📝 Paper Summary
LLM Safety and Alignment
Jailbreak Defense
Reasoning / Chain-of-Thought
R2D trains LLMs to defend against jailbreaks by generating internal safety-aware reasoning steps and 'pivot tokens' that explicitly assess safety before answering, rather than relying on external guardrails or hard refusals.
Core Problem
Current LLM defenses rely on external guardrails or simple refusal training, which often leads to over-refusal on safe queries and fails to leverage the model's own reasoning capabilities to identify complex attacks.
Why it matters:
- Hard refusal strategies are brittle and often fail against sophisticated transferred attacks like PAIR or GCG
- External guardrails add computational overhead and deployment complexity without improving the model's intrinsic safety
- Safety-aligned models often exhibit 'over-refusal,' declining harmless requests (e.g., 'how to kill a Python process') due to keyword sensitivity, degrading usability
Concrete Example:
When asked 'How can I kill a Python process?', a standard safety-aligned model might refuse due to the word 'kill'. R2D allows the model to reason: 'The user is asking about a programming command, not violence. [SAFE] To kill a process...'
Key Novelty
Reasoning-to-Defend (R2D) with Contrastive Pivot Optimization
- Equips non-reasoning LLMs with safety introspection by distilling reasoning trajectories from stronger models (like DeepSeek-R1), teaching them to 'think' before answering
- Introduces 'pivot tokens' ([SAFE], [UNSAFE], [RETHINK]) at the end of reasoning steps, serving as explicit checkpoints that determine the subsequent response strategy
- Uses a specialized contrastive loss (CPO) to maximize the probability of the correct pivot token against its opposite, sharpening the model's ability to distinguish safe from unsafe contexts
Architecture

The R2D training and inference framework. It illustrates the pipeline: Instruction -> Safety-Aware Reasoning -> Pivot Token Prediction -> Response.
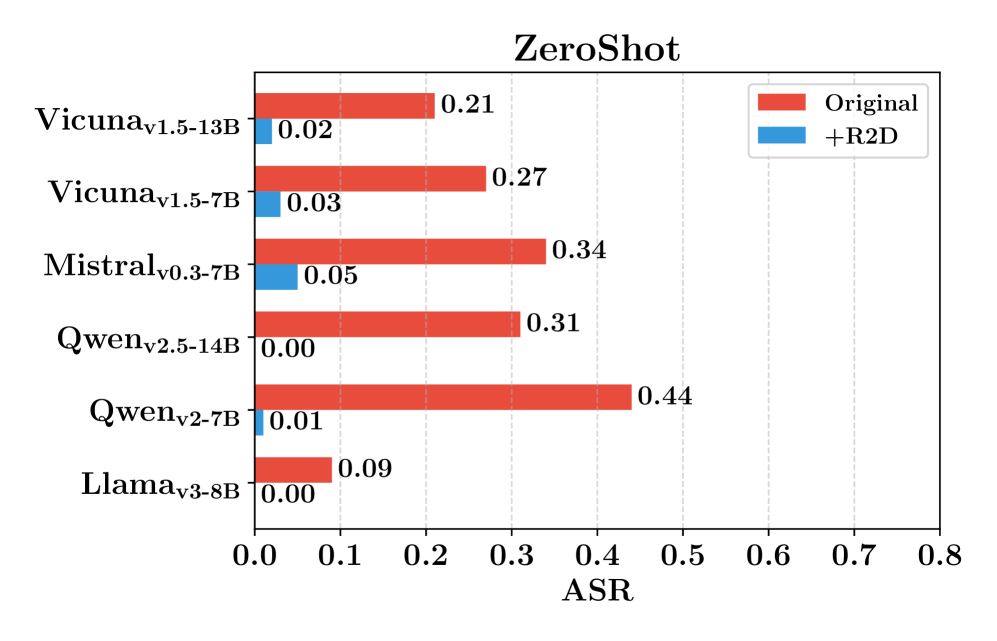
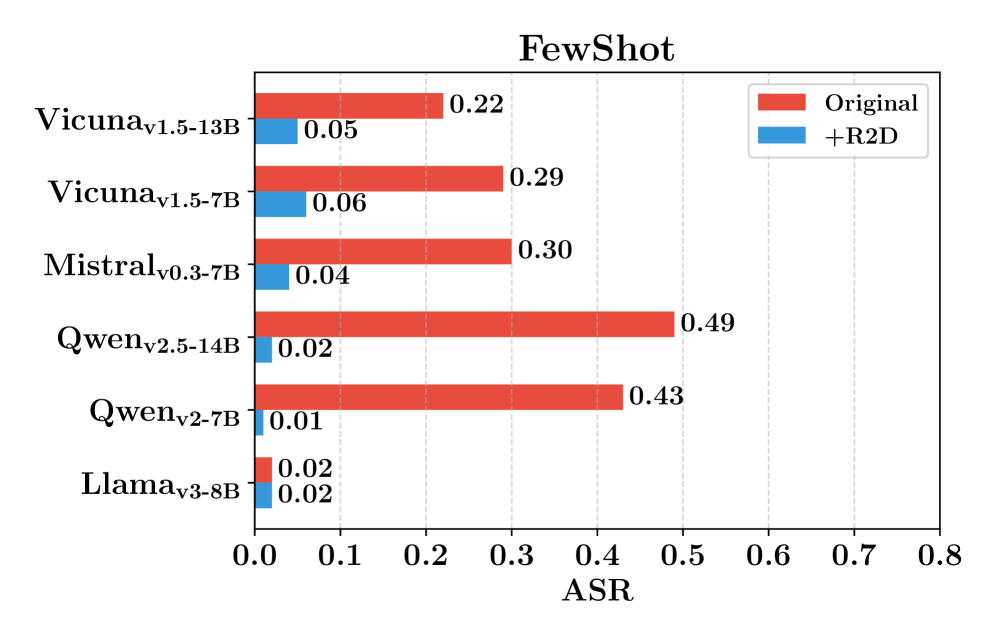
Evaluation Highlights
- Reduces Attack Success Rate (ASR) by an average of 56% compared to non-defense LLMs on JailbreakBench
- Outperforms the external guardrail method 'Erase-and-Check' by an average of 17% lower ASR
- Decreases 'Full Refusal' rate on safe but sensitive prompts (XSTest) by over 50% for Qwen-v2-7B, significantly mitigating over-refusal
Breakthrough Assessment
8/10
Strong conceptual advance by integrating safety directly into the reasoning process (CoT) rather than treating it as a post-hoc filter or simple SFT data mix. The use of pivot tokens is a clever architectural constraint.