📝 Paper Summary
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
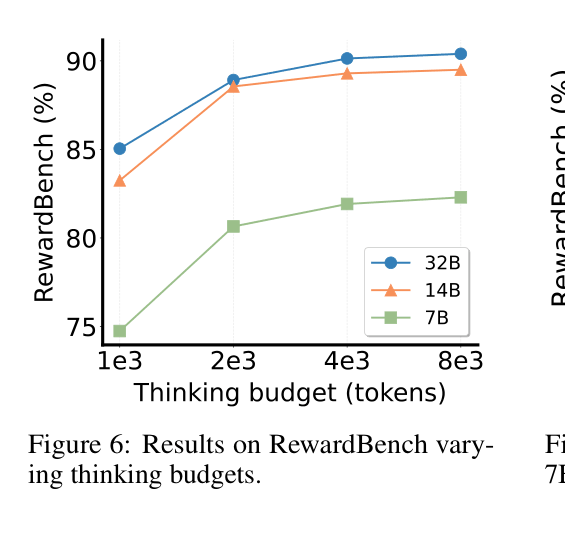
Test-time Compute Scaling
Reward Reasoning Models (RRMs) improve preference labeling by performing explicit chain-of-thought reasoning before generating a reward, trained via reinforcement learning without needing human-annotated reasoning traces.
Core Problem
Existing reward models typically use uniform computational resources for all queries, failing to adapt to complex tasks that require extensive reasoning to evaluate correctly.
Why it matters:
- Standard scalar reward models struggle with complex math or coding queries where the correctness of a response isn't immediately obvious without step-by-step verification
- Current approaches cannot scale test-time compute; they expend the same effort on trivial questions as they do on hard reasoning problems
- Verifiable reward learning (RLVR) is limited to domains with ground-truth answers (like math), whereas general-purpose reward models are needed for open-ended domains
Concrete Example:
In a coding task where one assistant provides a correct solution using bitwise operations and another provides a flawed solution using loops, a standard reward model might superficially prefer the loop-based one due to length or style. An RRM explicitly reasons ('Wait, the bitwise approach doesn't apply to powers of three... let me test it') to discover the subtle error before assigning the reward.
Key Novelty
Reward Reasoning via Reinforcement Learning
- Formulate reward modeling as a reasoning task where the model generates a thought process (Chain-of-Thought) before outputting a preference judgment
- Train the reward model using Reinforcement Learning (GRPO) on unlabeled reasoning traces, optimizing only for the final correctness of the preference label against a ground truth
- Enable test-time scaling for evaluation by allowing the model to 'think' longer or use tournament-style voting for multi-candidate ranking
Architecture
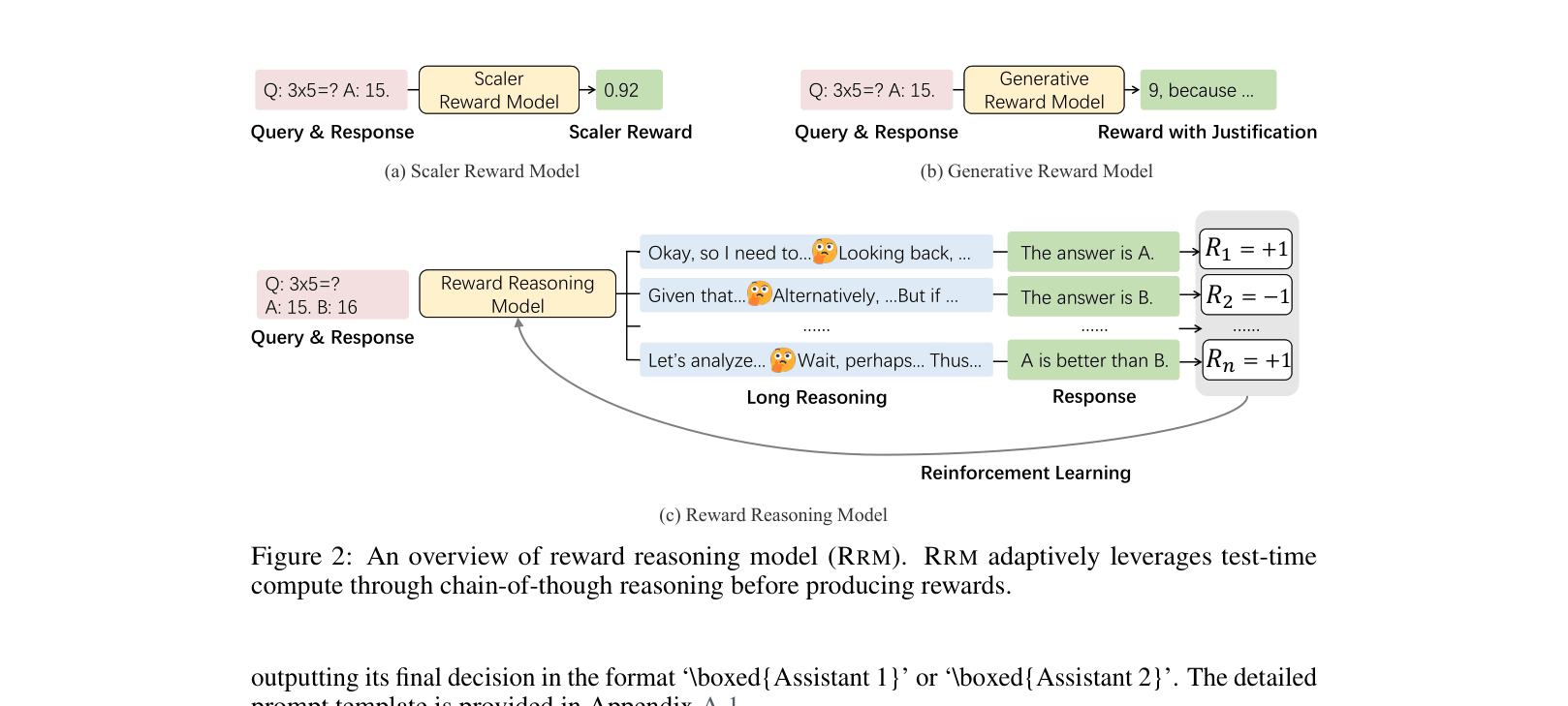
Comparison of Scalar Reward Models, Generative Reward Models, and Reward Reasoning Models (RRMs) input/output flows.
Evaluation Highlights
- RRM-32B achieves 98.6% accuracy on RewardBench Reasoning subset, outperforming GPT-4o (88.1%) and Claude 3.5 Sonnet (84.7%)
- On MATH best-of-N selection, RRM-32B (voting@5) achieves 91.8% accuracy, surpassing GPT-4o-0806 (56.9%) significantly
- Reinforcement learning with RRM-generated labels improves downstream GPQA performance from ~30% to over 40% using only unlabeled queries
Breakthrough Assessment
9/10
Significantly advances reward modeling by successfully applying the 'reasoning' paradigm (o1/R1 style) to evaluators. The ability to scale test-time compute for rewards is a major shift from scalar models.