📝 Paper Summary
Efficient Reasoning in LLMs
Adaptive Computation
Reinforcement Learning for Reasoning
AdaCtrl enables reasoning models to dynamically adjust their thinking time based on self-assessed problem difficulty and user-specified tags, balancing efficiency for simple tasks and depth for complex ones.
Core Problem
Large reasoning models (like o1 or DeepSeek R1) often "overthink" simple problems, wasting computation and increasing latency, while universal compression methods sacrifice performance on hard tasks.
Why it matters:
- Unnecessary long reasoning chains for trivial questions (e.g., log2(64)) degrade user experience due to high latency.
- Existing efficiency methods are either too rigid (universal shortening) or rely on fragile instruction-following without true difficulty awareness.
- Users lack explicit control over the trade-off between speed and reasoning depth in current reasoning models.
Concrete Example:
When asked a simple question like "Evaluate log2(64)", standard reasoning models might engage in lengthy planning and verification steps. AdaCtrl identifies this as an "[Easy]" problem and outputs a concise solution, saving tokens.
Key Novelty
Two-Stage Difficulty-Aware Training (AdaCtrl)
- Implements a cold-start fine-tuning phase using a mixed dataset of concise solutions for easy problems and long reasoning traces for hard ones, teaching the model to predict difficulty tags.
- Uses a difficulty-aware Reinforcement Learning (RL) framework where the model is rewarded for correctly estimating difficulty (calibration) and for adjusting response length dynamically based on that estimate.
Architecture
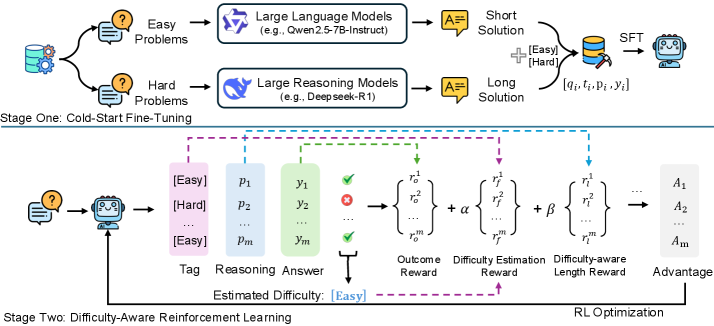
The overall training pipeline of AdaCtrl, illustrating the two stages: Cold-Start Fine-Tuning and Difficulty-Aware Reinforcement Learning.
Evaluation Highlights
- Reduces response length by 91.04% on GSM8K (easy dataset) while maintaining or improving accuracy (+2.05%) compared to standard RL baselines using Qwen2.5-7B.
- Achieves 10.41% accuracy improvement on the challenging AIME2024 dataset with Qwen2.5-14B while simultaneously reducing token usage by 18.20%.
- Outperforms standard RL baselines (SFT+RL) across four benchmarks (AIME24, AIME25, MATH500, GSM8K) in both accuracy and efficiency.
Breakthrough Assessment
8/10
Strong practical contribution addressing the 'overthinking' problem in reasoning models. The explicit user control via tags and the self-calibration reward mechanism are effective and well-motivated.