📝 Paper Summary
Video Understanding
World Models
Robot Learning
V-JEPA 2 scales masked video modeling to a billion parameters to create a generalist world model that enables fine-grained motion understanding and zero-shot robotic planning without generating pixels.
Core Problem
Learning physical world models usually requires massive interaction data (which is scarce) or generative video modeling (which wastes compute predicting unpredictable pixel details like leaves blowing in the wind).
Why it matters:
- Robot interaction data is expensive and difficult to scale compared to passive internet video
- Generative approaches focus on high-entropy visual details irrelevant to planning, making them computationally inefficient for real-time control
- Previous methods struggle to generalize zero-shot to new robotic environments without task-specific fine-tuning
Concrete Example:
In a generative approach, a model might spend capacity predicting the exact texture of grass (high entropy) rather than the trajectory of a ball. V-JEPA 2 ignores these unpredictable pixel details by predicting in an abstract latent space, focusing only on dynamics relevant for planning.
Key Novelty
Scaled Latent Video World Model (V-JEPA 2)
- Trains a massive video encoder by masking parts of videos and predicting their abstract features (not pixels), forcing the model to learn semantic scene dynamics
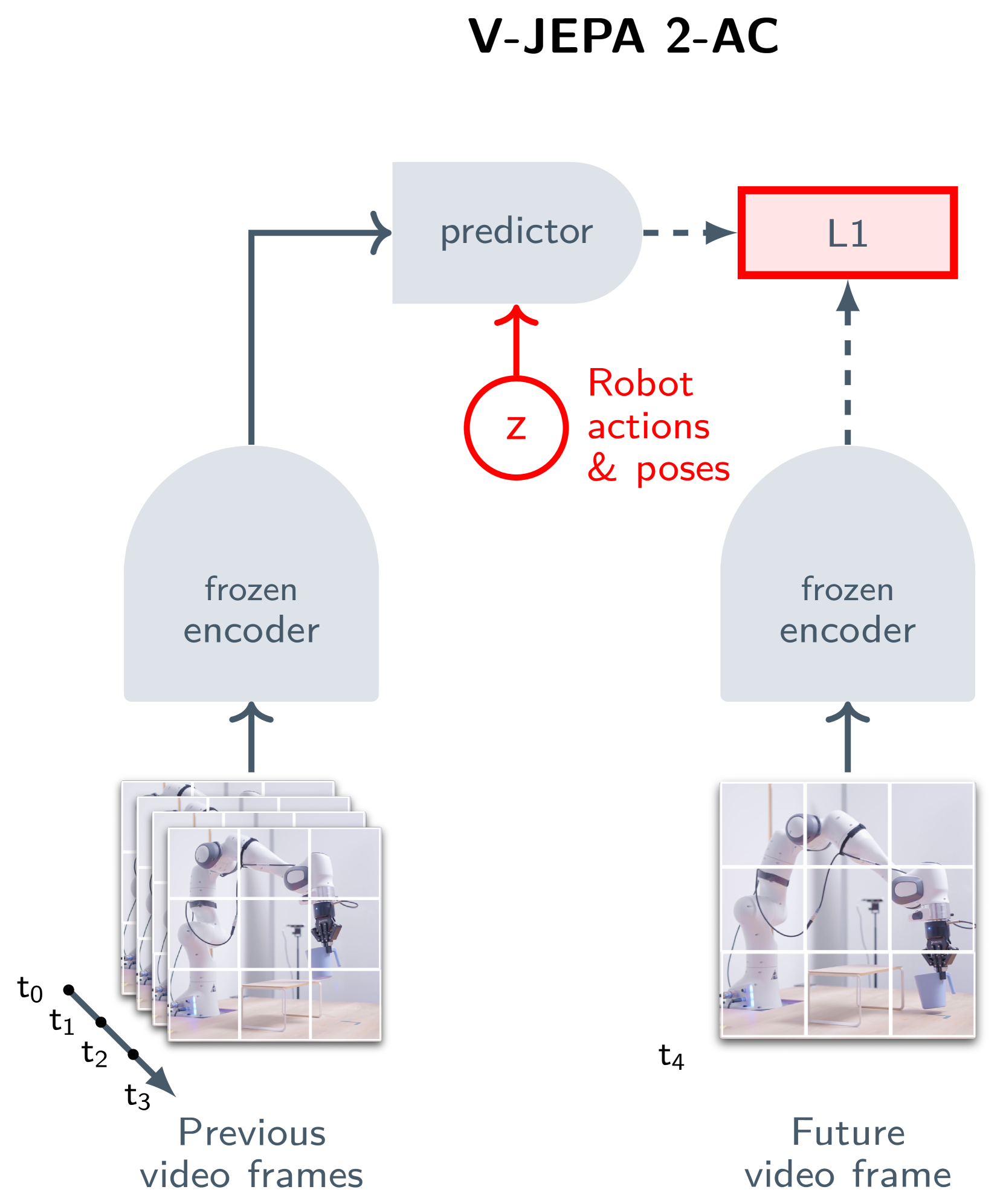
- Post-trains a lightweight 'world model' circuit that predicts future latent states conditioned on actions, enabling planning in the abstract space without video generation
Architecture
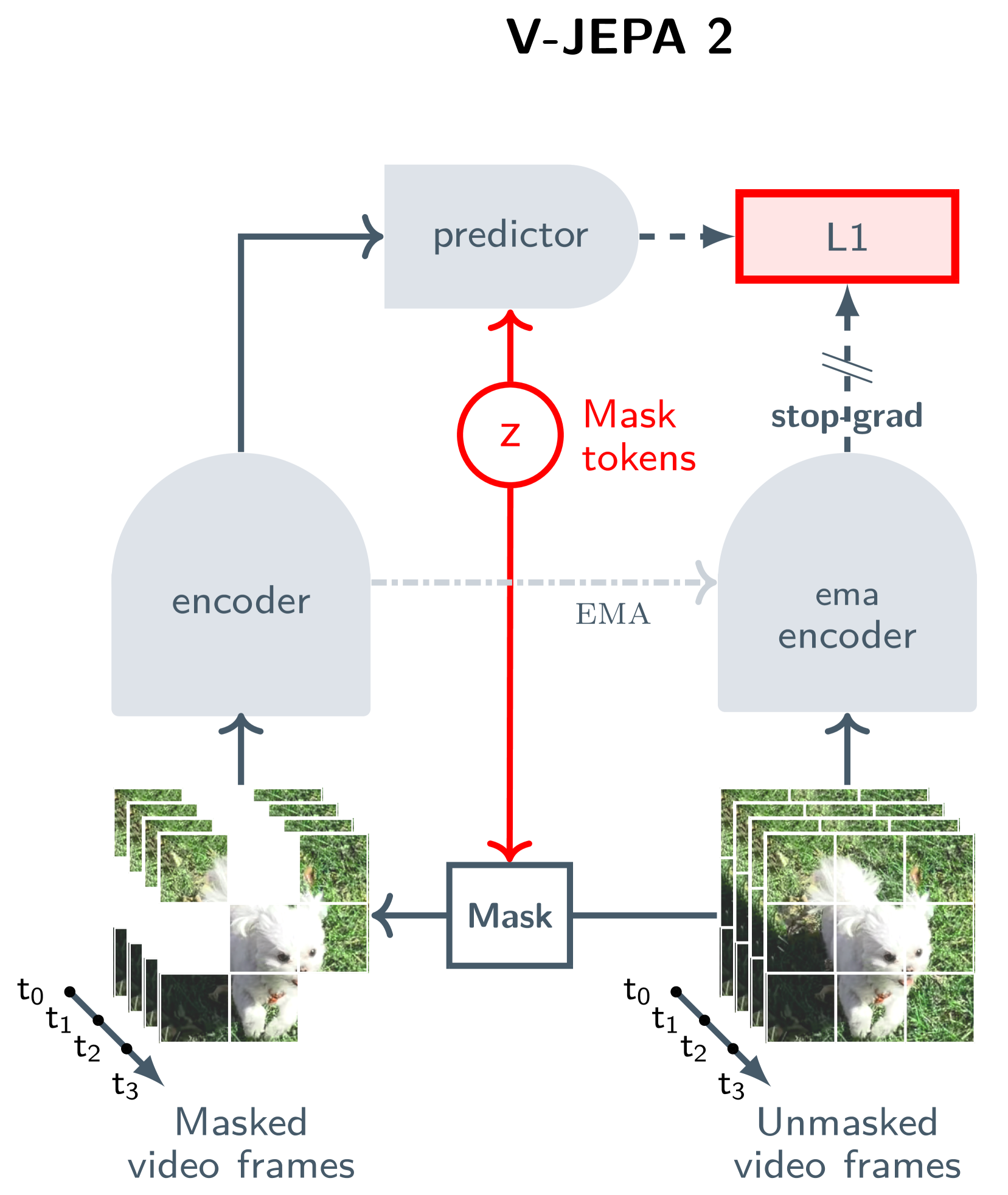
The V-JEPA meta-architecture showing the masking and prediction mechanism.
Evaluation Highlights
- 77.3% top-1 accuracy on Something-Something v2 motion understanding task using an attentive probe
- 39.7 Recall@5 on Epic-Kitchens-100 human action anticipation, a 44% relative improvement over previous state-of-the-art
- 88.2% average accuracy across 6 video understanding tasks when scaling to 64-frame inputs (+4.0 points over ViT-L baseline)
- Zero-shot success on Franka robot manipulation (Pick and Place) using only 62 hours of unlabeled Droid data for world model training
Breakthrough Assessment
9/10
Demonstrates that self-supervised video learning scales effectively to 1B parameters and transfers directly to robotic planning without task-specific rewards, solving a major bottleneck in robot learning.