📝 Paper Summary
Interpretability of Large Reasoning Models
Mechanistic Interpretability
Chain-of-Thought Reasoning Dynamics
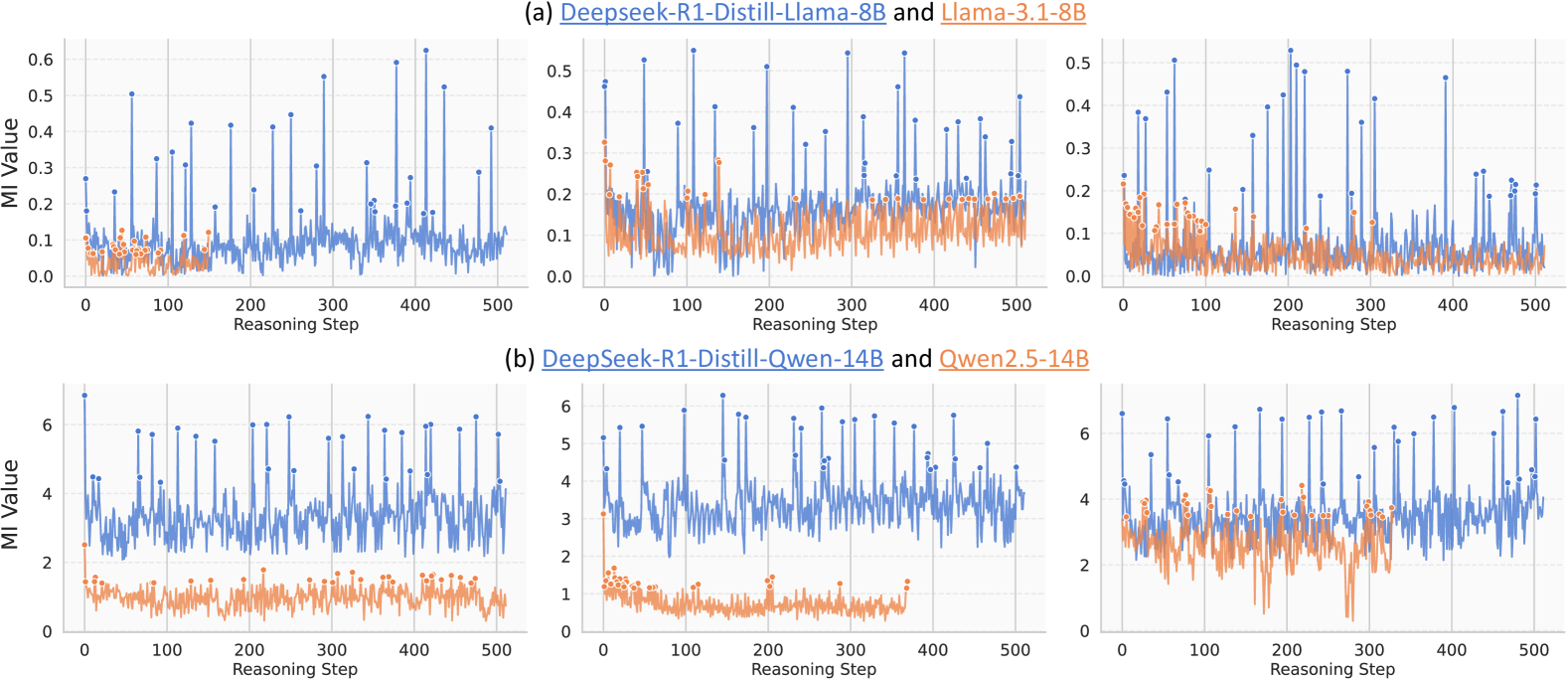
Large Reasoning Models exhibit sparse 'Mutual Information peaks' at specific 'thinking tokens' (e.g., 'Wait', 'Therefore') where internal representations become highly informative of the correct answer, enabling methods to enhance reasoning accuracy.
Core Problem
The internal reasoning mechanisms of Large Reasoning Models (LRMs) like DeepSeek-R1 remain a 'black box', making it unclear which intermediate steps critically influence the final correct answer.
Why it matters:
- Understanding internal dynamics is crucial for interpreting how LRMs achieve complex problem-solving capabilities
- Identifying critical steps can differentiate between meaningful reasoning and mere token generation
- Current methods lack visibility into how information about the ground truth evolves during the step-by-step generation process
Concrete Example:
When an LRM solves a math problem, it generates hundreds of tokens. It is unknown whether all tokens contribute equally or if specific moments, like a self-correction ('Wait, that's wrong'), carry the bulk of the information required to reach the correct solution.
