📝 Paper Summary
LLM Reasoning
Self-Correction/Self-Verification
Automated Planning
LLMs struggle to self-verify or self-correct in formal reasoning tasks, often performing worse than standard prompting, but external sound verifiers can significantly boost performance even without complex critique.
Core Problem
There is a widespread belief that LLMs can self-critique and improve their own solutions iteratively, assuming verification is easier than generation, but this has not been systematically tested on formal reasoning tasks with ground truth.
Why it matters:
- Current optimism about self-reflection agents (e.g., Reflexion) relies on the assumption that models can accurately spot their own errors, which may be flawed
- Misattributing performance gains to 'self-critique' rather than just iterative guessing obscures the actual source of improvement (often just having a verifier)
- Reliability in reasoning domains (planning, math) is critical, and false confidence in self-correction can lead to compounding errors
Concrete Example:
In Graph Coloring, an LLM might propose a solution where two connected nodes share a color. When asked to verify, it often hallucinates that the constraint is satisfied or identifies non-existent edges, rejecting valid solutions or accepting invalid ones, leading to lower final accuracy than its initial guess.
Key Novelty
Systematic Ablation of Self-Verification
- Separates the roles of the LLM into generator, verifier, and critiquer to isolate where failures occur in iterative loops
- Demonstrates that 'self-correction' often degrades performance due to high false positive/negative rates in the LLM's verification step
- Shows that performance gains in iterative systems come primarily from the presence of a sound external verifier and repeated guessing, not from the semantic content of the critique
Architecture
The iterative prompting architecture used for evaluation, showing the loop between the LLM and the Verifier/Critique modules.
Evaluation Highlights
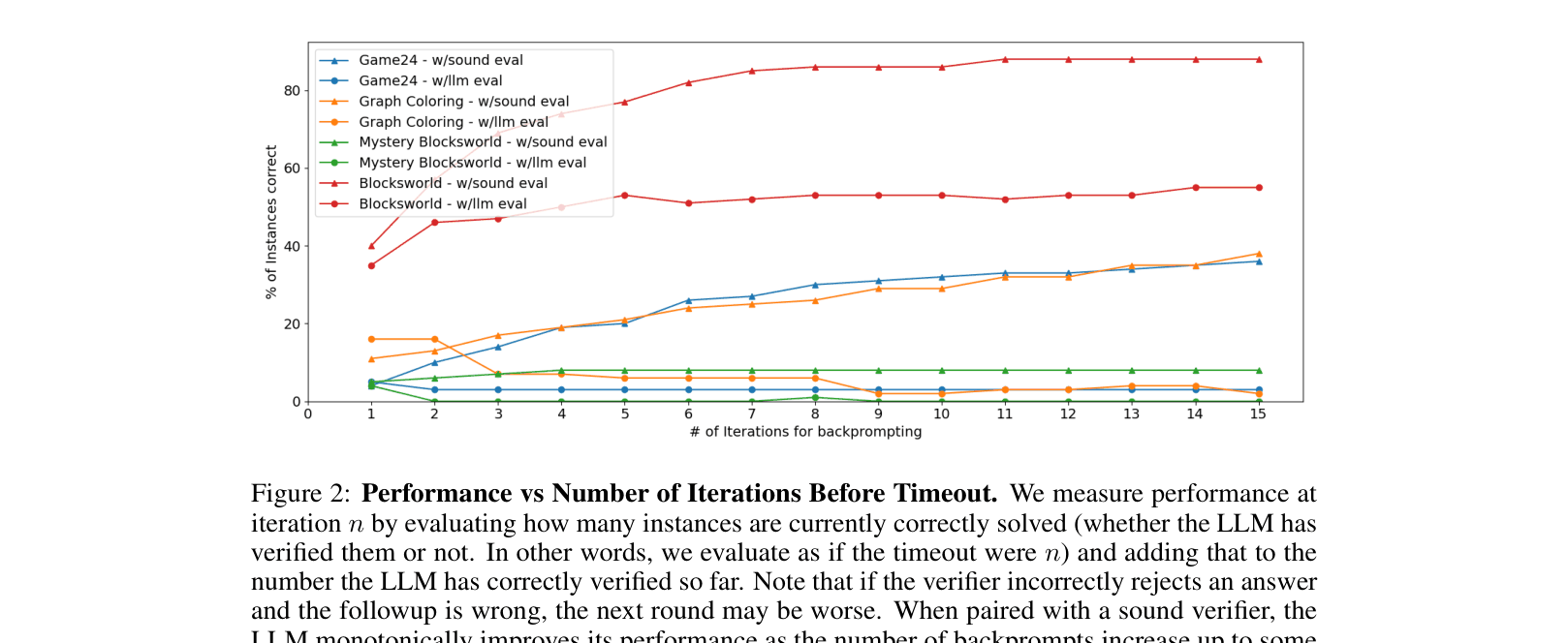
- In Graph Coloring, self-verification (LLM+LLM) degraded accuracy from 16% (standard prompting) to 2%, while a sound verifier boosted it to 38%
- In Mystery Blocksworld, self-verification collapsed performance to 0%, whereas a sound verifier achieved 10%
- Mere sampling (re-prompting the LLM 15 times with a sound verifier but NO feedback/critique) matched or exceeded the performance of complex feedback loops (e.g., 40% vs 37% in Graph Coloring)
Breakthrough Assessment
7/10
Strong negative result that challenges the prevailing narrative of 'emergent self-reflection'. Crucial for grounding agentic AI research, though it primarily evaluates GPT-4 on specific formal tasks.