📝 Paper Summary
Chain of Thought (CoT) Reasoning
Inference-Time Scaling
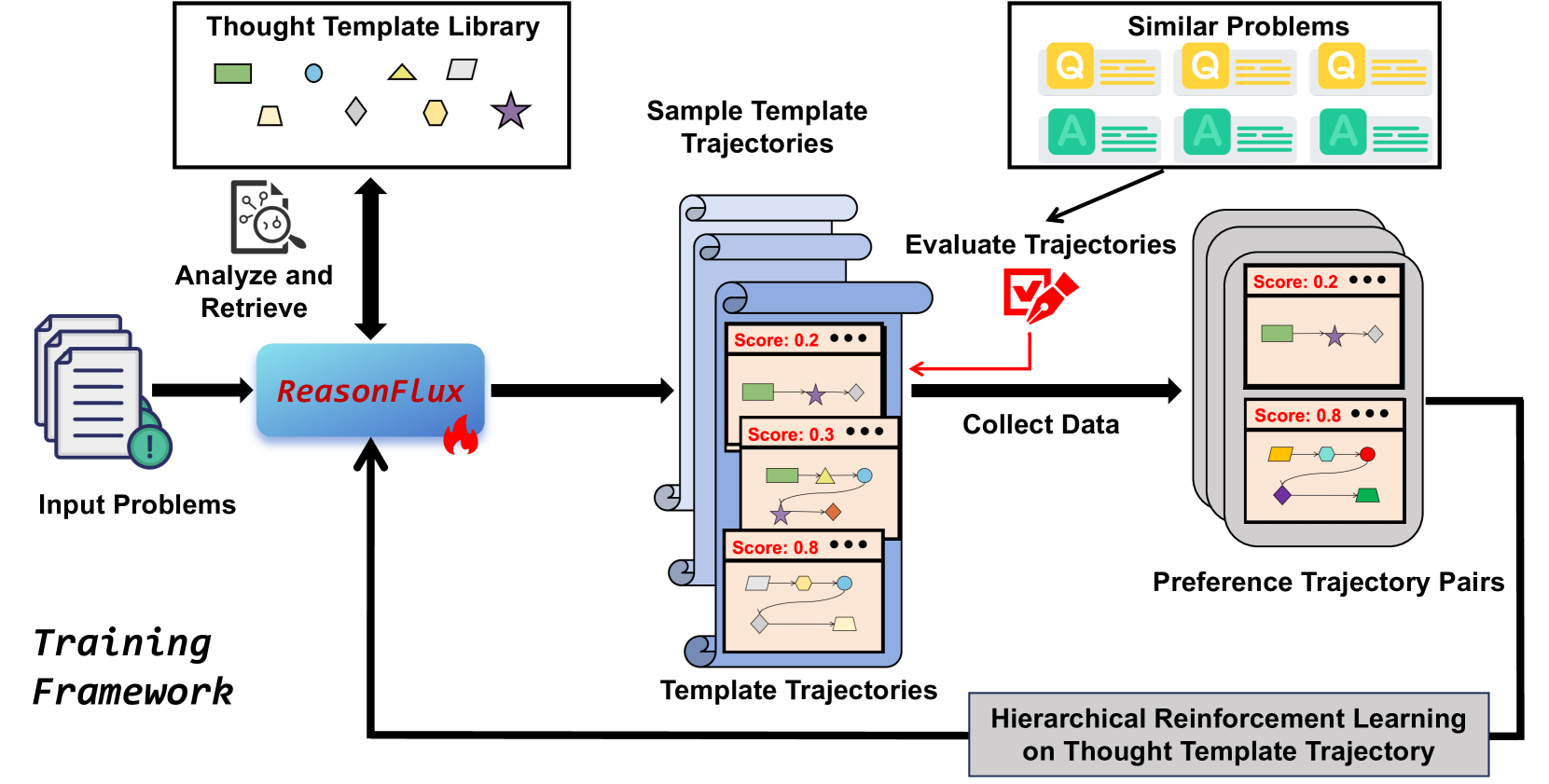
Hierarchical Reinforcement Learning
ReasonFlux enhances complex reasoning by retrieving high-level thought templates and optimizing a hierarchical trajectory of these templates via reinforcement learning, rather than just scaling raw token generation.
Core Problem
Current inference scaling methods (MCTS, best-of-N) are computationally expensive and struggle with exploration-exploitation balance in vast search spaces, while standard RAG lacks the structure to handle complex multi-step reasoning.
Why it matters:
- Complex math problems (e.g., AIME) require fine-grained search and delicate thought processes that standard LLMs often miss.
- Existing search methods like ToT or MCTS rely on manual design or instance-level rewards that limit generalization.
- Simply retrieving unstructured text via RAG is insufficient for complex logic integration.
