📝 Paper Summary
LLM Evaluation
Multimodal Reasoning Benchmarks
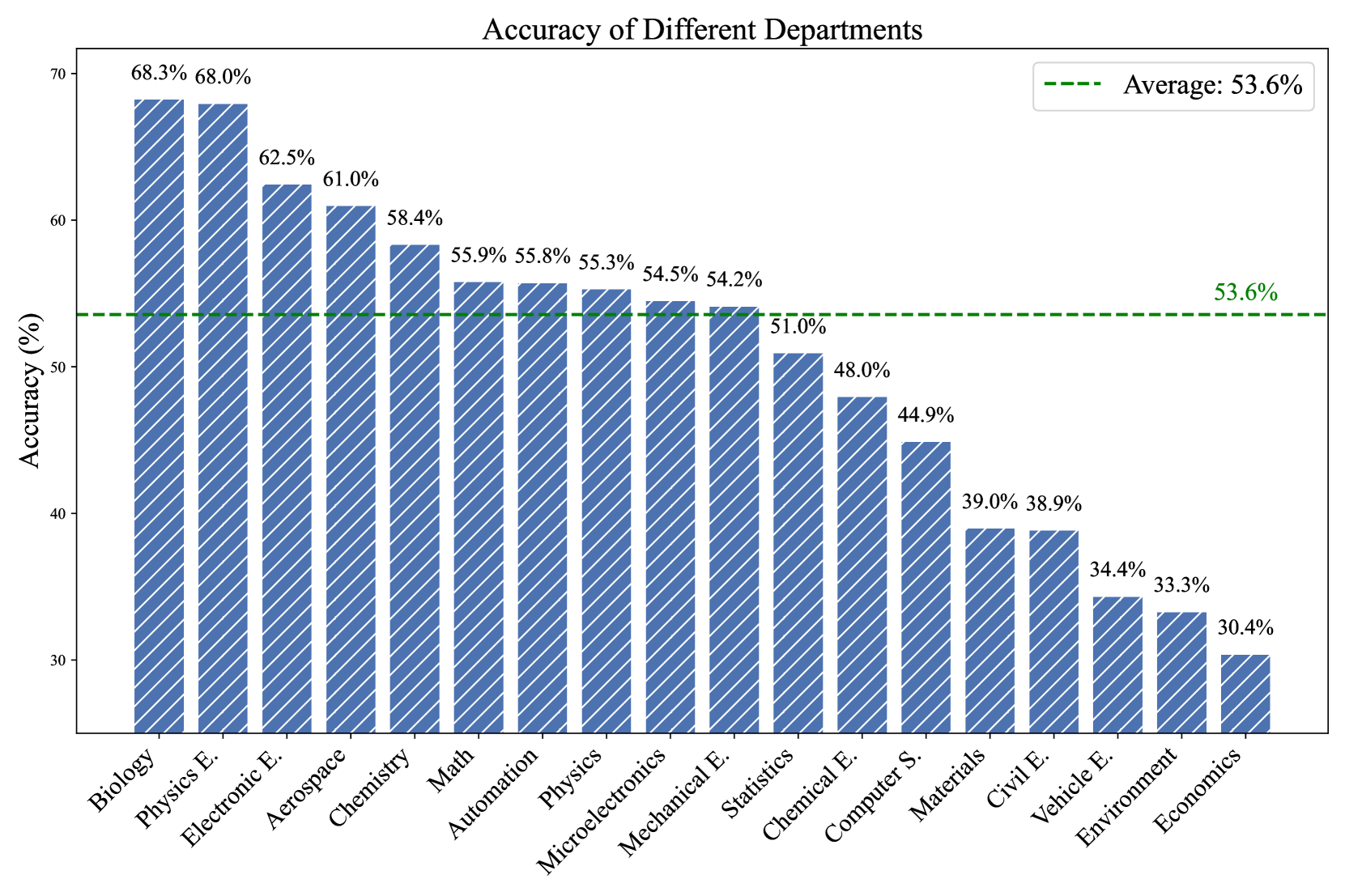
R-Bench is a rigorous, graduate-level benchmark for text and multimodal reasoning that reveals significant gaps in current SOTA models, particularly in multimodal contexts where even OpenAI o1 achieves only ~53% accuracy.
Core Problem
Existing reasoning benchmarks (like MMLU and MMMU) are becoming saturated by advanced models and fail to distinguish complex reasoning capabilities (System-II) from simple knowledge retrieval (System-I), often lacking rigorous difficulty calibration or multilingual balance.
Why it matters:
- Current benchmarks like MMLU are nearing saturation (o1 achieves 92.3%), limiting their utility for guiding future model improvements.
- Evaluating 'slow' deliberate reasoning requires different data than 'quick' intuitive thinking; most benchmarks conflate the two.
- Multimodal and multilingual reasoning are often tested separately, failing to assess if models have truly internalized reasoning skills across modalities and languages.
Concrete Example:
While OpenAI o1 achieves 92.3% on the undergraduate-level MMLU benchmark, it only scores 53.2% on the multimodal section of R-Bench, highlighting a massive gap between text-based knowledge retrieval and visual complex reasoning.
