📝 Paper Summary
Multi-Agent Reinforcement Learning (MARL)
LLM Reasoning
Self-Play
SPIRAL trains LLMs via online self-play on zero-sum games to automatically generate reasoning curricula, achieving significant transfer gains on math benchmarks without domain-specific data.
Core Problem
Current reasoning improvements depend on unscalable human-curated problem sets and domain-specific reward engineering, while existing self-play methods are limited to simple tasks or offline updates.
Why it matters:
- Manual curation of reasoning problems limits the scale and diversity of training data available for Reinforcement Learning with Verifiable Rewards (RLVR)
- Fixed-opponent training leads to overfitting and static strategies rather than robust reasoning capabilities
- Prior self-play attempts have not successfully leveraged multi-turn competitive dynamics for generalizable chain-of-thought reasoning
Concrete Example:
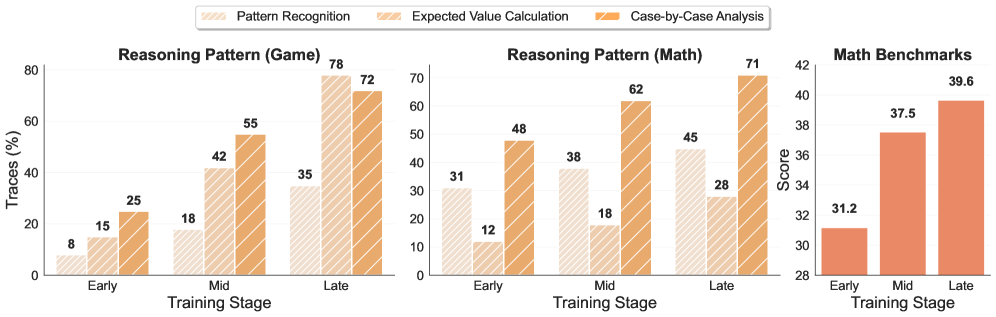
When trained against a fixed opponent (e.g., Gemini), a model learns exploitable static tricks and plateaus; in contrast, SPIRAL's self-play forces the model to continuously adapt to an improving copy of itself, developing transferable skills like 'case-by-case analysis' that apply to math problems.
Key Novelty
Self-Play on Zero-Sum Games for Reasoning Transfer
- Uses multi-turn zero-sum games (like Poker or Negotiation) as a training ground where the model plays against itself, creating an automatic curriculum of increasing difficulty
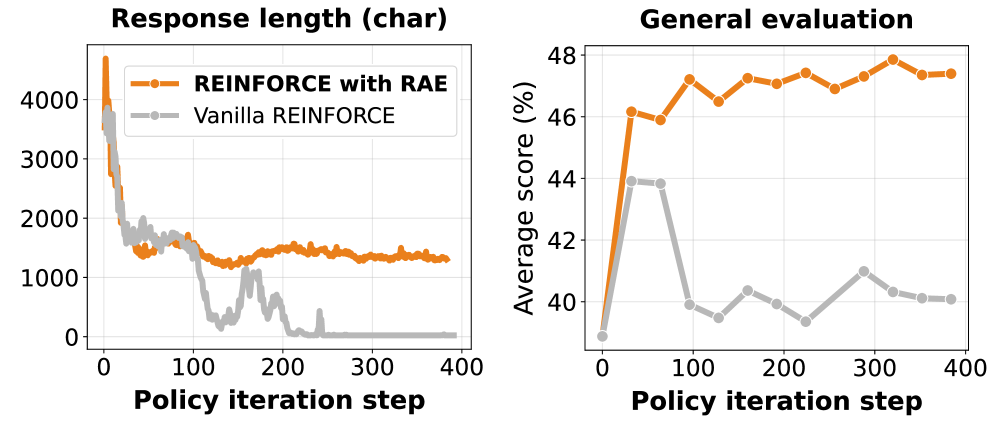
- Implements a fully online, distributed actor-learner architecture that updates the model continuously based on live gameplay rather than static datasets
- Demonstrates that skills learned in simple games (spatial, probabilistic, strategic) transfer directly to academic reasoning benchmarks without training on those benchmarks
Architecture
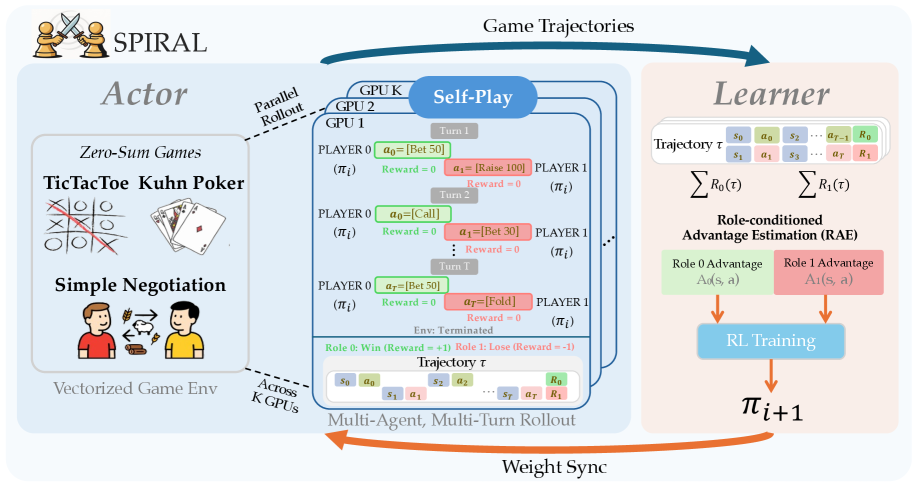
The SPIRAL framework architecture showing the distributed online self-play loop.
Evaluation Highlights
- +10.5% absolute improvement on average across 8 reasoning benchmarks (e.g., MATH500, AIME24) for Qwen3-4B-Base using multi-game training
- Outperforms supervised fine-tuning (SFT) on 25,000 expert game trajectories, proving self-play discovers better strategies than imitation
- Multi-game agents achieve a 59.5% win rate against Gemini-2.0-Flash-Lite, outperforming single-game specialist agents
Breakthrough Assessment
9/10
Demonstrates a scalable path to improving reasoning without domain-specific data or human supervision, a major bottleneck in current RLVR approaches. Strong empirical transfer from games to math is a significant finding.