Concrete Example:
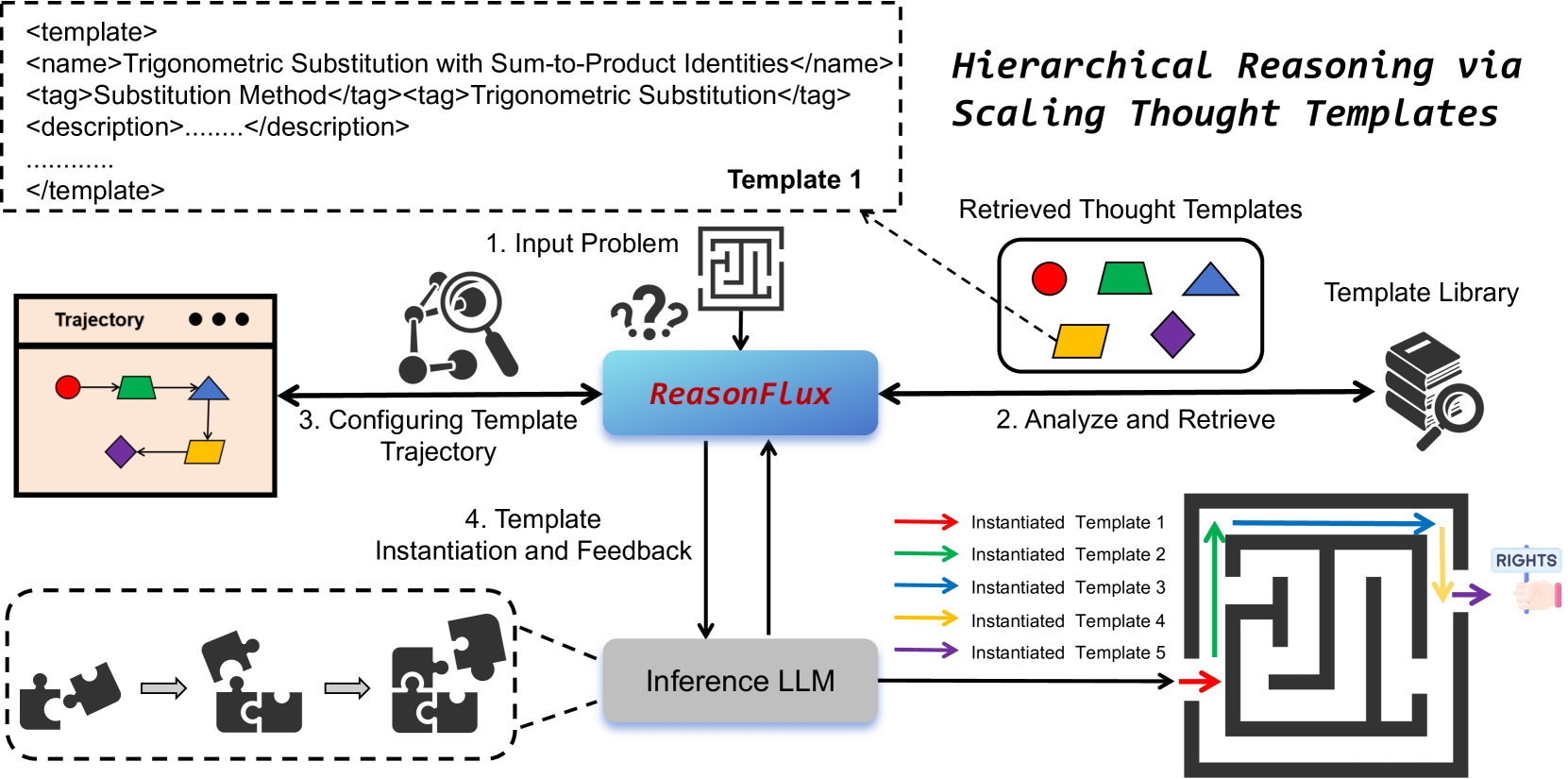
When solving a complex geometry problem, a standard LLM might hallucinate a formula or get stuck in a wrong path. ReasonFlux identifies the problem type (e.g., 'Trigonometric Substitution'), retrieves a specific high-level template structure for that type, and guides the LLM to fill in the specific numbers, ensuring a valid logical path.
Key Novelty
Hierarchical Template-Augmented Reasoning via RL
- Constructs a library of ~500 structured 'thought templates' (abstracted problem-solving patterns) rather than raw text.
- Uses Hierarchical Reinforcement Learning to train a 'navigator' model that plans a trajectory of templates, simplifying the reasoning search space.
- Dynamically retrieves and instantiates these templates at inference time, allowing the model to adaptively scale its thought process based on problem complexity.
Architecture
Overview of the ReasonFlux framework, illustrating the transition from problem input to template retrieval, trajectory planning, and final instantiation.
Evaluation Highlights
- Achieves 91.2% accuracy on the MATH benchmark, surpassing OpenAI o1-preview by 6.7%.
- Solves 56.7% of problems on the USA Math Olympiad (AIME), outperforming o1-preview (by 27%) and DeepSeek-V3 (by 45%).
- Demonstrates superior performance using only 32B parameters compared to larger proprietary models.
Breakthrough Assessment
9/10
Significant jump in performance on hardest math benchmarks (AIME) using a much smaller model (32B) by introducing a structured, retrieval-based hierarchical planning layer.