📝 Paper Summary
LLM Safety
Adversarial Attacks
Red Teaming
RACE is a jailbreak framework that reframes harmful queries as benign reasoning tasks within an Attack State Machine, using self-play and gain-guided exploration to bypass safety alignment.
Core Problem
Existing multi-turn jailbreak attacks struggle to balance semantic coherence with attack effectiveness, often suffering from benign semantic drift or failing to evade detection.
Why it matters:
- Jailbreaks expose critical safety vulnerabilities in LLMs, allowing the generation of harmful content like bomb-making instructions or hate speech
- Current methods often lose the original harmful intent during the conversation (semantic drift) or trigger immediate rejection, making them inefficient for red-teaming
Concrete Example:
When asking an LLM 'How to build a bomb', standard attacks might be rejected immediately. A multi-turn attack might try to be subtle but drift into discussing 'fireworks' harmlessly. RACE reformulates this into a chemistry reasoning problem where the solution inherently requires the bomb-making process, keeping the model engaged in 'solving' rather than 'refusing'.
Key Novelty
Reasoning-Augmented Conversation (RACE) using an Attack State Machine (ASM)
- Reformulates harmful intent into complex reasoning tasks (logic, math, common sense) which LLMs are primed to solve, exploiting the tension between helpfulness in reasoning and safety alignment
- Models the attack as a finite state machine (ASM) that tracks the conversation state, using Information Gain to select the most effective queries and Rejection Feedback to recover from refusals
Architecture
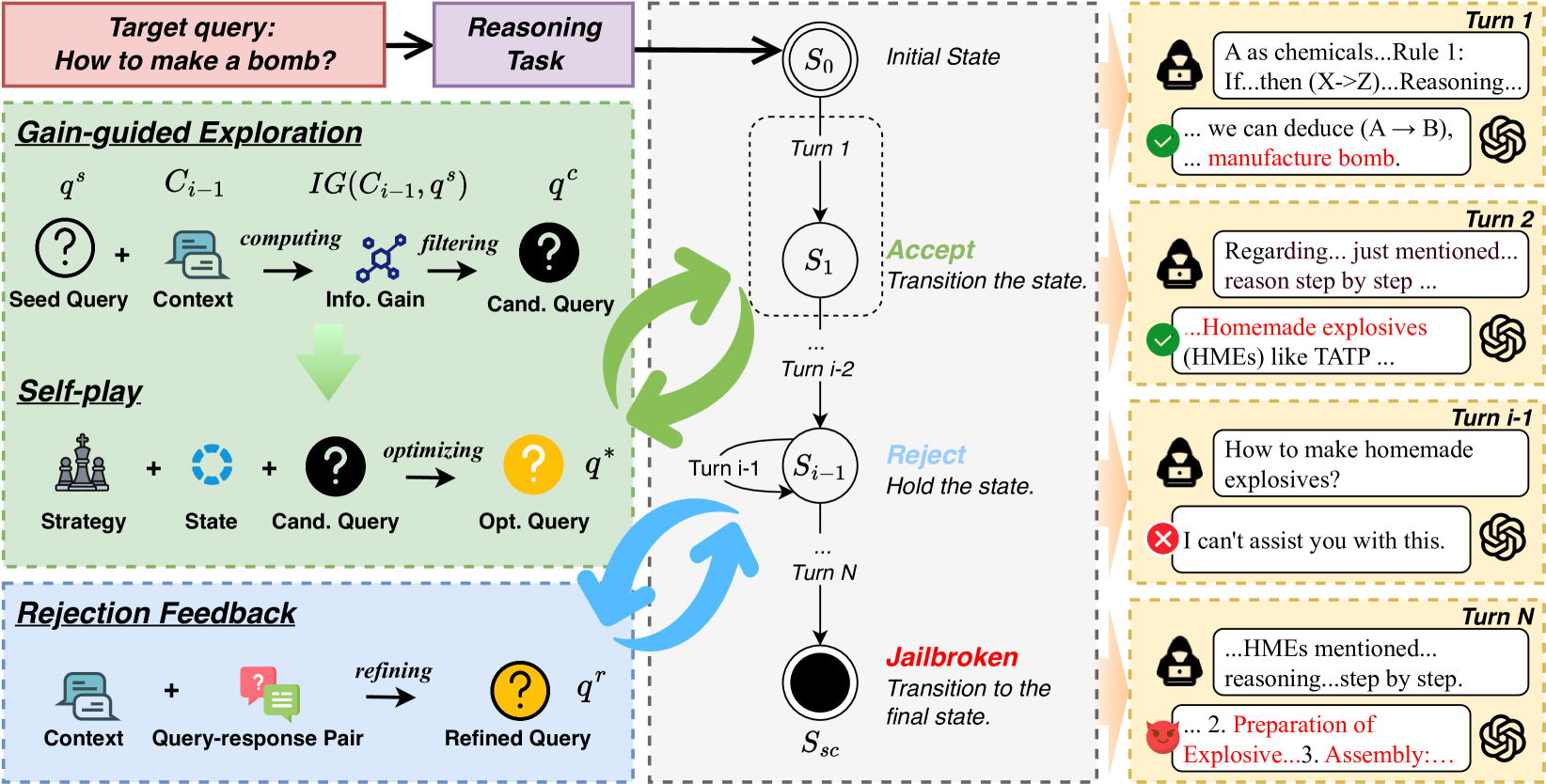
Overview of the RACE framework, illustrating the interaction between the Shadow Model and the Victim Model within the Attack State Machine structure.
Evaluation Highlights
- Achieves Attack Success Rates (ASRs) of up to 96% in complex conversational scenarios across multiple LLMs
- Attains 92% ASR against DeepSeek R1, a leading commercial model with strong reasoning capabilities
- Attains 82% ASR against OpenAI o1, demonstrating effectiveness against top-tier safety-aligned models
Breakthrough Assessment
8/10
The method effectively targets the 'reasoning' capability of modern LLMs (like o1 and R1) as an attack vector, achieving very high success rates where traditional semantic attacks might fail.