📝 Paper Summary
World Models for Autonomous Driving
Video Generation
End-to-End Planning
Drive-WM is a multiview world model that generates consistent driving videos conditioned on actions and layouts, enabling safe end-to-end planning by visually simulating future outcomes.
Core Problem
Existing end-to-end autonomous driving planners struggle with out-of-distribution scenarios and lack the ability to visually foresee the consequences of their actions before execution.
Why it matters:
- Planners trained purely on expert trajectories often fail when the vehicle deviates from the center line or faces unseen obstacles
- Current world models are limited to low-resolution or single-view generation, preventing comprehensive 3D environmental understanding required for safe driving
- Generating consistent multiview videos remains an open problem, with existing methods suffering from temporal and spatial inconsistencies
Concrete Example:
When an ego vehicle deviates laterally from the center line (an out-of-distribution state), a standard end-to-end planner may fail to correct the trajectory. Drive-WM can simulate the visual future of this state, allowing the planner to evaluate the risk and select a safer trajectory.
Key Novelty
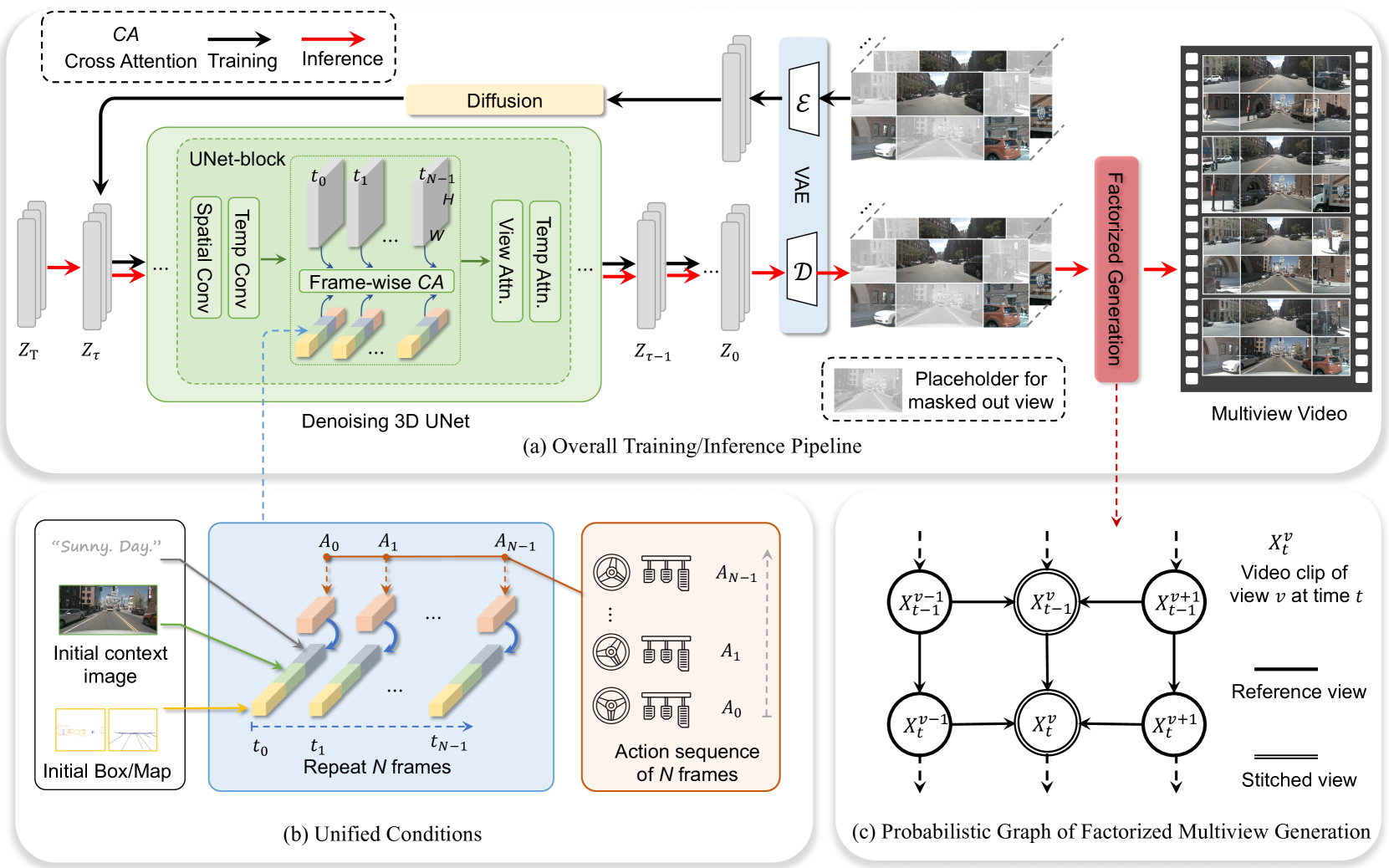
Drive-WM (Multiview World Model for Driving)
- Factorized Joint Modeling: Generates multiview videos by first modeling reference views and then generating intermediate 'stitched' views conditioned on neighbors to ensure spatial consistency
- Unified Condition Interface: flexible integration of heterogeneous conditions (text, layout, actions, images) into a shared embedding space for the diffusion model
- Planning via Generation: Evaluates candidate trajectories by generating corresponding future videos and selecting the best path based on image-based rewards
Architecture

The architecture of the Multiview World Model, detailing the Temporal and Multiview Layers within the UNet.
Evaluation Highlights
- Achieves 3.65 FID (Fréchet Inception Distance) on nuScenes video generation, outperforming state-of-the-art DriveDreamer (5.21)
- Superior multiview consistency with a matching score of 0.63, surpassing Gaia-1 (0.42) and DriveDreamer (0.55)
- Enhances planning robustness: Reduces collision rate by roughly half compared to UniAD in out-of-distribution scenarios (deviation from center line)
Breakthrough Assessment
8/10
First world model to successfully demonstrate multiview video generation for end-to-end planning with high consistency. A significant step towards safe model-based autonomous driving.