📝 Paper Summary
Text-to-Image Generation
Text-Guided Image Editing
RPG is a training-free framework that utilizes Multimodal LLMs to recaption prompts and plan spatial layouts, enabling diffusion models to generate complex compositional images via independent regional processing.
Core Problem
State-of-the-art diffusion models struggle with complex prompts involving multiple objects, attributes, and relationships, often failing to bind attributes correctly or respect spatial constraints.
Why it matters:
- Current layout-based methods provide only rough spatial guidance and handle object overlaps poorly due to latent conflicts
- Feedback-based refinement methods are computationally expensive and require collecting high-quality feedback data
- Achieving precise compositionality (e.g., specific counts, distinct attribute binding) remains a major hurdle for models like DALL-E 3 and SDXL
Concrete Example:
A prompt like 'A green hair twintail in red blouse, wearing blue skirt' requires distinct attribute binding. Standard models might bleed colors (e.g., making the skirt red). RPG decomposes this into specific subregions (green hair, red blouse, blue skirt) to prevent attribute leakage.
Key Novelty
Recaption, Plan, and Generate (RPG)
- Utilizes MLLMs as a 'Global Planner' to break down complex prompts into detailed sub-prompts and assign them to specific spatial subregions via Chain-of-Thought reasoning
- Introduces 'Complementary Regional Diffusion' which generates image latents for each subregion independently and merges them (resize-and-concatenate) at each step, preventing semantic conflict in overlapping areas
Architecture
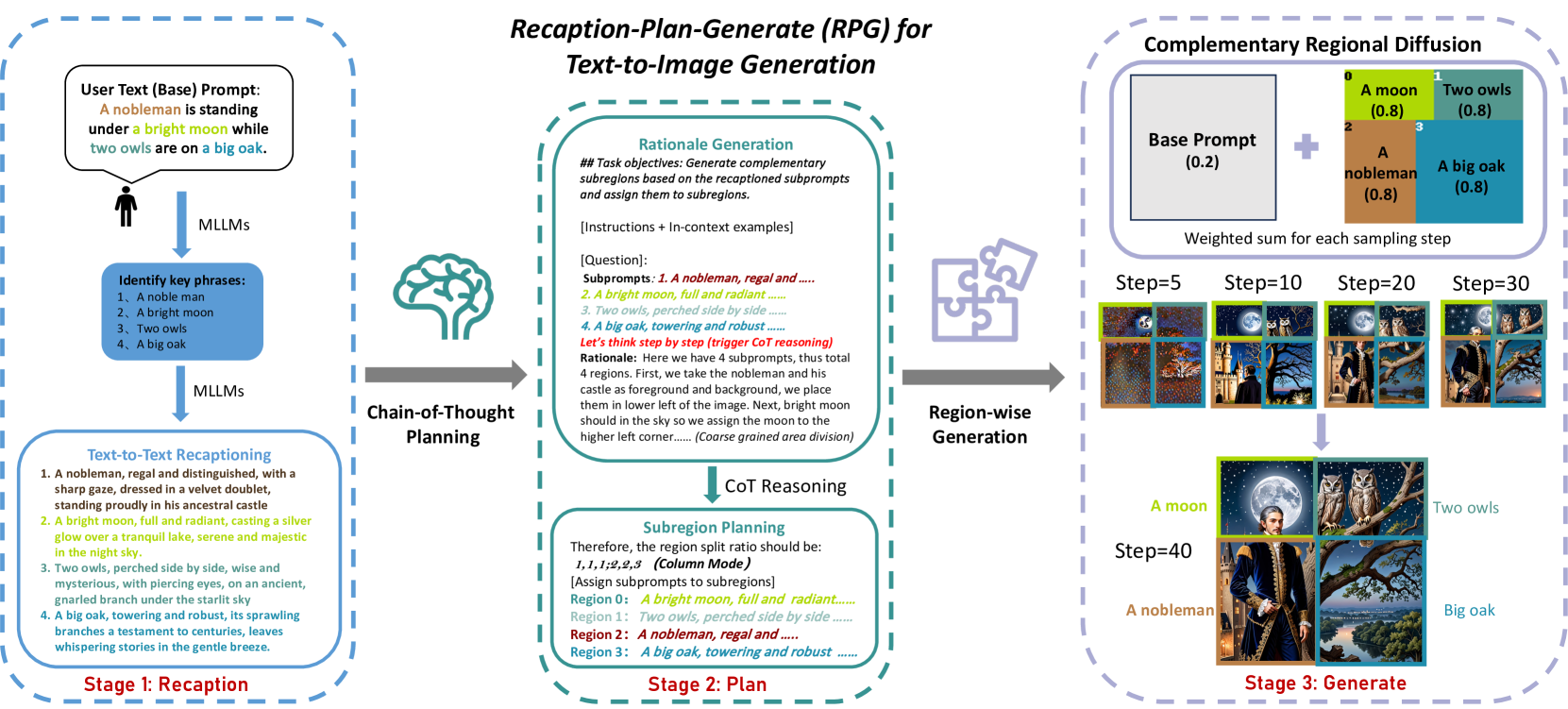
The overall RPG framework illustrating the three main stages: Multimodal Recaptioning, Chain-of-Thought Planning, and Complementary Regional Diffusion.
Breakthrough Assessment
8/10
Proposes a highly logical, training-free mechanism to solve a persistent flaw in diffusion models (compositionality). By effectively 'tiling' the generation process under LLM guidance, it addresses attribute bleeding and spatial neglect without retraining.