📝 Paper Summary
Table-based Reasoning
Chain-of-Thought Reasoning
DATER improves table-based reasoning by using LLMs to prune huge tables into relevant sub-tables and decomposing complex questions into executable SQL queries to fill numerical gaps.
Core Problem
Large Language Models struggle with table-based reasoning because huge tables overflow context windows with irrelevant noise, and complex questions requiring multi-step symbolic operations often trigger hallucinations.
Why it matters:
- Directly encoding full tables is computationally intractable and distracts models with 'huge' irrelevant information (e.g., 30+ rows)
- Standard Chain-of-Thought prompting often fails at faithful symbolic operations (arithmetic, counting) on tabular data, leading to calculation errors
- Existing solutions usually require fine-tuning on large datasets, whereas in-context learning capabilities for tabular tasks remain under-explored
Concrete Example:
Question: 'Minnesota played at home more times than away.' A standard model might hallucinate the counts. DATER generates SQL ('SELECT COUNT(*) FROM w WHERE home=Minnesota'), executes it to get specific numbers ({6} and {8}), and fills them back into the reasoning chain.
Key Novelty
Decompose Evidence And Questions for Table-based Reasoning (DATER)
- Evidence Decomposition: Instead of feeding the whole table, the model predicts specific row and column indices to extract a small, relevant 'sub-evidence' table
- Parsing-Execution-Filling: Uses SQL as a bridge for logic. The model generates a query with numerical placeholders, executes SQL on the table to get exact values, and fills the placeholders to create a 'reliable sub-question'
Architecture
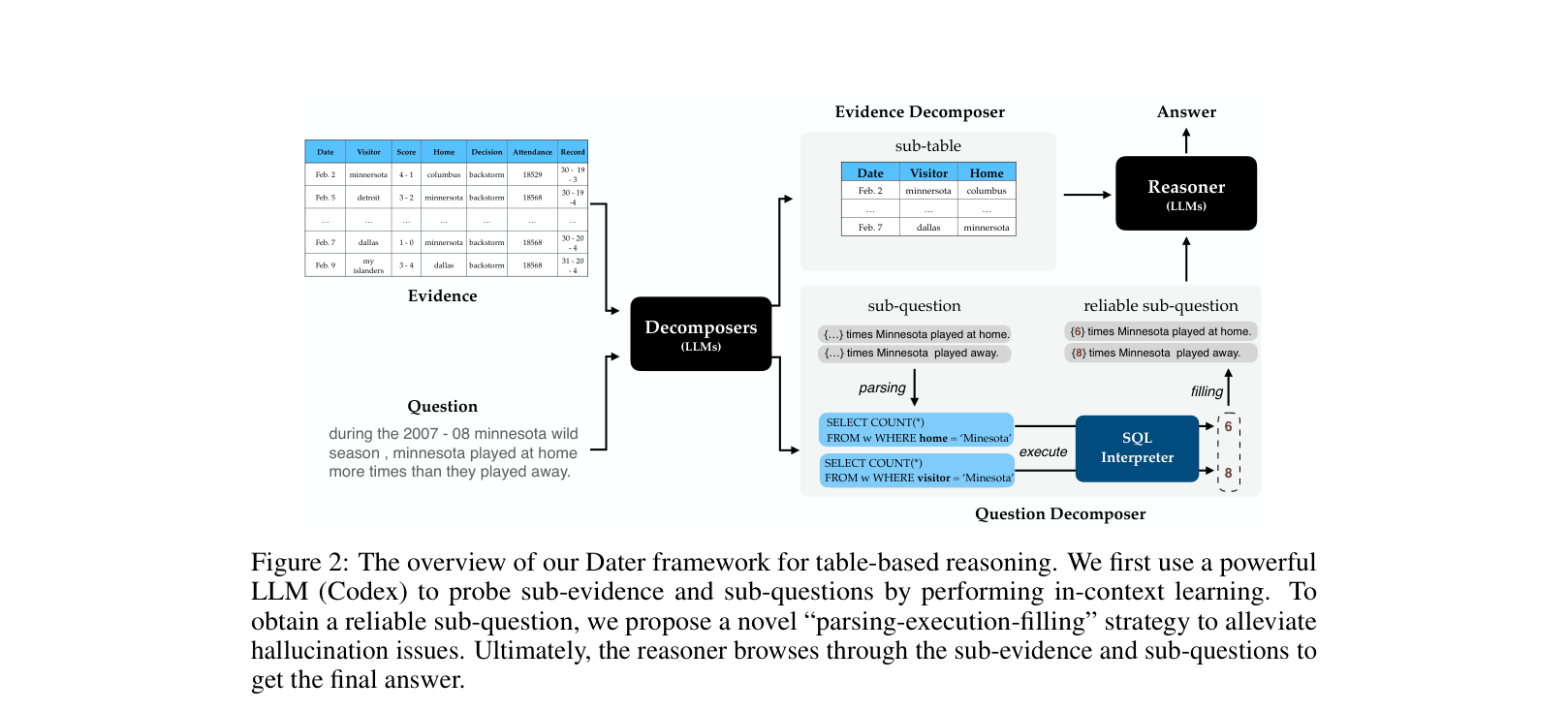
The overview of the DATER framework showing the two-stream decomposition process.
Evaluation Highlights
- Surpasses human performance (92.1%) on TabFact for the first time, achieving 93.0% accuracy when combined with the PASTA model
- Achieves state-of-the-art 65.9% accuracy on WikiTableQuestion, outperforming the Binder baseline by 4.0%
- Improves Codex performance on TabFact by +13.0% (85.6% vs 72.6%) purely through the DATER decomposition strategy without fine-tuning
Breakthrough Assessment
9/10
Achieving superhuman performance on TabFact and setting a new SOTA on WikiTableQuestion using a prompt-based decomposition strategy is a significant advancement in table reasoning.