📝 Paper Summary
Entity Matching (EM)
Cross-Dataset Generalization
LLM Evaluation
Cost-Efficiency Analysis
Fine-tuned small language models (like LLaMA-1B) can match the accuracy of massive commercial LLMs (like GPT-4) in cross-dataset entity matching while costing orders of magnitude less to deploy.
Core Problem
Cross-dataset entity matching requires identifying matching records in unseen target datasets without labeled training examples or reliable schema information, a scenario where traditional supervised methods fail.
Why it matters:
- Crucial for automated cloud data integration services (e.g., AWS Glue) that process millions of heterogeneous tables without forcing users to manually label data
- Current LLM-based solutions are often evaluated on limited datasets (e.g., only e-commerce) without considering domain shifts or deployment costs
- High inference costs of commercial LLMs (e.g., GPT-4) make them impractical for large-scale data cleaning pipelines that process millions of records
Concrete Example:
A matcher trained on Amazon electronics data must identify duplicates in a restaurant dataset without seeing any restaurant examples. An overly specific small model might fail on the unseen vocabulary, while a large model might be too expensive to run on the entire restaurant database.
Key Novelty
Systematic Cross-Dataset Evaluation & Cost-Quality Analysis
- Implements a 'leave-one-dataset-out' evaluation protocol across 11 diverse benchmarks to rigorous test generalization to unseen domains
- Directly compares fine-tuned small models (SLMs) against prompted large models (LLMs) on both accuracy and varying hardware/cost configurations
- Quantifies the dollar-cost-per-token vs. F1 score trade-off, revealing that SLMs can be 4000x cheaper for similar performance
Architecture
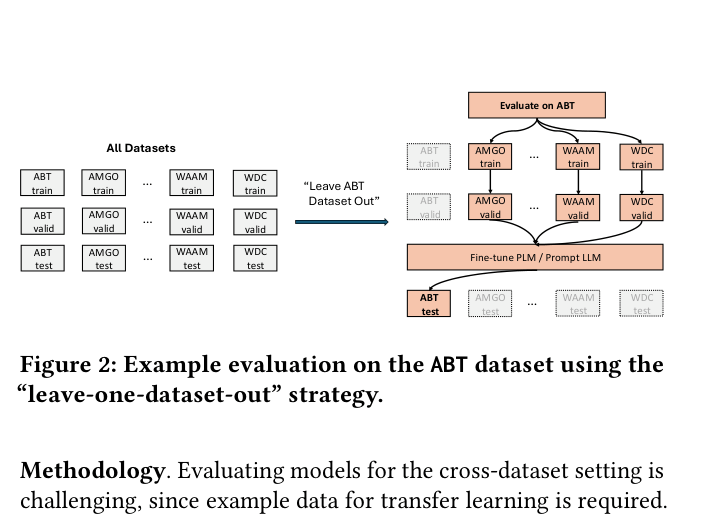
Illustration of the 'Leave-one-dataset-out' evaluation strategy.
Evaluation Highlights
- AnyMatch [LLaMA3.2-1B] achieves 87.5 average F1, matching the performance of MatchGPT [GPT-4] (87.4 F1) despite having ~1000x fewer parameters
- Ditto (110M params) is 4,838 times cheaper per 1k tokens than MatchGPT [GPT-4] while still outperforming GPT-3.5-Turbo on average F1 (72.9 vs 66.0)
- Prompting LLMs with demonstrations (few-shot) degrades performance in cross-dataset settings for smaller models like GPT-4o-mini compared to zero-shot prompting
Breakthrough Assessment
7/10
Comprehensive empirical study that challenges the trend of using massive LLMs for everything. While algorithmic novelty is low, the rigorous benchmarking and cost analysis provide valuable practical guidance for the field.
