📝 Paper Summary
Reinforcement Learning for LLMs
Curriculum Learning
E2H Reasoner improves LLM reasoning by training on tasks probabilistically scheduled from easy to hard using a Gaussian distribution, preventing forgetting and overfitting while solving sparse reward problems.
Core Problem
Reinforcement learning for LLM reasoning fails on inherently hard tasks because the distribution gap between pre-training and target tasks causes sparse rewards, while standard curriculum learning suffers from forgetting previous tasks.
Why it matters:
- Models like DeepSeek-R1 rely on RL post-training but struggle with complex reasoning where zero-shot performance is low, as the model rarely sees a positive reward signal.
- Naive curricula (training easy then hard) lead to catastrophic forgetting, where the model loses the ability to solve simpler foundational problems necessary for complex generalization.
Concrete Example:
In a 6-number Countdown task (combine 6 numbers to reach a target), a model failing to perform basic arithmetic (a 2-number task) will never accidentally solve the hard task to receive a reward, leading to zero learning progress.
Key Novelty
E2H Reasoner (Easy-to-Hard with Gaussian Scheduling)
- Decomposes reasoning datasets into difficulty levels (Trivial, Easy, Medium, Hard) based on human labels or model error rates.
- Uses a probabilistic Gaussian scheduler that slides a 'window' of focus across difficulties over time. Unlike step functions, it maintains non-zero probability for easier tasks to prevent forgetting.
Architecture
Conceptual illustration of the Distribution Gap problem. It shows the Pre-training distribution (d0) and the Target Task distribution (dK) being far apart.
Evaluation Highlights
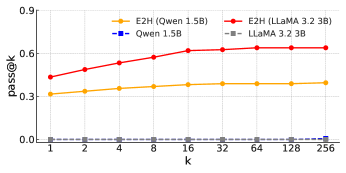
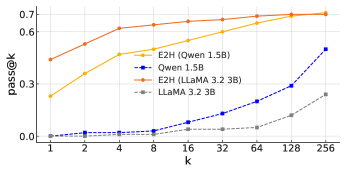
- Achieves state-of-the-art performance across five reasoning tasks: Blocksworld, Countdown, MATH, AQuA, and GSM8K (exact numbers not provided in source text).
- Demonstrates capability to learn tasks that initially had near-zero success rates in the zero-shot setting.
- Theoretical analysis proves that curriculum-based Approximate Policy Iteration requires fewer total samples than direct learning on the hardest task.
Breakthrough Assessment
7/10
Strong theoretical grounding (API analysis) combined with a practical probabilistic scheduler. Addresses the critical 'cold start' problem in RL for reasoning, though primarily an algorithmic refinement of curriculum learning.