📝 Paper Summary
Model-based Control
World Models
Visual Representation Learning
DINO-WM learns a world model on pre-trained DINOv2 patch features from offline trajectories, enabling zero-shot planning for visual goals without reconstruction or task-specific rewards.
Core Problem
Existing world models often require online interaction, task-specific rewards, or computationally expensive pixel reconstruction, limiting their ability to generalize to new tasks zero-shot from offline data.
Why it matters:
- Feed-forward policies require training on all possible scenarios to generalize, which is infeasible
- Online world models require retraining for every new task, limiting efficiency
- Current offline world models rely on strong auxiliary info like expert demos or dense rewards, reducing generality
Concrete Example:
In a maze navigation task, a standard policy trained on specific routes fails when the goal location changes. DINO-WM, trained on random offline trajectories, can plan a path to any visible goal location at test time without retraining.
Key Novelty
Latent Dynamics on Pre-trained Patch Features
- Uses frozen DINOv2 patch embeddings as the state space, leveraging their strong spatial and object-centric priors without learning an observation model from scratch
- Trains a decoder-only Transformer to predict future patch features autoregressively, conditioned on actions
- Performs planning via Model Predictive Control (MPC) in the latent space by optimizing actions to minimize distance to a goal embedding
Architecture
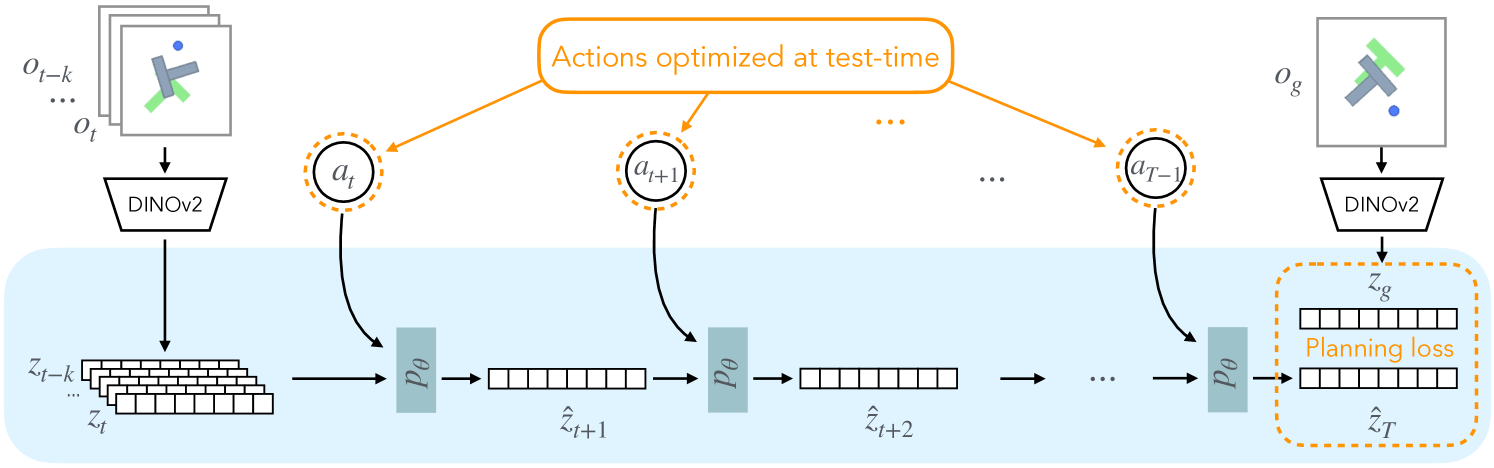
The DINO-WM architecture including the frozen observation model, the causal transition model, and the optional decoder.
Evaluation Highlights
- Improves success rate by 45% on average over prior state-of-the-art (IRIS) on the hardest navigation and manipulation tasks
- Achieves 56% improvement in visual reconstruction metrics (LPIPS) compared to IRIS, indicating higher fidelity future prediction
- Demonstrates zero-shot generalization to new maze layouts and object shapes not seen during specific task training, outperforming baselines that require task-specific learning
Breakthrough Assessment
8/10
Significant step in uncoupling world models from task-specific rewards or online data. Shows that general-purpose visual features (DINOv2) are sufficient for precise physical control via simple latent dynamics.