Key Novelty
ReasoningBench (R-Bench)
- Constructed from graduate-level exams and homework across 108 subjects at Tsinghua University, ensuring high difficulty and rigorous expert verification.
- Uses a novel 'Model-Screening' filter where questions are only included if the reasoning-specialized o1 model requires >2,000 reasoning tokens to solve them.
- Provides strict one-to-one English-Chinese translation for every question to test cross-lingual reasoning consistency rather than just language proficiency.
Architecture
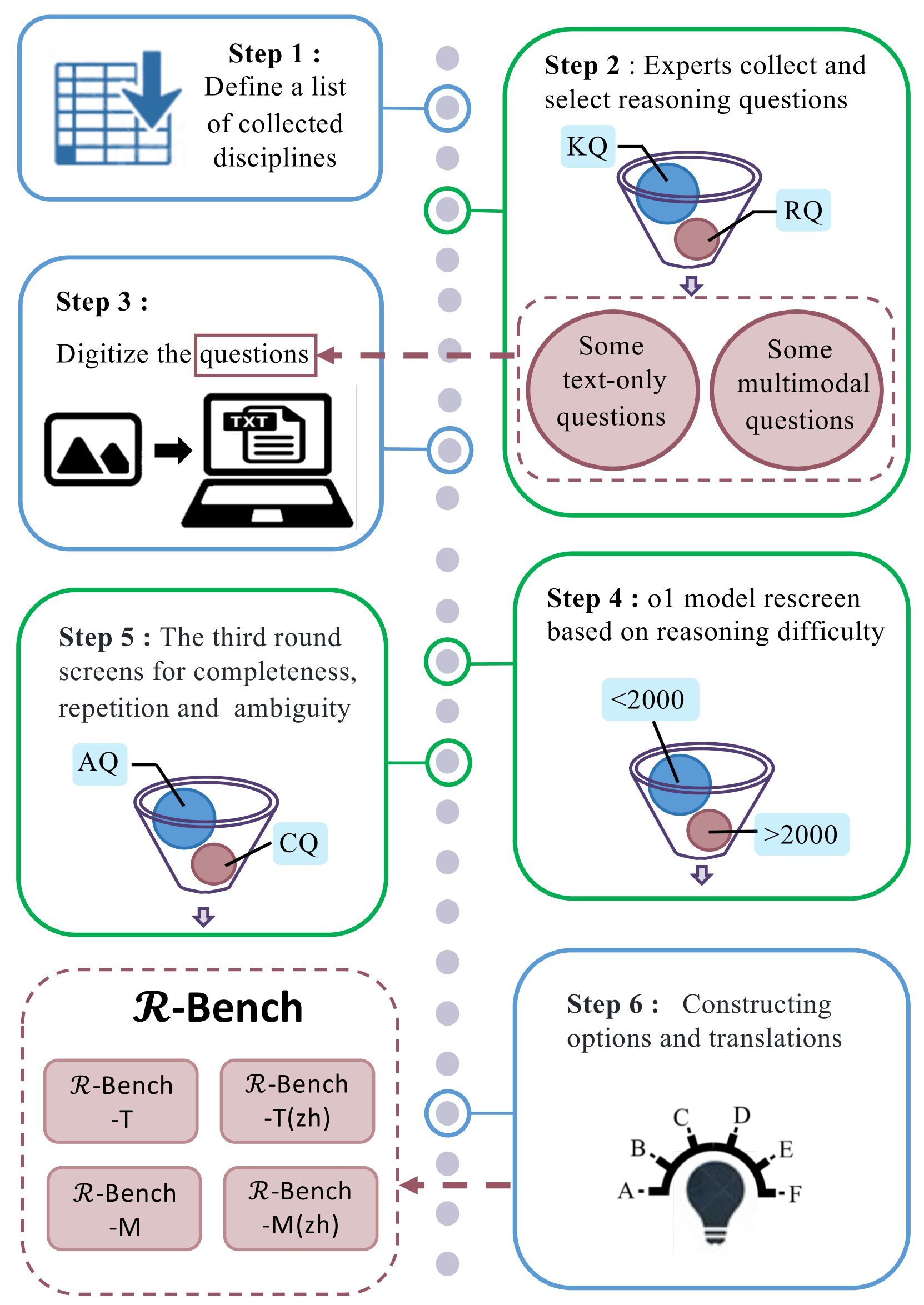
The 6-step construction pipeline of R-Bench, detailing how raw data is converted into the final benchmark.
Evaluation Highlights
- OpenAI o1 achieves 69.0% on text reasoning (R-Bench-T) but drops to 53.2% on multimodal reasoning (R-Bench-M), significantly outperforming GPT-4o.
- GPT-4o shows a massive performance gap between modalities, scoring 53.6% on text questions but only 33.7% on multimodal questions.
- Models demonstrate high cross-lingual consistency (>70% for most models), indicating they are learning underlying reasoning patterns rather than overfitting to specific languages.
Breakthrough Assessment
9/10
Establishes a new, much-needed standard for 'System-II' reasoning evaluation where current SOTA fails significantly. The rigorous construction pipeline (expert + o1-token filtering) sets a high bar for future benchmarks.