📝 Paper Summary
Multilingual NLP
Reasoning in LLMs
This survey systematically categorizes the nascent field of multilingual reasoning in Large Language Models, identifying critical gaps in benchmarks, low-resource coverage, and cross-lingual alignment methods.
Core Problem
LLMs trained primarily on English next-word prediction struggle with complex logical reasoning in multilingual contexts due to cross-lingual misalignment, cultural bias, and resource scarcity.
Why it matters:
- Current LLMs perform well in generation but fail at logical inference across languages, creating a disparity between high-resource and underrepresented linguistic communities.
- Crucial domains like finance and healthcare lack dedicated multilingual reasoning benchmarks, limiting the safe deployment of AI systems in global, culturally diverse settings.
- Existing efforts focus predominantly on high-resource languages (English, Chinese, French), leaving typologically distant languages (e.g., Kannada, Quechua) significantly underrepresented.
Concrete Example:
While an LLM might fluently translate a medical query into a low-resource language, it may fail to deduce the correct diagnosis because the logical reasoning path was not aligned with the target language's cultural context or syntax during training.
Key Novelty
Systematic Taxonomy of Multilingual Reasoning
- Provides the first comprehensive taxonomy classifying multilingual reasoning methods into four thrusts: Representation Alignment, Fine-tuning, Prompting, and Model Editing.
- Formalizes desiderata for multilingual reasoning (Consistency, Adaptability, Cultural Contextualization, Cross-Lingual Alignment) to standardize how future models should be evaluated.
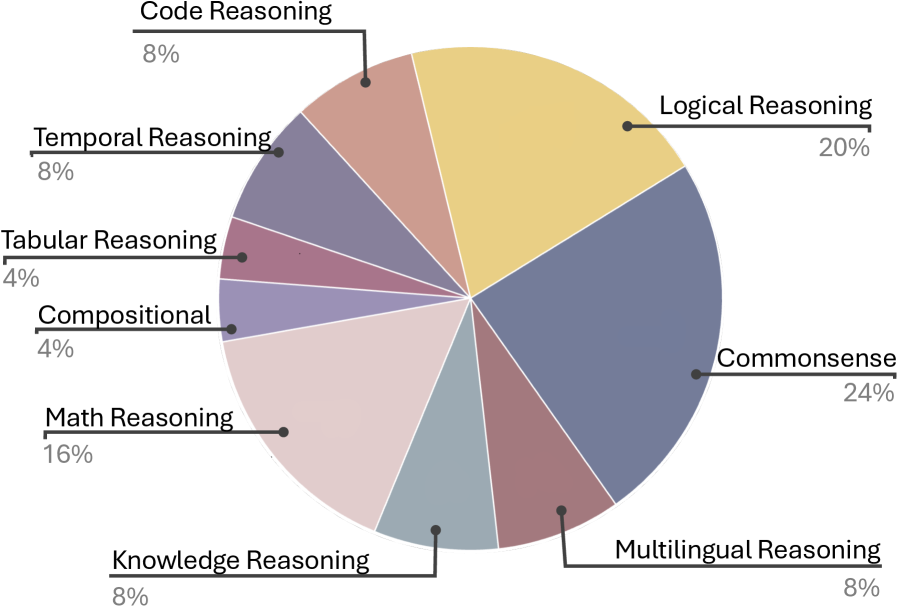
- Analyzes the landscape of benchmarks to reveal severe gaps: 54% of benchmarks focus on math/commonsense, while science and ethics are underrepresented and finance/healthcare are virtually absent.
Architecture
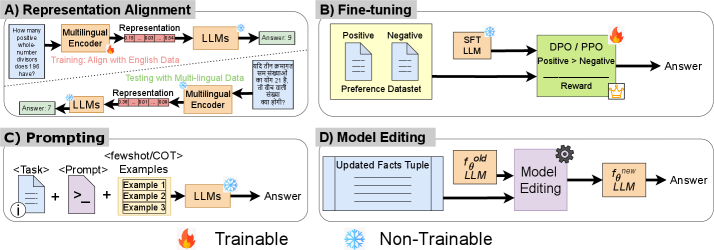
Taxonomy of Multilingual Reasoning Methods
Evaluation Highlights
- Identifies that only 4 benchmarks (out of many surveyed) incorporate coding languages across multiple human languages, highlighting a gap in multilingual code reasoning.
- Reveals that finance and healthcare domains currently lack dedicated evaluation benchmarks for multilingual reasoning entirely.
- Shows that typologically distant languages like Kannada and Quechua are rarely included in standard benchmarks compared to high-resource languages like French and Spanish.
Breakthrough Assessment
8/10
A foundational survey that defines a fragmented field. While it doesn't propose a new model, its rigorous categorization and exposure of benchmark gaps will likely steer future research directions.