📝 Paper Summary
3D Semantic Mapping
Robot Perception and Planning
Open-Vocabulary Scene Understanding
ConceptGraphs constructs 3D scene graphs by fusing 2D segmentation masks into 3D objects, captioning them with vision-language models, and inferring relationships via LLMs to enable open-vocabulary planning.
Core Problem
Existing 3D representations using foundation models produce dense, unstructured per-point features that are memory-inefficient and lack the object-level semantic relationships required for complex planning tasks.
Why it matters:
- Robots need to understand abstract queries (e.g., 'find something to sit on') which requires object-level reasoning rather than just geometric reconstruction
- Dense feature maps scale poorly to large environments and are difficult to update dynamically
- Current 3D scene graphs are typically closed-vocabulary, limiting robots to detecting only a predefined set of object categories trained offline
Concrete Example:
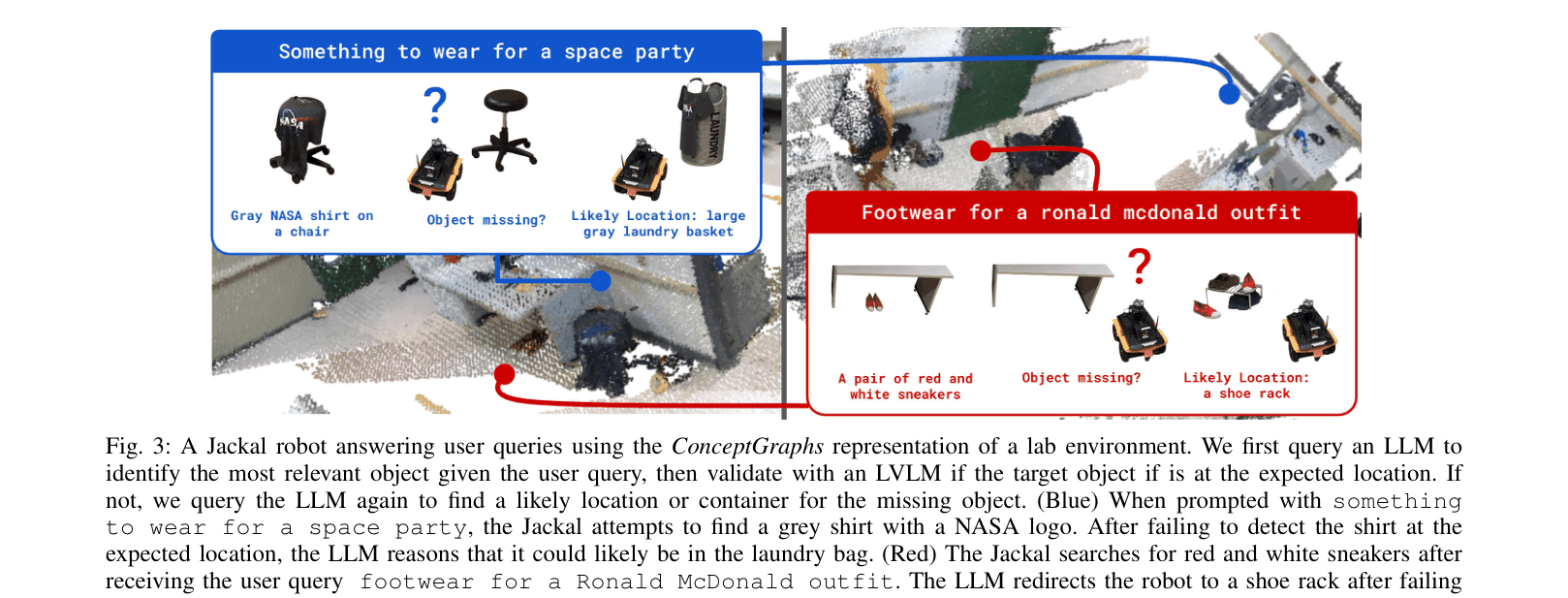
When asked 'My wrist hurts... Anything to help?', a standard object detector might fail if 'wrist brace' isn't in its training set. ConceptGraphs identifies a 'power drill' (via reasoning about the wrist pain) or a 'medical kit' by leveraging LLM knowledge grounded in the map.
