inefficient and leads to information loss compared to a unified global map approach
Concrete Example:
When an agent relying on local action spaces realizes it has explored a wrong path, it can only continue to explore the immediate surroundings randomly because it does not remember the structure of previously visited nodes to backtrack effectively.
Key Novelty
Map-Guided Prompting with Adaptive Planning
- Converts an online topological graph (nodes and edges) into a linguistic text format (e.g., 'Place A is connected with Place B') that LLMs can understand directly without GPS coordinates
- Introduces an iterative planning mechanism where the agent outputs a multi-step 'Plan' at each step, updating it dynamically based on the map to support backtracking and systematic exploration
Architecture
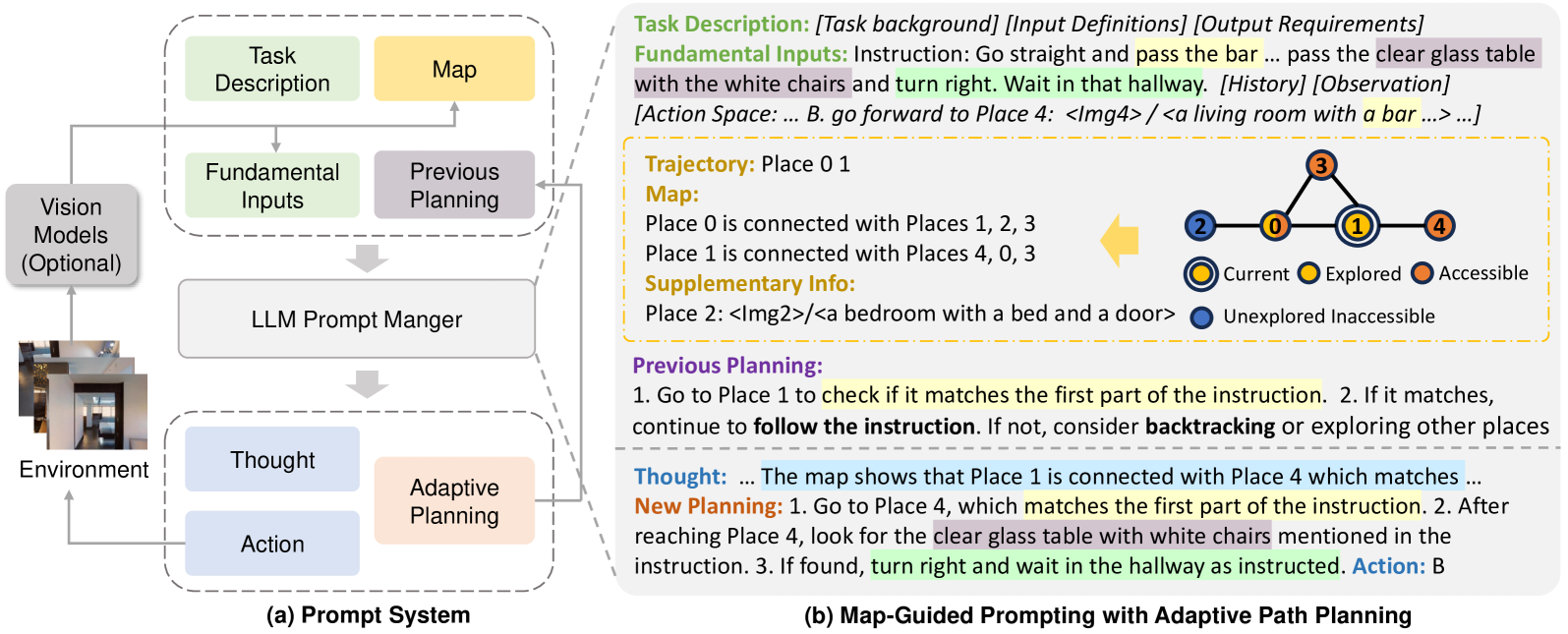
The complete MapGPT pipeline showing how task descriptions, fundamental inputs (History, Observation, Action Space), and the Map are processed by the Prompt Manager and fed into the LLM.
Evaluation Highlights
- Achieves 31.6% Success Rate (SR) on the REVERIE benchmark, surpassing some supervised learning-based methods
- Reduces token consumption significantly: ~672 input tokens per step compared to NavGPT's 2,465 tokens, due to a streamlined single-expert prompt design
- Reported ~10% and ~12% improvements in Success Rate (SR) on R2R and REVERIE datasets respectively compared to state-of-the-art zero-shot agents
Breakthrough Assessment
8/10
Strongly addresses the 'memory' and 'global view' deficit in zero-shot LLM agents by successfully encoding topological maps into text prompts, achieving SOTA zero-shot results.