📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Efficient Reasoning
Chain-of-Thought (CoT)
Heima accelerates MLLM reasoning by condensing verbose Chain-of-Thought steps into single hidden 'thinking tokens' while preserving accuracy and allowing optional textual reconstruction.
Core Problem
Chain-of-Thought reasoning improves performance but requires generating verbose intermediate text, significantly increasing inference costs and latency for large models.
Why it matters:
- Massive parameter counts make generating long CoT sequences computationally expensive
- Real-time applications require faster reasoning without sacrificing the accuracy benefits of CoT
- Existing compression methods often degrade performance on complex reasoning tasks
Concrete Example:
A standard CoT might generate 100+ tokens detailing 'Summary', 'Caption', and 'Reasoning' steps before answering. Heima condenses these entire steps into just 3 'thinking tokens' (<Thinking_of_Summary>, etc.), skipping the text generation.
Key Novelty
Latent Space Chain-of-Thought (Heima)
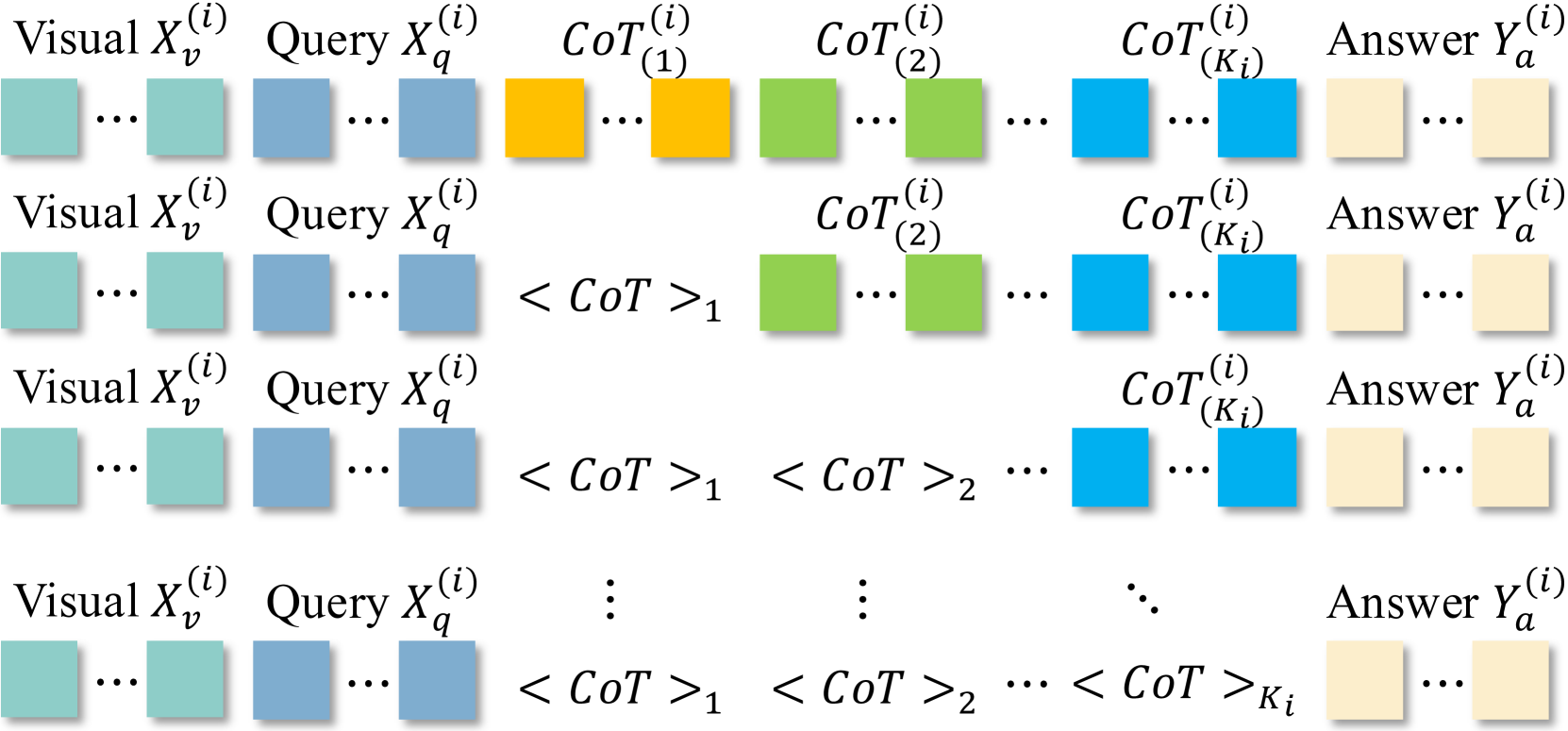
- Encodes entire reasoning steps (like a summary or caption) into a single special 'thinking token' whose last hidden state captures the semantic content
- Uses a progressive training strategy to gradually replace text steps with thinking tokens, ensuring the model learns compact latent representations
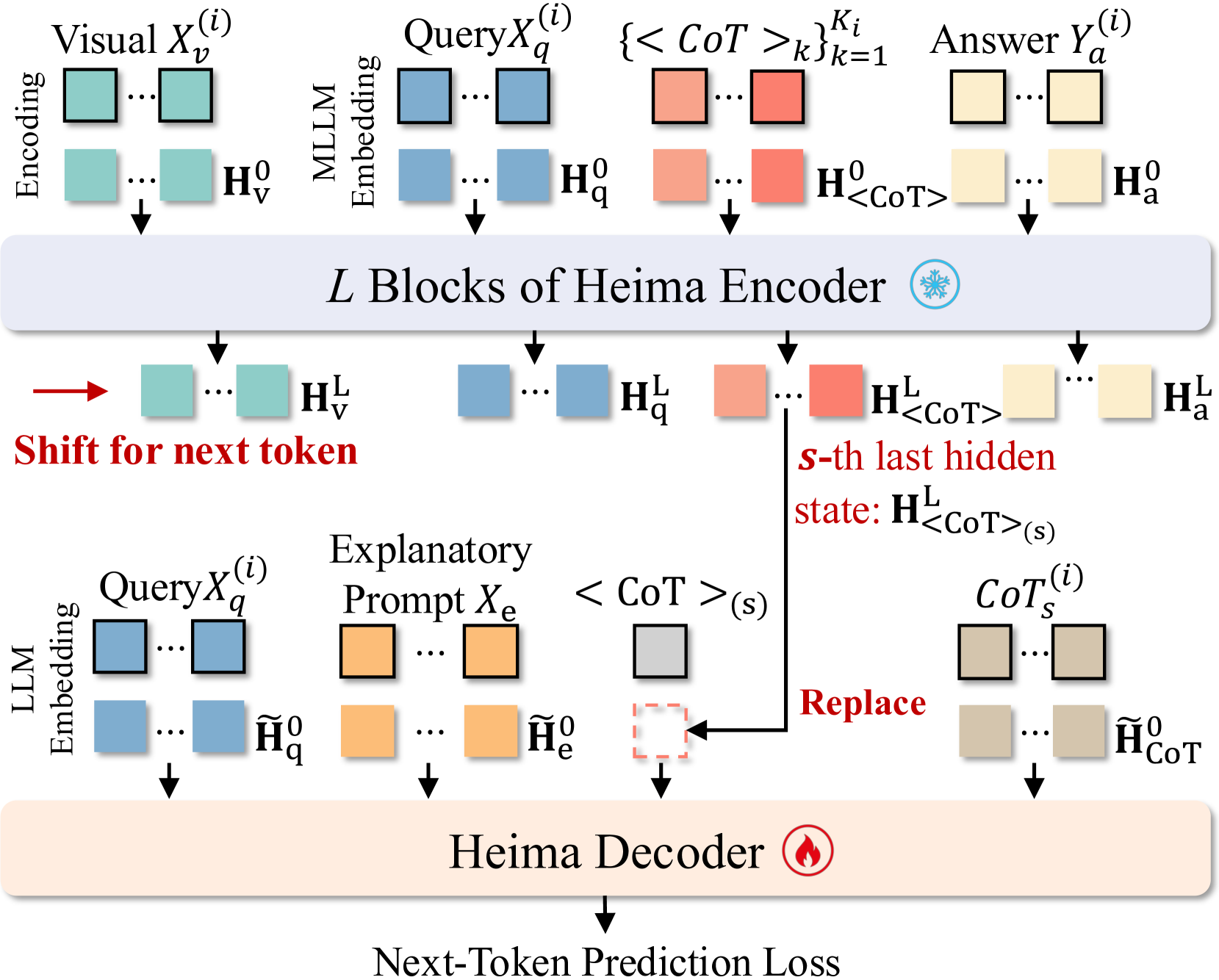
- Decouples reasoning from generation: an Encoder performs fast latent reasoning, while a separate Decoder can translate those latent states back into text for interpretability
Architecture
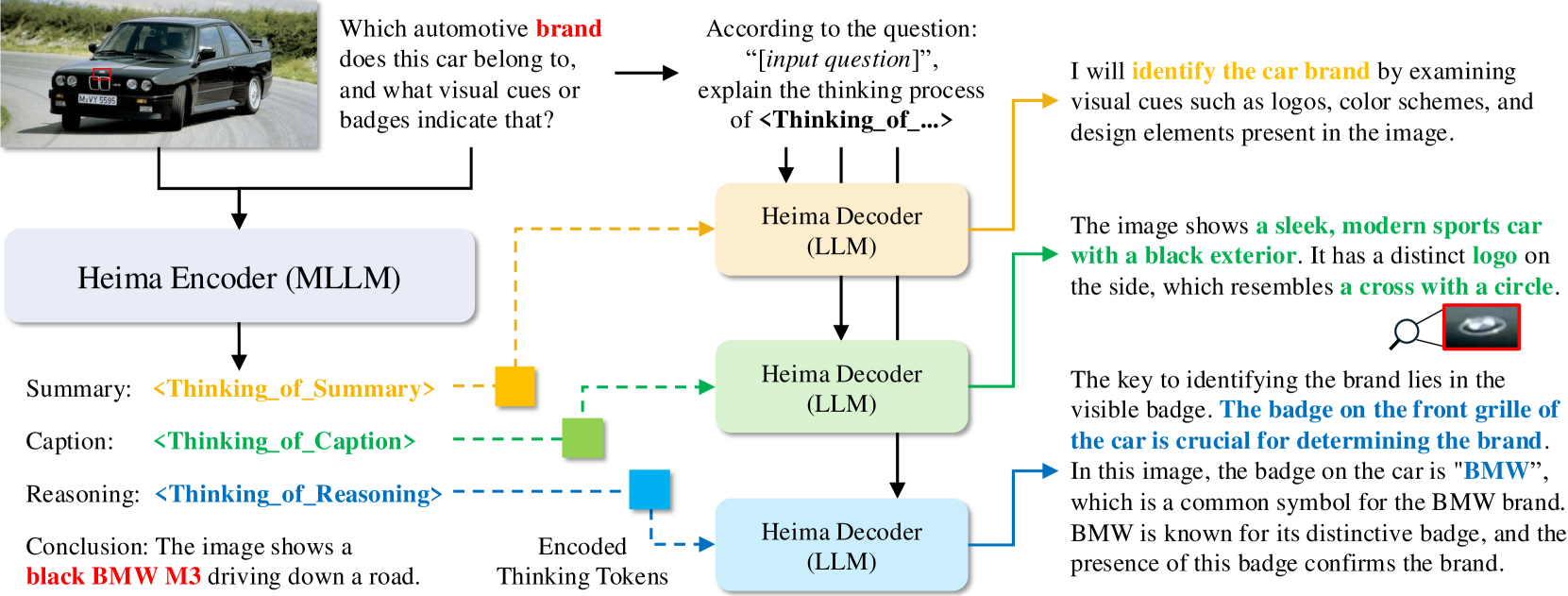
The Heima framework comparing Standard CoT vs. Heima. It shows the Heima Encoder generating 'Thinking Tokens' (e.g., <Thinking_of_Summary>) instead of text, leading directly to the answer. It also shows the Heima Decoder taking the hidden state of these tokens to reconstruct the text.
Evaluation Highlights
- Reduces generated tokens to as little as 6% of the original CoT volume while maintaining accuracy
- Achieves comparable or better zero-shot accuracy on reasoning benchmarks compared to standard verbose MLLMs
- Successfully reconstructs interpretable reasoning chains from hidden tokens using the Heima Decoder, verifying the semantic richness of the compressed states
Breakthrough Assessment
8/10
Significant efficiency gain (94% token reduction) without accuracy loss is a strong result. The ability to decode the latent state back into text addresses the black-box nature of latent reasoning.