📝 Paper Summary
Chain of Thought (CoT) reasoning
Classical Planning
Generalization analysis
Chain of Thought prompting in planning tasks relies on pattern matching rather than learning general algorithms, failing to generalize as problem complexity increases beyond the provided examples.
Core Problem
LLMs often fail to generalize reasoning capabilities out-of-distribution; while Chain of Thought (CoT) claims to teach models algorithmic procedures via examples, it is unclear if models actually learn the algorithm or just mimic patterns.
Why it matters:
- Prevalent belief suggests CoT 'unlocks' reasoning, potentially leading to misplaced confidence in LLMs for critical planning tasks
- The trade-off between the heavy human labor required to craft specific CoT prompts and the resulting brittle performance is poorly understood
- Existing benchmarks (like GSM8K) often lack systematic scaling mechanisms, masking the failure of LLMs to generalize to larger instances of the same problem type
Concrete Example:
A model provided with CoT examples of how to stack 3 blocks can solve 3-block problems, but when asked to stack 4 or more blocks using the exact same logic, its accuracy plummets to near zero.
Key Novelty
Systematic Granularity Stress-Test
- Evaluates CoT performance across a spectrum of prompt specificity, from general 'progression proofs' applicable to any problem, down to highly specific 'table-to-stack' recipes
- Uses the Blocksworld planning domain to mechanically scale problem difficulty (stack height), rigorously testing whether the 'learned' algorithm generalizes to larger instances
Architecture

A conceptual diagram illustrating the 'Target Distributions' of problems versus the 'Expected Generality' of different prompt types.
Evaluation Highlights
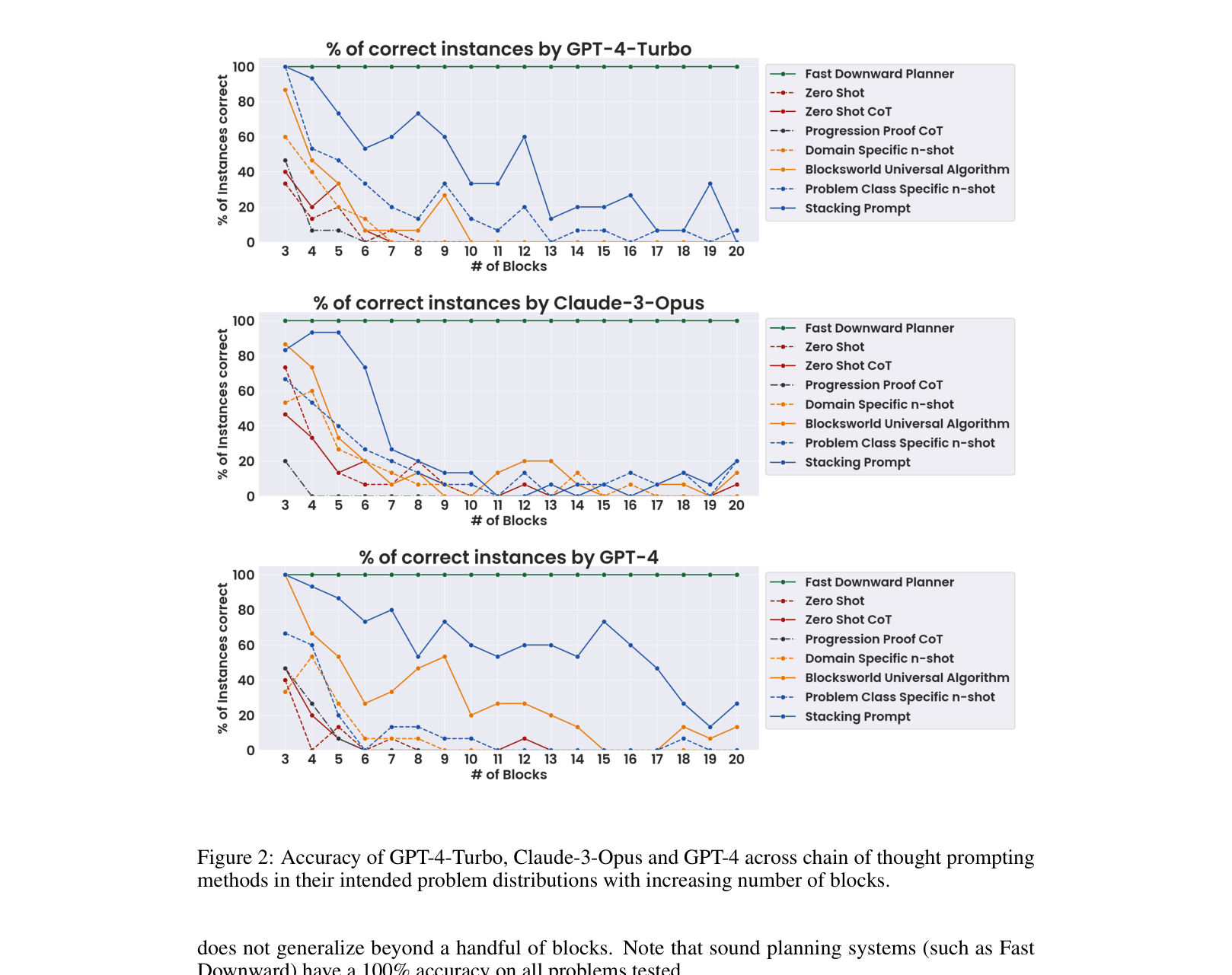
- On 'table-to-stack' Blocksworld tasks, GPT-4 improves from 3.83% (zero-shot) to 59.3% with highly specific CoT prompts, but this gain is brittle
- Performance collapses as the number of blocks increases: accuracy drops from ~60% to near 0% as the target stack height grows from 3 to 20, despite the algorithm remaining identical
- On synthetic arithmetic tasks, CoinFlip accuracy remains high for short sequences but drops below 90% for sequences >31 steps, showing limits to length generalization
Breakthrough Assessment
8/10
A strong negative result that critically re-evaluates a dominant paradigm (CoT). It provides convincing evidence against the 'algorithmic learning' hypothesis for CoT using verifiable planning domains.