Key Novelty
Object-Centric 3D Mapping with LLM-Inferred Edges
- Replaces dense feature clouds with a graph of discrete object nodes, created by fusing class-agnostic 2D segmentation masks into 3D instances
- Uses Large Vision-Language Models (LVLMs) to generate descriptive captions for each 3D object node instead of simple class labels
- Leverages Large Language Models (LLMs) to reason about spatial and semantic relationships between objects (edges) and to parse abstract user queries into actionable plans
Architecture
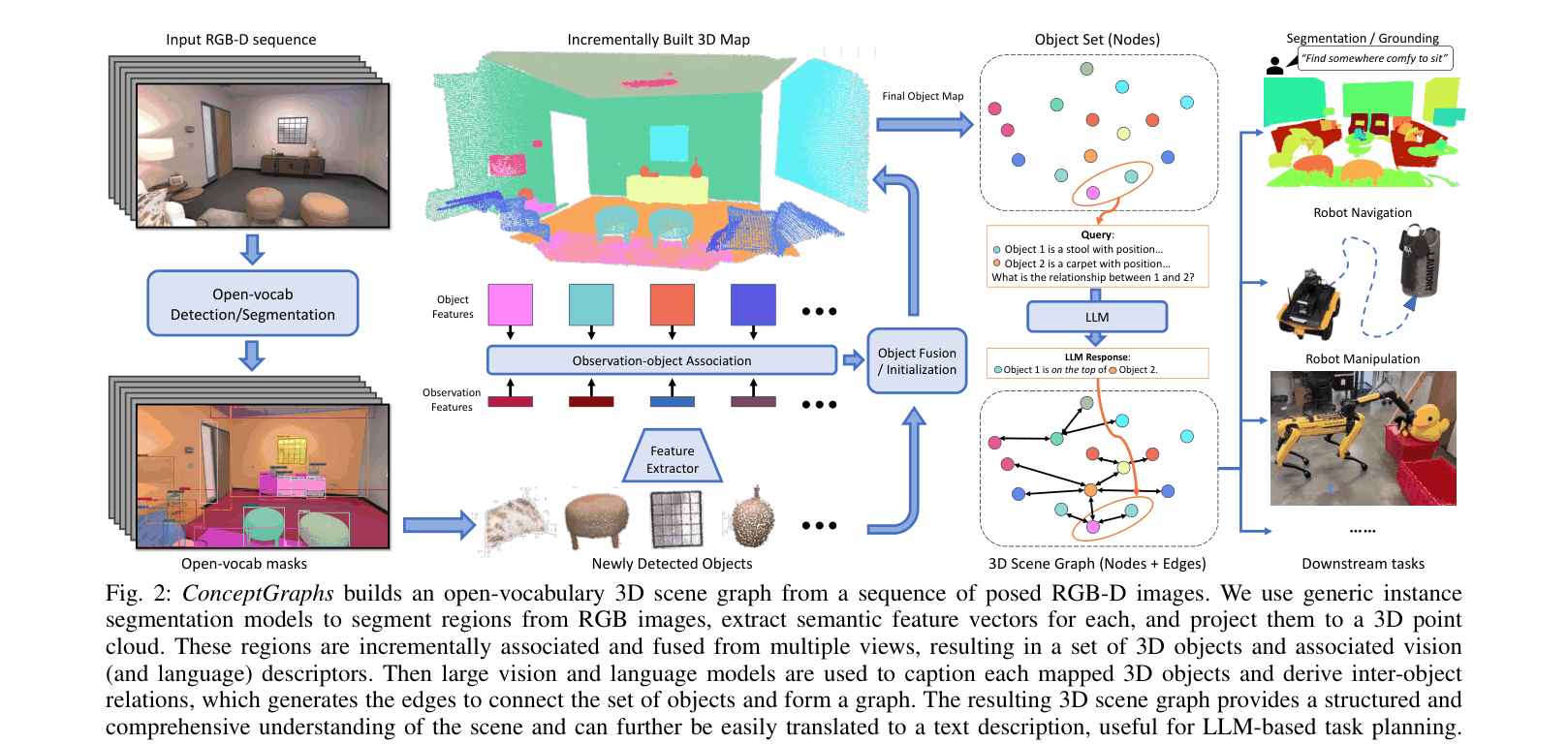
The complete pipeline for building the ConceptGraphs representation from an RGB-D sequence
Evaluation Highlights
- +16.47 mAcc (mean Accuracy) improvement over ConceptFusion on open-vocabulary 3D semantic segmentation on the Replica dataset
- Achieves 0.80 Recall@1 on complex negation queries (e.g., 'something to drink other than soda'), compared to 0.26 for CLIP-based retrieval
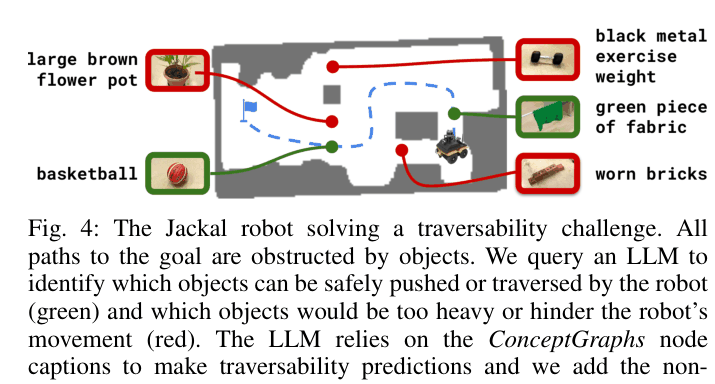
- Demonstrates real-world utility on Jackal (wheeled) and Spot (legged) robots for abstract queries like 'Find something this guy would play with' (locating a basketball)
Breakthrough Assessment
8/10
Significantly advances open-vocabulary 3D mapping by moving from dense fields to structured graphs, enabling complex semantic reasoning (affordances/negation) previously difficult for robots.