📝 Paper Summary
Synthetic Data Generation
Mathematical Reasoning
MathScale scales mathematical reasoning capabilities in LLMs by generating a massive synthetic dataset via a concept graph (extracted from seed questions) rather than simple augmentation, and introduces a comprehensive benchmark MwpBench.
Core Problem
Current mathematical instruction tuning relies on small datasets (like GSM8K/MATH) or limited augmentation methods (like rephrasing) that produce examples too similar to the original training set, restricting scalability.
Why it matters:
- LLMs struggle with multi-step complex reasoning required for math, lagging behind their general problem-solving skills
- Existing high-quality math datasets are tiny (e.g., GSM8K has only ~7.5K examples), limiting the effectiveness of fine-tuning
- Augmentation methods like WizardMath or MetaMath are bounded by the number of operations and generate repetitive data, failing to cover new concept combinations
Concrete Example:
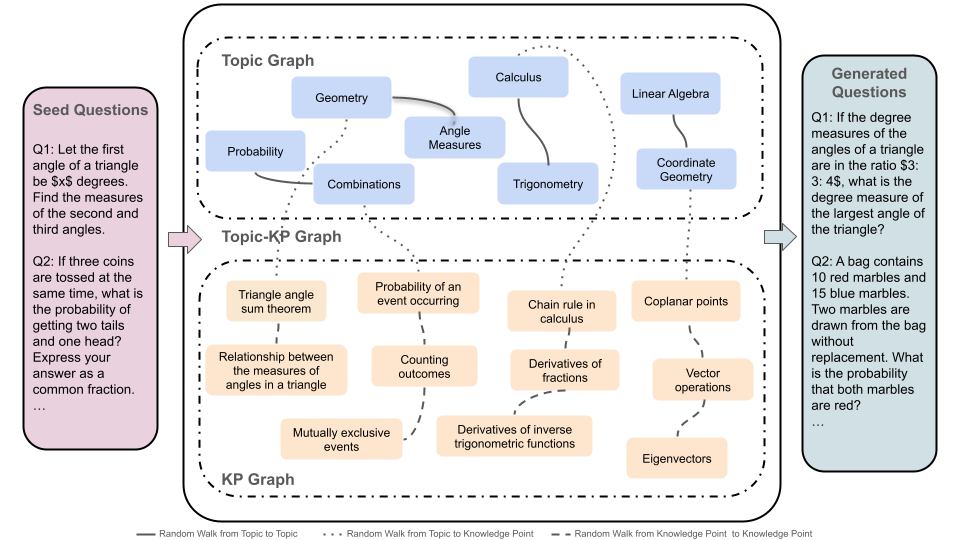
Augmentation methods might just change numbers or rephrase 'John has 5 apples' to 'John possesses 5 apples'. MathScale instead extracts 'Arithmetic' and 'Subtraction', then recombines them with 'Money' from a different problem to generate a fundamentally new question about buying items.
Key Novelty
MathScale (Concept-Graph-Based Generation)
- Extracts high-level 'topics' and 'knowledge points' from seed questions to build a concept graph, abstracting away the specific question text
- Simulates human 'connection forging' by performing random walks on this graph to create novel combinations of mathematical concepts
- Prompts GPT-3.5 to generate new questions based on these novel concept combinations, resulting in 2 million diverse QA pairs significantly different from the seed data
Architecture
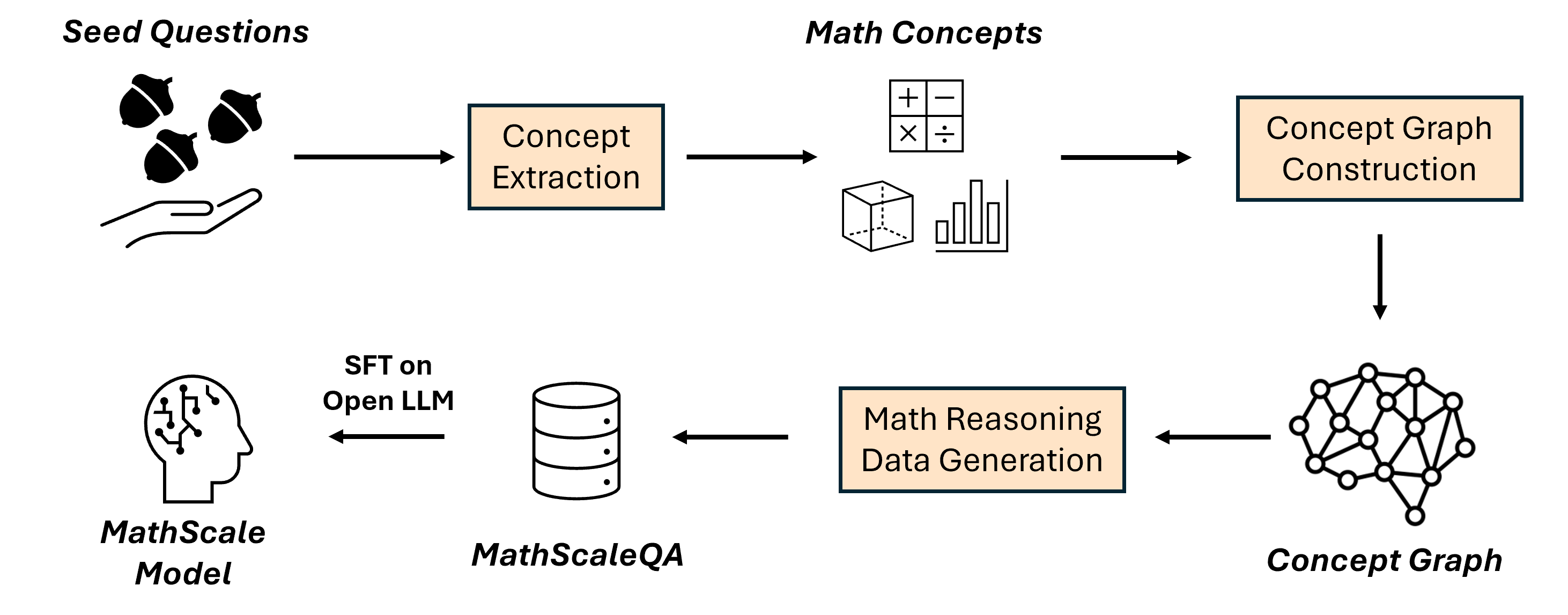
The MathScale data generation pipeline: from seed questions to concept extraction, graph construction, random walk sampling, and final question generation.
Evaluation Highlights
- MathScale-7B achieves 35.0% micro-average accuracy on MwpBench, outperforming the best equivalent-sized open-source peer (MetaMath-7B) by 42.9%
- MathScale-Mistral-7B reaches performance parity with GPT-3.5-Turbo on MwpBench micro and macro averages
- Achieves state-of-the-art performance across all 10 datasets in MwpBench compared to open-source models of equivalent size
Breakthrough Assessment
8/10
Strong methodological contribution in synthetic data generation (concept graph vs. simple rephrasing) leading to massive gains (+40% range) over strong baselines. Also contributes a significant consolidated benchmark.