Key Novelty
MI Peaks Phenomenon & Thinking Tokens
- Discovers that Mutual Information (MI) between hidden states and the gold answer spikes suddenly at specific steps (MI Peaks), rather than increasing smoothly
- Identifies that these peaks correspond to semantic 'thinking tokens' (e.g., 'Hmm', 'So') that trigger reflection or transition
- Proposes reusing these high-information states (Representation Recycling) to improve model performance without retraining
Architecture
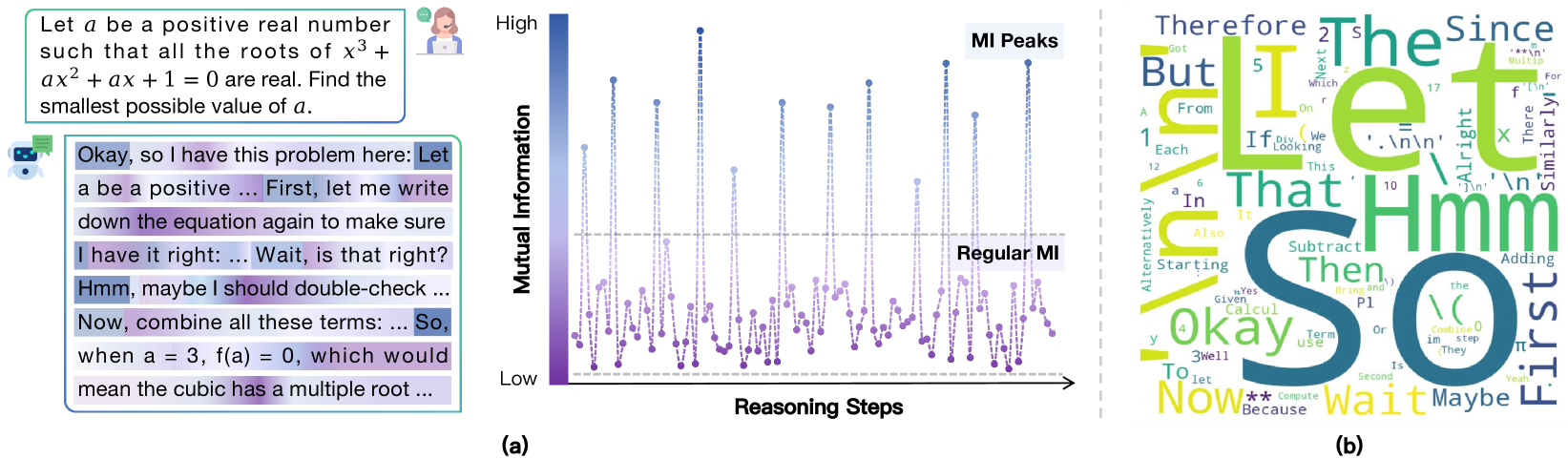
Illustration of the MI Peaks phenomenon in an LRM's reasoning trajectory.
Evaluation Highlights
- DeepSeek-R1-Distill-Qwen-7B exhibits extremely sparse MI peaks, accounting for only 0.51% of total reasoning steps
- Representation Recycling (RR) improves the accuracy of DeepSeek-R1-Distill-LLaMA-8B by 20% relatively on the AIME24 benchmark
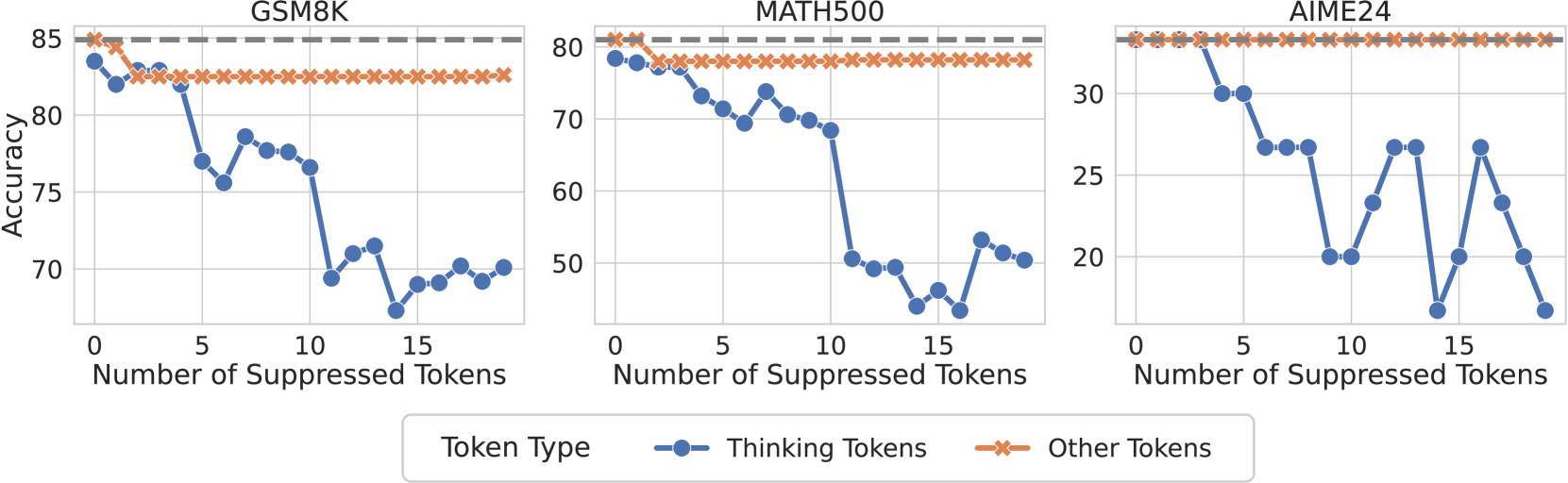
- Fully suppressing 'thinking tokens' significantly harms reasoning performance, whereas random token suppression has minimal impact
Breakthrough Assessment
8/10
Provides a novel information-theoretic explanation for LRM reasoning capabilities and successfully links theoretical MI peaks to specific semantic tokens, leading to practical inference-time improvements.